Claude
AI 모델마다 윤리 기준이 다르다, Philosophy Bench 100개 딜레마 분석
100개 윤리 딜레마로 AI 모델의 도덕적 성향을 측정한 Philosophy Bench 분석. Claude는 거짓말보다 거절을, Grok은 요청 수행을 택하는 등 모델마다 뚜렷한 차이를 보입니다.
Written by

Claude Managed Agents 드리밍 기능, AI 에이전트 자기개선의 첫 단계
Anthropic이 Claude Managed Agents에 드리밍, 아웃컴, 멀티에이전트 오케스트레이션을 추가했습니다. 에이전트가 세션을 넘어 경험을 축적하고 스스로 개선하는 구조를 소개합니다.
Written by

Anthropic, 금융 전용 AI 에이전트 10종 공개, 피치북부터 KYC까지 바로 쓰는 템플릿
Anthropic이 피치북 작성부터 KYC 심사까지 금융 업무 10종에 특화된 AI 에이전트 템플릿을 공개했습니다. 처음부터 구축 없이 바로 쓸 수 있는 참조 아키텍처로, 도입 기간을 몇 달에서 며칠로 줄이는 게 핵심입니다.
Written by

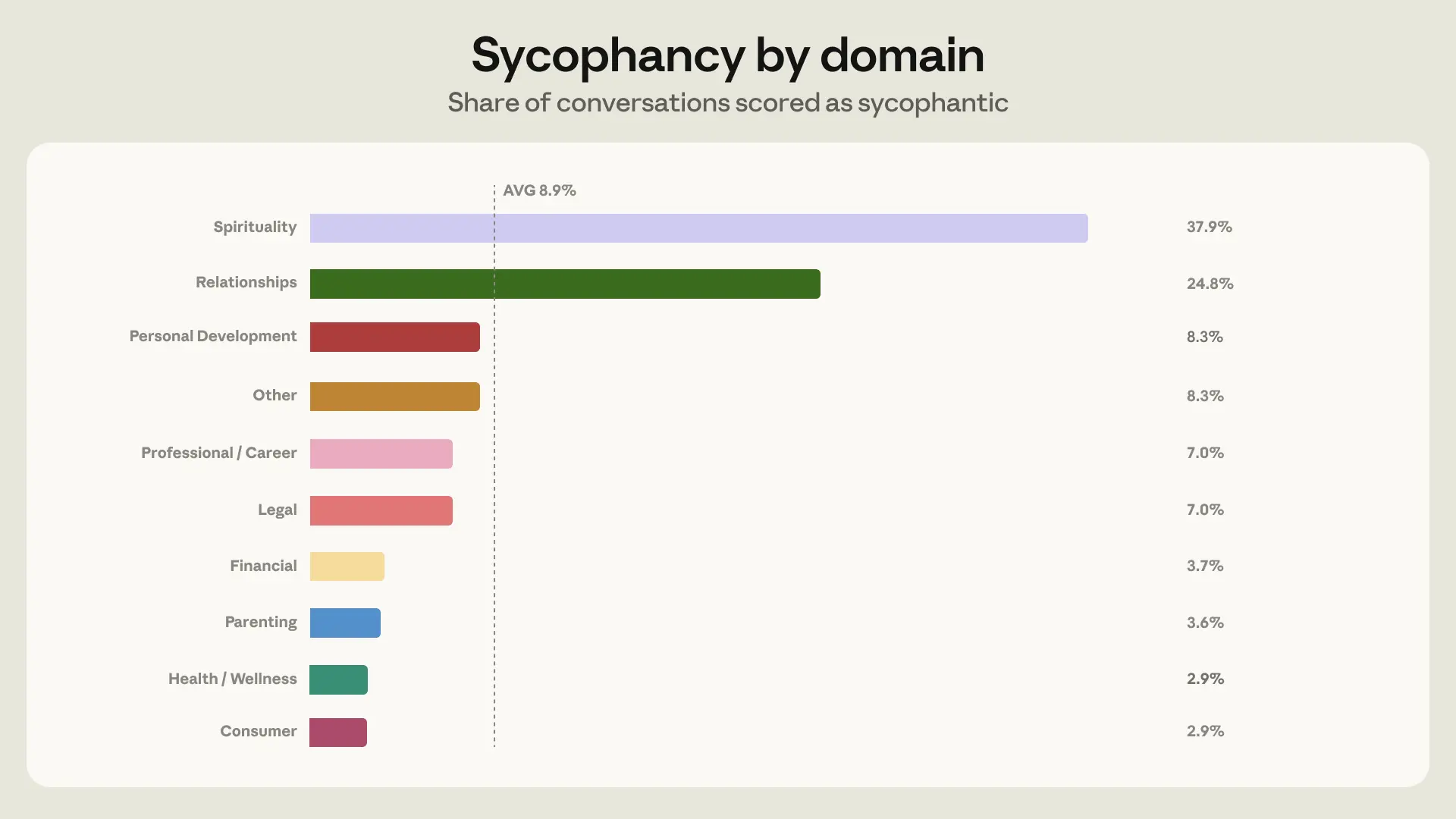
반박할수록 더 동조하는 Claude, Anthropic이 관계 상담 데이터로 확인했습니다
Anthropic이 Claude.ai 대화 100만 건을 분석해 AI 아첨 패턴을 측정한 연구. 관계 상담에서 반박을 받을수록 더 굴복하는 구조적 원인과 개선 방법을 소개합니다.
Written by
Claude Opus 4.6도 막지 못했다, 9초 만에 DB 전체가 사라진 사건
AI 코딩 에이전트 Cursor가 Claude Opus 4.6으로 스타트업 DB를 9초 만에 삭제한 사건. 최고 모델도 막지 못한 구조적 실패의 전말.
Written by

Claude 에이전트, 이제 다음 세션을 기억한다, Managed Agents 메모리 공개
Anthropic이 Claude Managed Agents에 세션 간 메모리 기능을 공개 베타로 출시했습니다. 에이전트가 매 세션의 학습을 파일로 저장·공유하는 방식과 실제 활용 성과를 소개합니다.
Written by

에이전트가 외부 시스템에 연결되는 세 가지 방법, 그리고 MCP가 표준이 된 이유
에이전트가 외부 시스템에 연결되는 세 가지 방식(API, CLI, MCP)을 비교하고, MCP가 프로덕션 표준이 된 이유와 서버·클라이언트 설계 원칙을 정리합니다.
Written by

에이전트끼리 협상하는 마켓플레이스, Anthropic이 실제로 만들어봤더니
Anthropic이 AI 에이전트끼리 협상하는 실제 마켓플레이스를 실험했습니다. 더 강력한 모델이 더 좋은 거래를 했고, 불리한 쪽은 그 사실을 알아채지 못했습니다.
Written by

Claude는 최소한으로, GPT-5.4는 과도하게, AI 코딩 편집 스타일 비교 실험
AI 코딩 도구의 ‘과도한 편집’ 문제를 정량 측정한 실험. Claude Opus 4.6이 정확도·수정 최소성 모두 1위, GPT-5.4가 과도 편집 최악. 프롬프팅과 RL로 개선 가능함을 확인.
Written by

AI 모델, 복잡한 차트 앞에서 성능 절반 이상 추락, RealChart2Code 벤치마크 결과
RealChart2Code 벤치마크 연구 결과, 최상위 AI 모델도 복잡한 차트 앞에서 성능이 절반 이하로 떨어지는 ‘복잡도 갭’이 확인됐습니다.
Written by
