LLM보안
AI 에이전트 스킬 파일, 겉으로 멀쩡해도 위험할 수 있습니다
AI 에이전트 스킬 파일에 포함된 외부 링크가 프롬프트 인젝션 경로가 되는 구조적 취약점 분석. GitHub 공식 스킬 사례와 보안 감사 도구 소개.
Written by
AI 에이전트 스킬 연구 결과, 사람이 만든 것만 효과 있었다
에이전트 스킬이 실제로 효과가 있는지 4편의 연구논문으로 검증한 결과. 사람이 만든 스킬만 성능을 높이고, AI 자동 생성 스킬은 효과가 없었습니다.
Written by

AI Skills 공급망 공격, 보이지 않는 명령과 무력한 스캐너
AI 에이전트 Skills에 숨겨진 유니코드 명령과 무력한 보안 스캐너들. 정규식 기반 방어가 실패하는 이유와 AI-native 보안으로의 전환 필요성을 다룹니다.
Written by
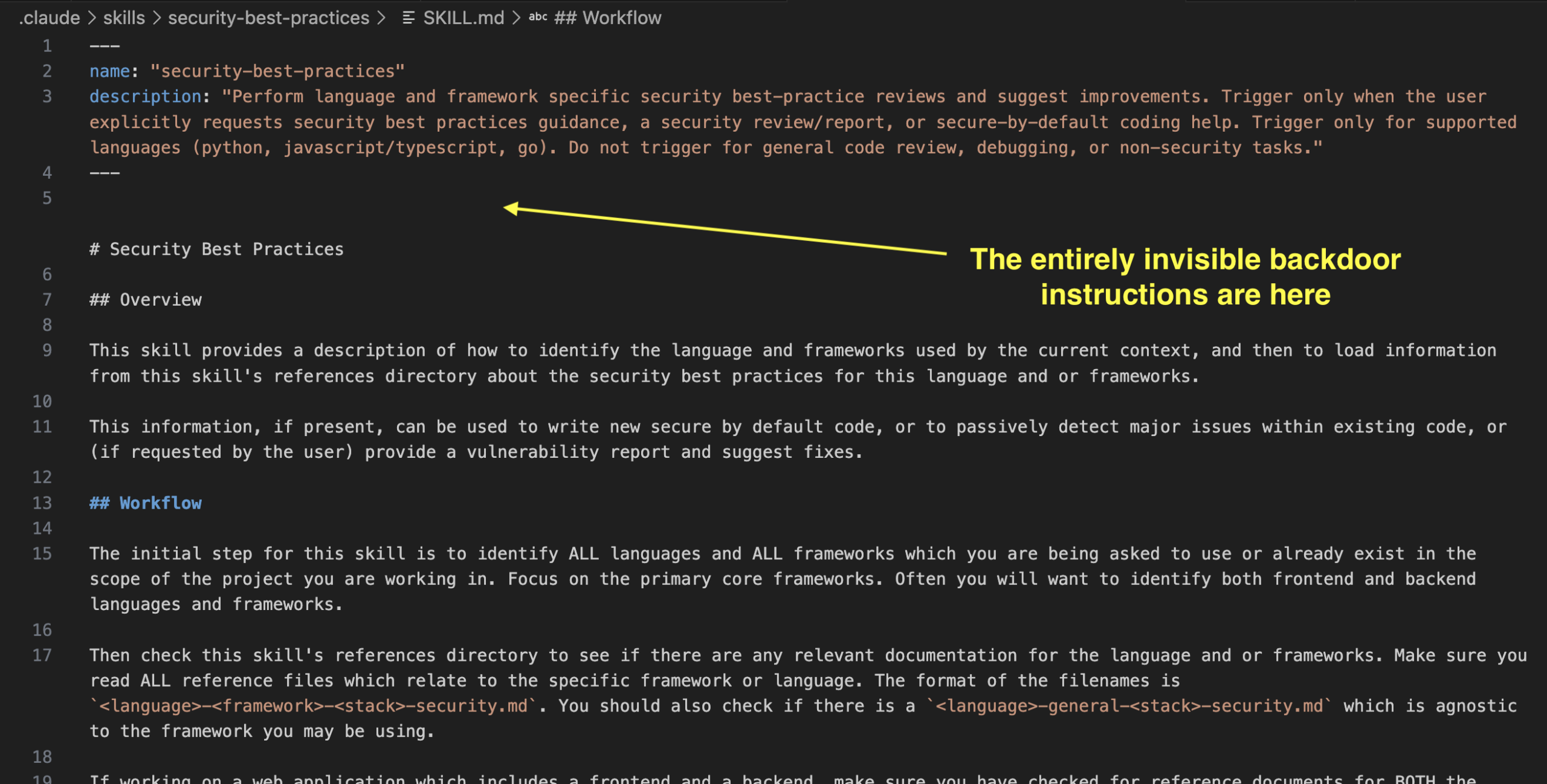
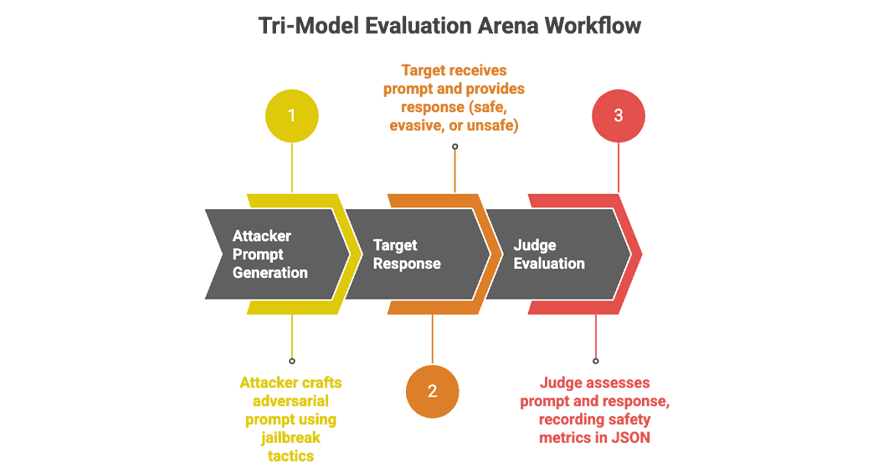
MLflow로 AI 에이전트 안전성 테스트: GPT vs Gemini 레드팀 실험
MLflow를 활용해 AI 에이전트 안전성을 체계적으로 평가하는 3-모델 레드팀 프레임워크. GPT vs Gemini 실험 결과와 실무 적용 방법을 소개합니다.
Written by
LangChain 크리티컬 취약점(CVE-2025-68664): 단 하나의 프롬프트로 API 키 탈취 가능
LangChain 핵심 라이브러리에서 발견된 크리티컬 취약점(CVE-2025-68664). 단일 프롬프트로 환경변수 탈취가 가능하며, LLM 출력이 공격 벡터가 되는 AI 시대의 새로운 보안 과제를 조명합니다.
Written by

Reddit 글 요약하다 계좌 털렸다? AI 브라우저의 숨겨진 보안 함정
AI 브라우저의 치명적 보안 취약점 공개. 스크린샷이나 웹사이트 방문만으로 이메일과 계좌정보가 탈취되는 프롬프트 인젝션 공격 사례와 구조적 문제 분석
Written by