huggingface
AI 에이전트가 도구를 직접 찾는다, ARD 명세가 바꾸는 것
Google·Microsoft·Hugging Face가 공동 발표한 ARD 명세. 에이전트가 런타임에 도구를 직접 검색해 찾는 발견 계층의 구조와 의미를 살펴봅니다.
Written by

소형 모델 5개로 경제 위기를 재현하다, Thousand Token Wood가 배운 것들
3B 파라미터 소형 모델 여러 개로 멀티 에이전트 경제 시뮬레이션을 구축한 실전 보고서. 포맷은 완벽한데 판단은 엉망인 소형 모델의 한계를 시스템 설계로 메운 방법을 소개합니다.
Written by

GGML·llama.cpp, Hugging Face 합류, 로컬 추론 오픈소스 단일화
llama.cpp 제작팀 GGML이 Hugging Face에 합류. transformers와 llama.cpp 통합 가속화로 로컬 AI 오픈소스 생태계의 큰 변화를 소개합니다.
Written by

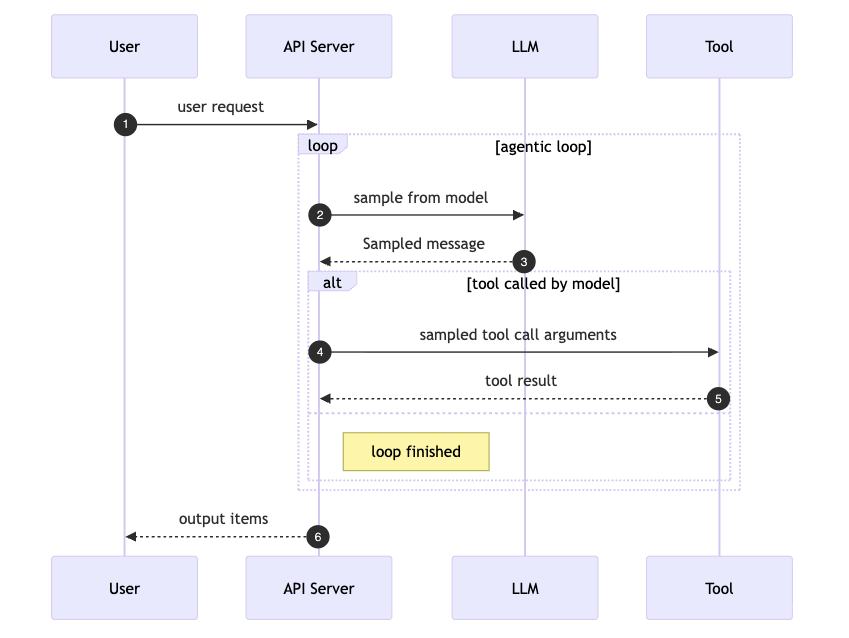
Chat Completion을 넘어, AI 에이전트 시대의 새 표준 Open Responses
Chat Completion을 넘어 AI 에이전트 시대를 위해 설계된 오픈 표준 Open Responses. Hugging Face와 주요 파트너들이 만드는 새로운 LLM API 표준을 소개합니다.
Written by
Claude가 LLM 파인튜닝을 알아서 한다: Hugging Face Skills
Claude에게 자연어로 지시하면 LLM 파인튜닝을 알아서 처리하는 Hugging Face Skills. 30센트부터 시작 가능한 AI 자동 학습 시스템을 소개합니다.
Written by

2025년 가장 많이 쓰인 AI 모델 TOP 10: HuggingFace 다운로드 순위
2025년 HuggingFace에서 가장 많이 다운로드된 오픈소스 AI 모델 TOP 10. 거대 모델 대신 효율적이고 실용적인 특화 모델들이 개발 현장을 주도하고 있습니다.
Written by

LangSmith 토큰 추적으로 LLM API 비용 50% 줄이는 방법
LLM API 비용을 50% 절감하는 토큰 추적 실전 가이드. LangSmith를 활용해 토큰 사용량을 시각화하고 병목 지점을 파악하는 단계별 방법을 소개합니다.
Written by

