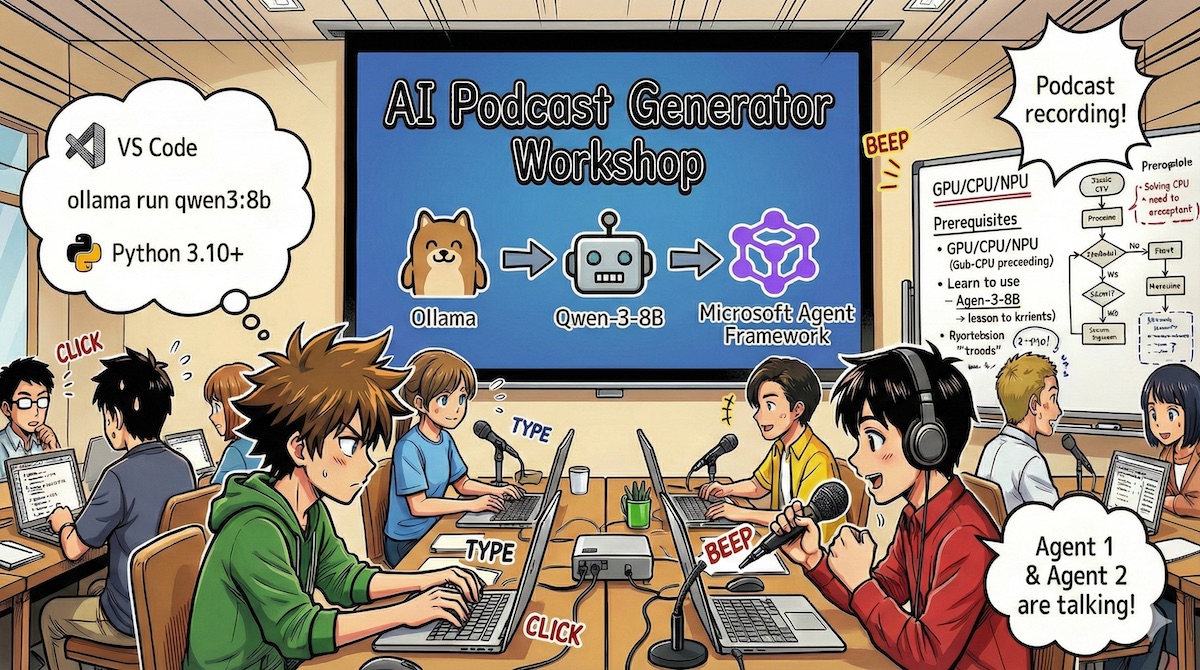
AI가 대본을 쓰고, 다른 AI가 그걸 검토하고, 또 다른 AI가 자연스러운 대화로 읽어주는 팟캐스트 스튜디오를 상상해보세요. 그것도 클라우드 API 없이 여러분의 컴퓨터에서요. Microsoft가 바로 그런 시스템을 공개했습니다.

Microsoft의 기술 에반젤리스트 kinfey가 공개한 이 프로젝트는 Microsoft Agent Framework를 활용해 여러 AI 에이전트가 협업하는 완전 자동화된 팟캐스트 제작 파이프라인입니다. 핵심은 모든 처리가 로컬에서 이뤄진다는 점이죠. Ollama를 통해 Qwen-3-8B 모델을 구동하고, VibeVoice로 자연스러운 대화 음성을 합성합니다.
출처: Engineering a Local-First Agentic Podcast Studio: A Deep Dive into Multi-Agent Orchestration – Microsoft Community Hub
왜 ‘로컬 우선’인가?
클라우드 LLM이 강력하긴 하지만, 창작 작업에는 마찰이 있습니다. 매 요청마다 네트워크 지연이 발생하고, API 비용이 누적되며, 민감한 콘텐츠는 외부 서버로 전송돼야 하죠. Microsoft는 이 문제를 정면으로 해결했습니다.
로컬 모델을 쓰면 토큰 생성이 즉각적이고, 한번 하드웨어에 투자하면 추가 비용이 없으며, 인터넷 없이도 작동합니다. 무엇보다 여러분의 아이디어와 초안이 절대 외부로 나가지 않습니다. 프라이버시가 보장되는 거죠.
에이전트들이 협업하는 방식
이 스튜디오의 핵심은 멀티 에이전트 오케스트레이션입니다. 각 에이전트는 전문 분야가 있고, 순차적으로 또는 병렬로 작업합니다.
검색 에이전트(SearchAgent)는 웹에서 최신 뉴스를 찾아옵니다. “AI 기술 트렌드”라는 주제를 주면 여러 소스를 동시에 검색해 정보를 수집하죠. 이게 첫 번째 단계입니다.
대본 작성 에이전트(GenerateScriptAgent)는 수집된 정보를 10분짜리 팟캐스트 대본으로 변환합니다. 두 명의 진행자(Lucy와 Ken)가 자연스럽게 주고받는 대화 형식으로요. 이 에이전트는 Chain-of-Thought 프롬프팅을 사용해 대본 구조를 먼저 ‘생각’한 후 작성합니다.
검토 에이전트(ReviewExecutor)는 생성된 대본을 평가합니다. 품질이 충분하지 않으면 대본 작성 에이전트에게 다시 보내 수정하게 하죠. 이 피드백 루프가 품질을 보장합니다.
