GPT-5처럼 강력한 AI라도 긴 문서를 읽으면 집중력을 잃습니다. 272K 토큰이라는 넉넉한 컨텍스트 윈도우를 가졌지만, 실제로는 훨씬 짧은 길이에서도 성능이 뚝 떨어지죠. 이를 ‘context rot(컨텍스트 부패)’ 현상이라고 합니다. 그런데 MIT 연구팀이 이 한계를 정면으로 돌파하는 방법을 찾았습니다.

MIT CSAIL의 연구팀이 LLM의 컨텍스트 처리 능력을 획기적으로 확장하는 Recursive Language Models (RLMs)을 발표했습니다. 이 방법은 모델 컨텍스트 윈도우의 100배까지 처리 가능하며, 1,000만 토큰 이상의 입력도 효과적으로 다룹니다. 핵심 발견은 긴 프롬프트를 신경망에 직접 넣지 않고 외부 환경의 변수로 취급하면서, AI가 코드를 작성해 필요한 부분만 선택적으로 읽고 재귀적으로 자기 자신을 호출하도록 하는 것입니다.
출처: Recursive Language Models – arXiv
발상의 전환: 프롬프트를 환경으로
기존 접근법의 문제는 명확했습니다. 긴 프롬프트를 모델에 통째로 넣으면 context rot이 발생하고, 요약으로 압축하면 중요한 세부사항이 손실됩니다. RLM의 핵심 아이디어는 이렇습니다: 프롬프트를 Python REPL 환경의 변수로 저장하고, AI가 코드를 작성해서 필요한 부분만 들여다보게 하는 겁니다.
마치 사람이 두꺼운 책을 읽을 때 전체를 한 번에 외우려 하지 않고, 목차를 보고 필요한 챕터만 찾아 읽는 것과 비슷해요. RLM은 정규표현식으로 관련 섹션을 검색하고, 청크로 나누고, 각 청크에 대해 자기 자신(하위 LM)을 재귀적으로 호출해 분석합니다. 결과는 변수에 저장되고, 최종 답변은 이 변수들을 조합해서 만들어집니다.
예를 들어, 1,000개의 문서에서 특정 정보를 찾아야 한다면 RLM은 이렇게 작동합니다:
- 키워드로 관련 문서 필터링 (코드 실행)
- 발견된 각 문서에 대해 하위 LM 호출 (재귀)
- 하위 LM의 응답을 변수에 저장
- 저장된 정보를 종합해 최종 답변 생성
압도적인 성능, 합리적인 비용
연구팀은 GPT-5와 Qwen3-Coder-480B를 사용해 4가지 작업에서 RLM을 테스트했습니다. 결과는 놀라웠습니다.
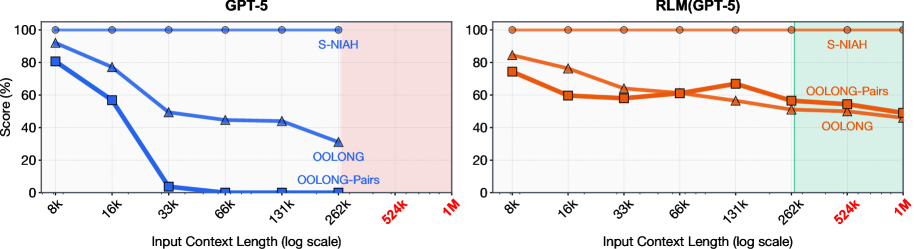
BrowseComp-Plus (1,000개 문서, 600만~1,100만 토큰)에서 RLM(GPT-5)은 96.67%의 정확도를 기록했습니다. 일반 GPT-5는 컨텍스트에 들어가지도 않았고, 요약 방식은 67.33%, 검색 도구 사용은 65.33%에 그쳤습니다. 더 흥미로운 건 비용이에요. RLM의 평균 비용은 $0.99로, 요약 방식($1.92)보다 저렴했습니다.
OOLONG이라는 정보 밀집형 작업에서는 차이가 더 극적이었습니다. 기본 GPT-5가 42.78% 정확도를 보인 반면, RLM(GPT-5)은 71.18%를 달성했죠. Qwen3-Coder로는 30.00%에서 63.26%로 두 배 이상 향상되었습니다.
