
알리바바가 출시한 Qwen3-Next는 80억 개 파라미터 중 3억 개만 활성화하면서도 기존 32B 모델을 능가하는 성능을 보여주며 AI 모델 효율성의 새로운 기준을 제시하고 있습니다.
AI 모델이 점점 커지면서 비용과 효율성은 더욱 중요한 문제가 되었습니다. GPU 비용이 천정부지로 치솟고 있는 상황에서 알리바바가 내놓은 답이 바로 Qwen3-Next입니다. 이 모델은 80B 파라미터를 가지고 있지만 실제로는 3B 파라미터만 사용합니다. 그런데도 성능은 오히려 더 좋습니다.

3B로 80B를 이긴다는 게 가능한가요?
Qwen3-Next의 핵심은 하이브리드 아키텍처입니다. 기존의 어텐션 메커니즘을 완전히 바꿔서 두 가지 방식을 조합했습니다.
먼저 Gated DeltaNet이라는 기술을 사용합니다. 이건 마치 ‘빠른 독자’ 같은 역할을 합니다. 모든 단어를 처음부터 다시 읽는 대신 새로운 텍스트가 들어올 때마다 점진적으로 이해를 업데이트합니다. 모델의 약 75%가 이 방식으로 처리됩니다.
나머지 25%는 Gated Attention을 사용합니다. 이건 ‘꼼꼼한 검수자’ 역할로 단어 간의 관계를 자세히 분석합니다. 여기에 게이트라는 필터를 추가해서 노이즈를 걸러내고 정확성을 높입니다.
결과는 놀랍습니다. Qwen3-Next-80B-A3B는 Qwen3-32B보다 성능이 좋으면서도 훈련 비용은 10% 미만만 듭니다. 32K 토큰 이상의 긴 문맥에서는 처리 속도가 10배 이상 빨라집니다.
Qwen3 시리즈의 전체 라인업
Qwen3 시리즈는 다양한 크기의 모델을 제공합니다. 가장 작은 0.6B부터 가장 큰 235B까지 각자의 역할이 있습니다.
Dense 모델들:
- Qwen3-32B/14B/8B/4B/1.7B/0.6B
- 모든 파라미터가 활성화되는 전통적인 구조
MoE 모델들:
- Qwen3-235B-A22B: 235B 파라미터 중 22B만 활성화
- Qwen3-30B-A3B: 30B 파라미터 중 3B만 활성화
특히 작은 모델들의 성능이 인상적입니다. Qwen3-4B는 기존 Qwen2.5-72B-Instruct와 비슷한 성능을 보여줍니다. 18배나 작은 모델이 같은 일을 할 수 있다는 뜻입니다.

하이브리드 사고 모드의 혁신
Qwen3 시리즈의 또 다른 특징은 하이브리드 사고 모드입니다. 두 가지 방식으로 작동할 수 있습니다.
사고 모드(Thinking Mode): 복잡한 문제를 단계별로 차근차근 풀어냅니다. 시간이 좀 걸려도 정확한 답을 원할 때 사용합니다.
일반 모드(Non-Thinking Mode): 간단한 질문에 즉시 답변합니다. 속도가 중요한 상황에서 유용합니다.
사용자는 프롬프트에 /think나 /no_think을 추가해서 모드를 바꿀 수 있습니다. 멀티턴 대화에서도 턴마다 다른 모드를 사용할 수 있어서 상황에 맞는 최적의 성능을 얻을 수 있습니다.
NVIDIA 프레임워크로 실제 사용하기
이론은 좋은데 실제로 어떻게 사용할까요? NVIDIA에서 제공하는 여러 프레임워크를 활용할 수 있습니다.
TensorRT-LLM으로 성능 최적화
TensorRT-LLM을 사용하면 Qwen3-4B 모델에서 16배 이상의 처리량 향상을 얻을 수 있습니다.