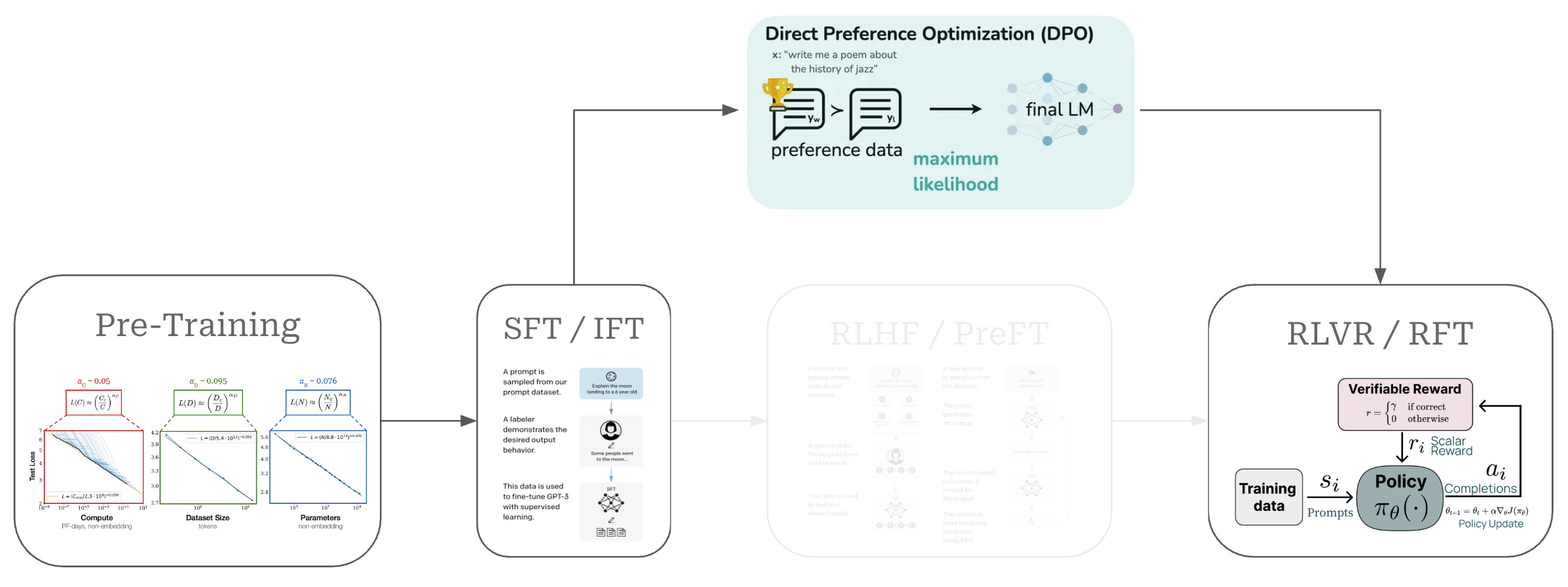
DPO: RLHF를 대체하는 혁신적인 LLM 정렬 기법 – 복잡성을 제거하고 효율성을 높이다
DPO(Direct Preference Optimization)는 기존 RLHF의 복잡성을 제거하면서도 동일한 성능을 달성하는 혁신적인 LLM 정렬 기법입니다. 별도의 보상 모델과 강화 학습 없이도 인간 선호도에 맞는 고품질 언어 모델을 훈련할 수 있어, AI 개발의 접근성을 크게 향상시켰습니다.
Written by
NVIDIA OpenReasoning-Nemotron: 작은 모델로 거대 AI의 추론 능력 구현하기
NVIDIA가 DeepSeek R1 모델로부터 지식 증류를 통해 개발한 OpenReasoning-Nemotron 시리즈를 소개합니다. 1.5B부터 32B까지 다양한 크기의 모델이 수학, 과학, 코딩 영역에서 최고 수준의 추론 성능을 달성하며, AI 추론 능력의 민주화에 기여하는 혁신적인 기술을 다룹니다.
Written by

FLUX.1 Kontext [dev]: 상용급 AI 이미지 편집을 무료로 – 설치부터 활용까지
Black Forest Labs의 FLUX.1 Kontext [dev] 오픈소스 AI 이미지 편집 모델 소개와 설치부터 실제 활용까지의 완전 가이드
Written by
