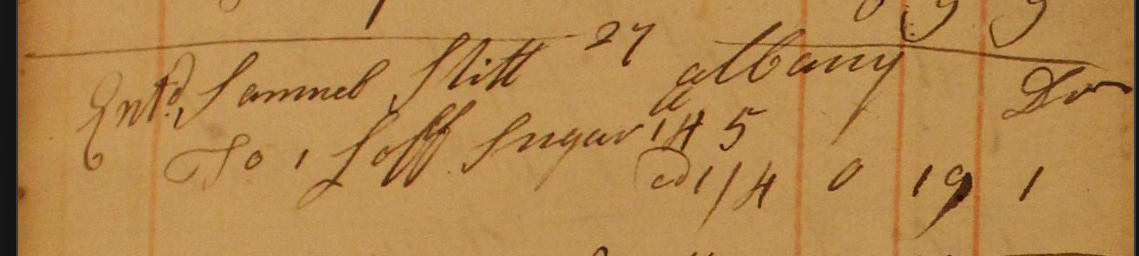
AI에게 손글씨 문서를 읽어달라고 했더니 글자만 읽은 게 아니라 숫자를 분석하고, 역산하고, 오류를 수정했습니다. 아무도 시키지 않았는데 말이죠.

역사학자 Ian Milligan이 구글의 새로운 Gemini 모델(아직 미공개, Gemini-3로 추정)을 테스트하던 중 놀라운 발견을 했습니다. 1758년 Albany 상인의 장부를 읽히자 모델이 단순히 글자를 옮겨 적는 수준을 넘어, 모호한 숫자를 해석하고 논리적으로 추론해 정확한 의미를 찾아냈다는 겁니다. AI가 ‘진짜 이해’를 하는지에 대한 오랜 논쟁에 새로운 증거를 제시하는 사례입니다.
출처: Has Google Quietly Solved Two of AI’s Oldest Problems? – Generative History Substack
전문가 수준의 손글씨 인식 달성
Milligan 교수는 지난 2년간 LLM의 손글씨 인식 능력을 추적해왔습니다. 그가 개발한 테스트셋은 18-19세기 영어 문서 50개, 약 1만 단어로 구성되어 있죠. 여러 필체, 다양한 촬영 조건, 철자 오류와 문법 오류가 가득한 실제 역사 자료들입니다.
새 Gemini 모델의 성능은 충격적이었습니다. 문자 오류율(CER) 0.56%, 단어 오류율(WER) 1.22%를 기록했는데, 이는 약 200자 중 1개만 틀린다는 의미입니다. 전문 필사 서비스가 보장하는 수준(CER 2-3%)을 뛰어넘는 정확도죠. 불과 2년 전 GPT-4가 거의 알아볼 수 없는 수준이었던 것을 생각하면 놀라운 발전입니다.
하지만 진짜 놀라운 건 다음에 일어났습니다.
설탕 한 덩어리의 미스터리
교수가 모델에게 18세기 상인 장부 페이지를 보여줬습니다. 네덜란드계 점원이 영어로 작성한 매출 기록이었는데, 필체가 지저분한 데다 철자도 들쭉날쭉했죠. 더 까다로운 건 당시 화폐 체계였습니다. 파운드/실링/펜스로 이루어진 비십진법 시스템이었거든요.
장부에는 이런 거래가 기록되어 있었습니다: “설탕 한 덩어리(loaf) 145 @1/4 0 19 1”
여기서 @1/4는 파운드당 1실링 4펜스, 0 19 1은 총액 0파운드 19실링 1펜스를 뜻합니다. 그런데 “145”는 뭘까요? 다른 항목들은 모두 “30갤런”, “17야드” 같은 단위가 명확한데 이것만 숫자만 덩그러니 있었습니다.
Gemini는 단순히 보이는 대로 옮겨 적지 않았습니다. 대신 “14 lb 5 oz”로 해석했죠. 프롬프트에는 “정확히 보이는 대로 옮겨 적으라”고만 했는데 말입니다.
AI가 수행한 추론의 단계들
Gemini가 한 일을 재구성해보면 이렇습니다:
먼저 “145”가 무게 단위라는 걸 추론했습니다. 장부의 다른 항목들을 보니 수량이 항상 맨 앞에 나오는데 이것만 뒤에 있었거든요. 또 파운드당 1실링 4펜스(=16펜스)에 팔렸다는 것도 파악했습니다.