# 벤치마크 데이터셋 준비
python3 /path/to/TensorRT-LLM/benchmarks/cpp/prepare_dataset.py \
--tokenizer=/path/to/Qwen3-4B \
--stdout token-norm-dist --num-requests=32768 \
--input-mean=1024 --output-mean=1024 \
--input-stdev=0 --output-stdev=0 > /path/to/dataset.txt
# 벤치마크 실행
trtllm-bench \
--model Qwen/Qwen3-4B \
--model_path /path/to/Qwen3-4B \
throughput \
--backend pytorch \
--max_batch_size 128 \
--max_num_tokens 16384 \
--dataset /path/to/dataset.txt \
--streaming다양한 배포 옵션들
Ollama로 간단 설치:
ollama run qwen3:4bSGLang으로 서버 구축:
pip install "sglang[all]"
python -m sglang.launch_server \
--model-path /path/to/model \
--trust-remote-code \
--device "cuda:0" \
--port 30000vLLM으로 고성능 서빙:
pip install vllm
vllm serve "Qwen/Qwen3-4B" \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.85 \
--max-num-seqs 256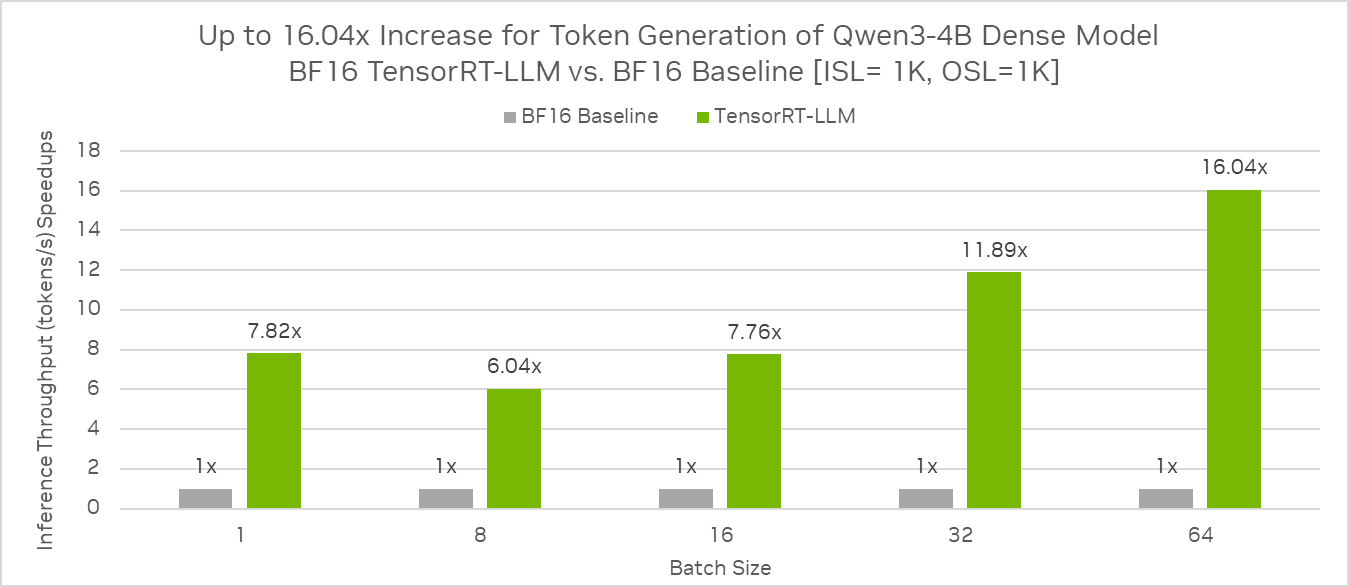
비용 효율성이 이렇게 중요한 이유
AI 모델 운영 비용은 기업들의 가장 큰 고민거리입니다. Qwen3-Next는 이 문제에 대한 현실적인 해답을 제시합니다.
Artificial Analysis의 독립적인 벤치마크에 따르면 Qwen3-Next-80B-A3B는 DeepSeek V3.1과 비슷한 지능 점수(54점)를 기록했습니다. 하지만 활성화되는 파라미터는 훨씬 적습니다.
가격 비교:
- 알리바바 클라우드에서 Qwen3-Next-80B-A3B: $0.5/$6 (입력/출력 100만 토큰당)
- 기존 Qwen3-235B 대비 25% 이상 저렴
특히 FP8 정밀도로 압축하면 단일 NVIDIA H200 GPU에서도 실행 가능합니다. 이는 거대한 컴퓨팅 클러스터 없이도 최신 AI 모델을 사용할 수 있다는 뜻입니다.
실제 활용 시나리오
스타트업과 중소기업: 제한된 예산으로도 최신 AI 기능을 도입할 수 있습니다. Qwen3-4B 정도만으로도 대부분의 업무를 처리할 수 있습니다.
대기업의 대규모 배포: MoE 아키텍처 덕분에 수천 명의 사용자가 동시에 접속해도 비용 증가폭이 적습니다.
연구기관: Apache 2.0 라이선스로 상업적 활용이 자유롭고 모델 가중치를 수정할 수 있어서 연구 목적으로 이상적입니다.
개발자들: Hugging Face Transformers, SGLang, vLLM 등 친숙한 도구들과 바로 연동됩니다. OpenAI API와 호환되는 엔드포인트를 제공해서 기존 코드 수정이 최소화됩니다.
Qwen3-Next가 제시하는 미래
Qwen3-Next는 단순히 새로운 모델이 아니라 AI 개발의 패러다임 변화를 보여줍니다. ‘더 크게’가 아니라 ‘더 똑똑하게’ 만드는 것이 핵심입니다.
하이브리드 아키텍처와 초희소 MoE 설계는 앞으로 다른 모델들도 따라할 가능성이 높습니다. 특히 256K 토큰의 긴 문맥을 네이티브로 지원하면서도 효율성을 잃지 않는다는 점은 주목할 만합니다.
알리바바 Qwen 팀은 이미 Qwen3.5 개발에 착수했다고 발표했습니다. 이 아키텍처를 기반으로 더욱 높은 성능과 생산성을 목표로 한다고 합니다. AI 효율성 전쟁은 이제 시작일 뿐입니다.
참고자료:
답글 남기기