가장 어려운 OOLONG-Pairs 작업에서는 기본 모델들이 거의 실패했습니다(F1 스코어 0.1% 미만). 하지만 RLM(GPT-5)은 58.00%의 F1 스코어를 기록했어요. 이 작업은 모든 데이터 쌍을 검토해야 하는 2차 복잡도 문제라 처리 비용이 입력 길이의 제곱에 비례합니다.
비용 측면에서 보면 RLM은 중앙값 기준으로는 기본 모델 호출보다 저렴하지만, 일부 복잡한 경우에는 비용이 크게 증가합니다. 연구팀이 측정한 결과, 50%의 케이스에서는 기본 모델보다 저렴했지만 상위 5%에서는 훨씬 비쌌습니다. 전략적으로 컨텍스트를 선택적으로 읽기 때문에 모든 입력을 읽는 요약 방식보다는 최대 3배 저렴했고요.
어떻게 작동하는지 들여다보기
연구팀은 RLM의 실제 작동 과정을 분석하며 흥미로운 패턴을 발견했습니다. 명시적인 훈련 없이도 RLM은 효율적인 전략을 스스로 개발했어요.
키워드 필터링: RLM은 전체 컨텍스트를 읽기 전에 정규표현식으로 관련 부분을 찾아냅니다. 예를 들어 축제에 관한 질문이라면 “festival”, “celebration” 같은 단어를 검색하고, 발견된 청크만 하위 LM에 전달하죠.
청크 분할과 재귀 호출: 긴 입력은 관리 가능한 크기로 나뉩니다. 흥미롭게도 GPT-5는 보수적으로 하위 호출을 사용하는 반면, Qwen3-Coder는 각 줄마다 하위 LM을 호출하는 경향이 있었습니다. 이는 프롬프트에 “너무 많은 하위 호출을 피하라”는 경고를 추가해야 했을 정도예요.
답변 검증: RLM은 답을 찾은 후에도 작은 컨텍스트로 하위 LM을 호출해 검증합니다. 하지만 때로는 지나치게 검증하느라 정확한 답을 버리고 틀린 답을 선택하는 경우도 있었습니다.
한계와 가능성
RLM은 강력하지만 완벽하지는 않습니다. 연구팀도 솔직하게 한계를 인정했어요.
첫째, 현재 구현은 동기식입니다. 모든 하위 LM 호출이 순차적으로 실행되기 때문에 느립니다. 비동기 처리로 개선하면 속도와 비용을 크게 줄일 수 있을 거예요.
둘째, 최적의 전략이 아닙니다. Qwen3-Coder 사례에서 봤듯이 모델이 이미 정답을 변수에 저장해놨는데도 계속 불필요한 검증을 반복하다가 오히려 틀린 답을 내놓기도 했습니다.
셋째, 짧은 입력에서는 기본 모델이 더 좋습니다. RLM은 구조상 기본 LM보다 복잡하기 때문에 작은 입력에서는 오버헤드가 성능 저하로 이어집니다.
하지만 가능성은 명확합니다. 연구팀은 RLM으로 작동하도록 명시적으로 훈련된 모델이 나온다면 훨씬 더 효율적일 거라고 전망합니다. RLM의 추론 과정을 일종의 사고 사슬(chain-of-thought)로 보고, 이를 학습 데이터로 활용하는 거죠. o1이나 DeepSeek-R1처럼 추론 과정을 학습한 모델의 성공을 보면 충분히 가능한 이야기입니다.
또한 RLM은 모델에 구애받지 않는 추론 전략이라는 점이 중요합니다. GPT-5든 오픈소스 모델이든 상관없이 적용 가능하고, 모델이 발전하면 RLM의 성능도 자동으로 향상됩니다.
긴 컨텍스트는 AI의 다음 전장입니다. 코드베이스 분석, 장기 프로젝트 관리, 대규모 문서 검색 같은 실무 작업은 모두 긴 컨텍스트 처리를 요구하죠. RLM은 모델 크기를 키우거나 아키텍처를 바꾸지 않고도 추론 시점의 계산만으로 이 문제를 해결할 수 있다는 걸 보여줬습니다. 생각의 전환이 하드웨어 업그레이드보다 더 강력할 수 있다는 증거입니다.
답글 남기기