그다음 역산을 시작했습니다. 총액 0파운드 19실링 1펜스를 펜스로 환산하면 229펜스입니다. 이걸 16으로 나누면 14.3125가 나오죠. 이는 14와 5/16, 즉 14파운드 5온스를 의미합니다.
결론: “145”는 “14 5″의 오기였고, 정확한 무게는 14파운드 5온스였다는 겁니다.
이 과정에는 여러 겹의 추론이 필요했습니다. 문맥 이해, 단위 추론, 두 개의 비십진법 체계(화폐와 무게) 간 변환, 역산을 통한 검증까지. 더 놀라운 건 아무도 이걸 하라고 시키지 않았다는 점입니다. 모델이 스스로 모호함을 발견하고, 조사하고, 해결했습니다.
다른 모델들은 어땠을까요? GPT-4o는 “1 Loaf Sugar 1 lb 5 0 19 1″로 옮겨 적었습니다. Gemini 2.5 Pro도 힌트를 줘도 제대로 해석하지 못했죠.
패턴 인식인가, 진짜 이해인가
이 사례가 중요한 이유는 LLM의 근본적인 한계에 대한 오랜 논쟁과 연결되기 때문입니다. 많은 전문가들은 현재 LLM이 패턴 매칭만 할 뿐 진짜 추론은 못한다고 주장해왔습니다. 상징적 추론(symbolic reasoning), 즉 명시적 규칙과 논리를 다루는 능력이 없다는 거죠.
하지만 Gemini는 정확히 그런 일을 한 것처럼 보입니다. 명시적으로 규칙을 정의한 적도 없고, 18세기 회계 시스템을 학습시킨 적도 없는데 말이죠. 내부적으로 어떻게 작동했는지는 모릅니다. 하지만 결과적으로는 맥락을 이해하고, 여러 단계의 논리적 추론을 수행하고, 올바른 답에 도달했습니다.
물론 한계는 있습니다. Milligan 교수는 이 결과를 수백 번 재현하려 했지만 A/B 테스트가 다시 나타나지 않았다고 합니다. 구글이 테스트를 중단했거나 샘플 크기가 너무 작았을 수 있죠. 체계적인 검증이 필요합니다.
손글씨 인식을 넘어서
손글씨 인식은 AI 연구의 가장 오래된 문제 중 하나입니다. 1966년 IBM 1287이 숫자와 다섯 개 알파벳을 읽을 수 있었던 것부터 시작해 수십 년간 시각 인식의 기술적 도전으로 여겨졌죠.
이번 발견이 시사하는 건 손글씨 인식이 단순한 시각 문제가 아니라는 겁니다. 진짜 어려운 건 마지막 10%—이름, 날짜, 숫자 같은 예측 불가능한 요소들을 정확히 읽는 것이었습니다. LLM은 본질적으로 확률 기반이라 “the cat sat on the mat”(고양이가 매트 위에 앉았다)는 예측할 수 있어도 “the cat sat on the rugg”(고양이가 러그 위에 앉았다, rugg는 rug의 오기)처럼 철자 오류가 있는 문장은 그대로 옮겨 적기 어렵거든요. 자꾸 올바른 철자인 “rug”로 고쳐버리는 경향이 있습니다.
새 Gemini 모델은 시각과 추론을 결합함으로써 이 문제를 돌파한 것으로 보입니다. 단순히 더 나은 시각 모델을 만든 게 아니라, 보이는 것을 해석하고 맥락 안에서 이해하는 범용 AI를 키운 거죠.
만약 이 능력이 일관되게 재현된다면, 역사 연구뿐 아니라 의료 기록, 법률 문서, 필기 노트 등 전문 지식과 시각적 정밀함이 함께 필요한 모든 분야에서 비슷한 도약이 일어날 수 있습니다. 그리고 그 핵심은 스케일과 다중모달 학습을 통해 추론 능력이 자연스럽게 창발한다는 가능성입니다.
“설탕 한 덩어리”의 사례는 작지만 명확한 신호입니다. 패턴 인식과 진짜 이해 사이의 경계가 흐려지기 시작했다는 신호 말이죠.
참고자료:
- Leddy & Milligan (2025). “Evaluating Handwritten Text Recognition in Historical Documents” – Taylor & Francis
- Royal Mint Museum: Pounds, Shillings and Pence – 18세기 영국 화폐 체계 설명
답글 남기기