AI추론
GPU가 토큰 하나 만들 때 연산 능력의 1%만 쓴다, Cerebras가 노리는 그 낭비
GPU 연산 능력의 99%가 토큰 생성 중 낭비된다는 역설에서 출발, Cerebras의 웨이퍼 스케일 칩이 메모리 병목을 어떻게 해결하는지와 현실적 한계를 분석합니다.
Written by

AI 추론이 둘로 나뉜다, Answer와 Agentic의 차이가 하드웨어를 바꾼다
AI 추론이 Answer와 Agentic으로 나뉘면서 GPU 중심 하드웨어 구조가 흔들리고 있습니다. Stratechery Ben Thompson의 분석을 소개합니다.
Written by

AI 모델이 자신 있을수록 더 위험하다, MIT가 찾아낸 과잉 확신의 구조적 원인
MIT CSAIL이 개발한 RLCR 훈련 방식. AI 추론 모델의 과잉 확신 문제를 훈련 구조 자체에서 해결하고, 교정 오류를 최대 90% 줄였습니다.
Written by

DeepSeek V4 출시, 1M 컨텍스트를 에이전트가 실제로 쓸 수 있게 만든 방법
DeepSeek V4가 1M 토큰 컨텍스트를 실용적으로 만든 방법. CSA·HCA 하이브리드 어텐션으로 KV 캐시를 90% 줄이고 에이전트 추론 흐름을 개선했습니다.
Written by

긴 컨텍스트 LLM의 숨겨진 함정, Context Rot 현상과 RLM 해결책
긴 컨텍스트를 처리할 때 LLM 성능이 저하되는 Context Rot 현상과, 이를 해결하는 RLM(Recursive Language Model) 접근법을 소개합니다.
Written by
유명 수학자 Joel Hamkins, LLM은 수학 연구에 ‘전혀 도움 안 돼’
노트르담 대학교 논리학 교수 Joel Hamkins가 LLM의 수학 연구 활용에 대해 ‘전혀 도움 안 돼’라고 직설적으로 평가. 벤치마크와 실용성 간극을 드러냅니다.
Written by
성능 5배·비용 1/10의 Vera Rubin: Nvidia가 AI 인프라 경쟁 끝내는 법
Nvidia가 CES 2026에서 발표한 Vera Rubin 플랫폼. 이전 세대 대비 성능 5배·비용 1/10 개선으로 AI 인프라 시장 판도를 바꿉니다.
Written by

구글 Gemini 3 Flash 출시: Pro급 성능을 3배 빠른 속도로, 무료 제공
구글이 Pro급 성능을 3배 빠른 속도로 제공하는 Gemini 3 Flash를 출시했습니다. 코딩 벤치마크 78% 달성, 무료 전방위 배포로 AI 대중화를 가속합니다.
Written by

엔비디아, 자율주행 AI에 ‘추론 능력’ 심었다: Alpamayo-R1 오픈소스 공개
엔비디아가 NeurIPS 2025에서 자율주행 연구를 위한 세계 최초 오픈소스 추론 VLA 모델 Alpamayo-R1을 공개했습니다. 사람처럼 판단하고 설명하는 AI의 새로운 가능성을 소개합니다.
Written by

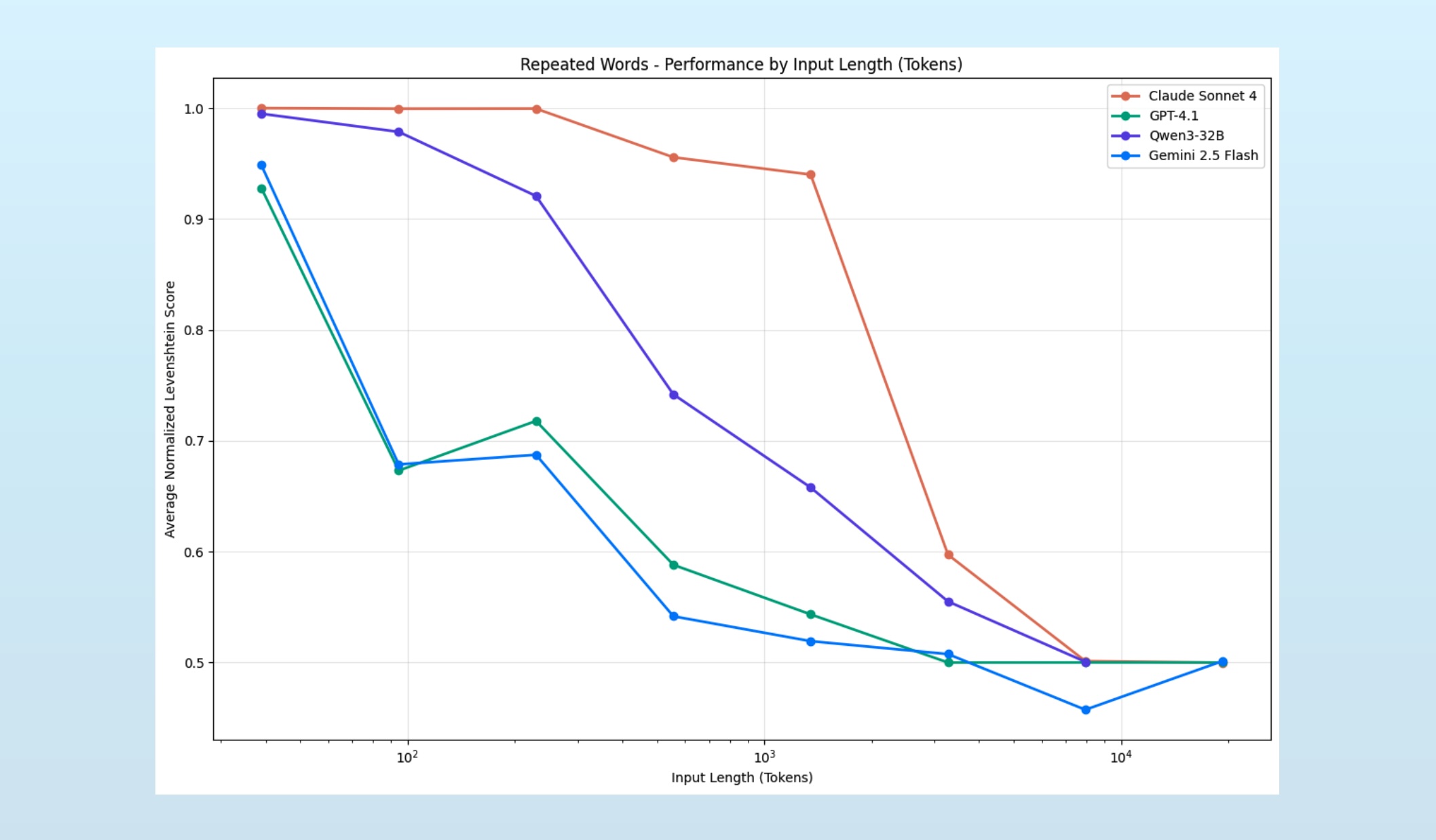
구글 AI가 200년 전 장부의 숫자 오류를 스스로 수정했다: Gemini의 추론 능력 발견
구글의 새 Gemini 모델이 18세기 장부를 전문가 수준으로 해독하고, 프롬프트 없이 스스로 논리적 추론을 수행했습니다. AI의 진짜 ‘이해’ 능력에 대한 새로운 증거를 소개합니다.
Written by