최종적으로 승인된 대본은 VibeVoice로 전달됩니다. 이 기술은 Microsoft Research에서 개발한 대화형 음성 합성 시스템으로, 자연스러운 턴테이킹과 억양을 자동 처리합니다. 7.5Hz라는 초저 프레임 레이트로 작동해 컴퓨팅 자원을 크게 절약하면서도, 최대 4명의 목소리로 90분까지 생성할 수 있습니다.
실제 코드는 어떻게 생겼나?
Microsoft는 WorkshopForAgentic 프로젝트를 통해 전체 코드를 공개했습니다. 놀라울 정도로 간결합니다.
1단계: 로컬 모델 클라이언트 초기화
from agent_framework.ollama import OllamaChatClient
# Qwen-3-8B 모델 연결
chat_client = OllamaChatClient(
model_id="qwen3:8b",
endpoint="http://localhost:11434"
)로컬호스트 주소만 지정하면 끝입니다. Ollama가 백그라운드에서 모델을 관리하죠.
2단계: 전문 에이전트 정의
from agent_framework import ChatAgent
# 웹 검색 담당
researcher_agent = client.create_agent(
name="SearchAgent",
instructions="최신 뉴스를 검색엔진으로 찾아줘",
tools=[web_search]
)
# 대본 작성 담당
scriptwriter_agent = client.create_agent(
name="GenerateScriptAgent",
instructions="""
10분짜리 팟캐스트 대본을 만들어줘.
Lucy(진행자)와 Ken(전문가)의 대화 형식으로.
"""
)각 에이전트는 이름, 역할, 사용할 도구만 명시하면 됩니다. 검색 에이전트에게는 웹 검색 도구를, 대본 작성 에이전트에게는 대본 형식 지시를 줍니다.
3단계: 워크플로우 연결
from agent_framework import WorkflowBuilder
workflow = (
WorkflowBuilder()
.set_start_executor(search_executor)
.add_edge(search_executor, gen_script_executor)
.add_edge(gen_script_executor, review_executor)
.add_edge(review_executor, gen_script_executor) # 재작성 루프
.build()
)이 코드는 “검색 → 대본 작성 → 검토 → (필요시) 대본 재작성”의 순차 파이프라인을 만듭니다. 검토에서 통과하지 못하면 대본 작성으로 다시 루프를 돌죠.
워크플로우 패턴 비교
| 패턴 | 설명 | 사용 예시 |
|---|---|---|
| Sequential | 순차 실행 (A → B → C) | 대본 작성 후 검토 |
| Concurrent | 병렬 실행 (A, B 동시) | 여러 뉴스 소스 동시 검색 |
| Handoff | 동적 전달 | 작업 내용에 따라 전문가 선택 |
| Magentic-One | 매니저 주도 | 상황 판단 후 적절한 에이전트 배정 |
디버깅 도구: DevUI
Microsoft는 DevUI라는 웹 인터페이스를 제공합니다. 여기서 에이전트 간 메시지 흐름을 실시간으로 추적하고, 도구 호출을 확인할 수 있습니다. 프로젝트 구조만 만들면 DevUI가 자동으로 에이전트를 발견하고 테스트 인터페이스를 생성해줍니다.

필요한 시스템 사양
이 모든 걸 로컬에서 돌리려면 적절한 하드웨어가 필요합니다. 최소 16GB RAM이 필요하고, 32GB를 권장합니다. 여러 에이전트와 VibeVoice를 동시에 돌려야 하니까요. GPU나 NPU(NVIDIA RTX나 Snapdragon X Elite 같은)가 있으면 추론 속도가 크게 빨라집니다.
소프트웨어는 Python 3.10 이상, Ollama, Microsoft Agent Framework만 있으면 됩니다. 모두 오픈소스 또는 무료로 사용할 수 있습니다.
이게 왜 중요한가?
이 프로젝트는 AI의 새로운 패러다임을 보여줍니다. 하나의 거대한 모델에게 모든 걸 시키는 게 아니라, 전문화된 에이전트들이 협업하는 시스템이죠. 각자 잘하는 일만 하고, 워크플로우가 전체를 조율합니다.
로컬 우선 접근법도 주목할 만합니다. 클라우드 의존성을 줄이면 비용과 지연이 사라지고, 프라이버시가 보장됩니다. 특히 창작 작업처럼 반복이 많은 경우, 로컬 모델의 장점이 극대화됩니다.
물론 한계도 있습니다. 로컬 모델은 최신 클라우드 모델보다 성능이 떨어질 수 있고, 하드웨어 투자 비용이 필요하며, 기술 설정에 어느 정도 지식이 필요합니다. 또한 이 시스템은 팟캐스트라는 구조화된 콘텐츠에 최적화되어 있어, 다른 용도로는 추가 커스터마이징이 필요합니다.
하지만 방향성은 명확합니다. 개발자들이 코드를 ‘작성’하는 시대에서, AI 에이전트 생태계를 ‘연출’하는 시대로 넘어가고 있습니다. Microsoft가 공개한 이 프레임워크와 예제는, 그 전환을 직접 경험할 수 있는 실용적인 출발점입니다.
참고자료:
답글 남기기