Qwen
Qwen이 Opus급이라는 말의 진실, 직접 굴려본 창업자의 현실 보고서
1만 5천 달러 GPU로 로컬 Qwen을 1년 넘게 운영한 창업자의 실전 후기. 벤치마크 점수와 실제 신뢰도의 차이, 그리고 로컬 모델이 진짜 빛나는 용도를 짚습니다.
Written by

소형 모델 5개로 경제 위기를 재현하다, Thousand Token Wood가 배운 것들
3B 파라미터 소형 모델 여러 개로 멀티 에이전트 경제 시뮬레이션을 구축한 실전 보고서. 포맷은 완벽한데 판단은 엉망인 소형 모델의 한계를 시스템 설계로 메운 방법을 소개합니다.
Written by

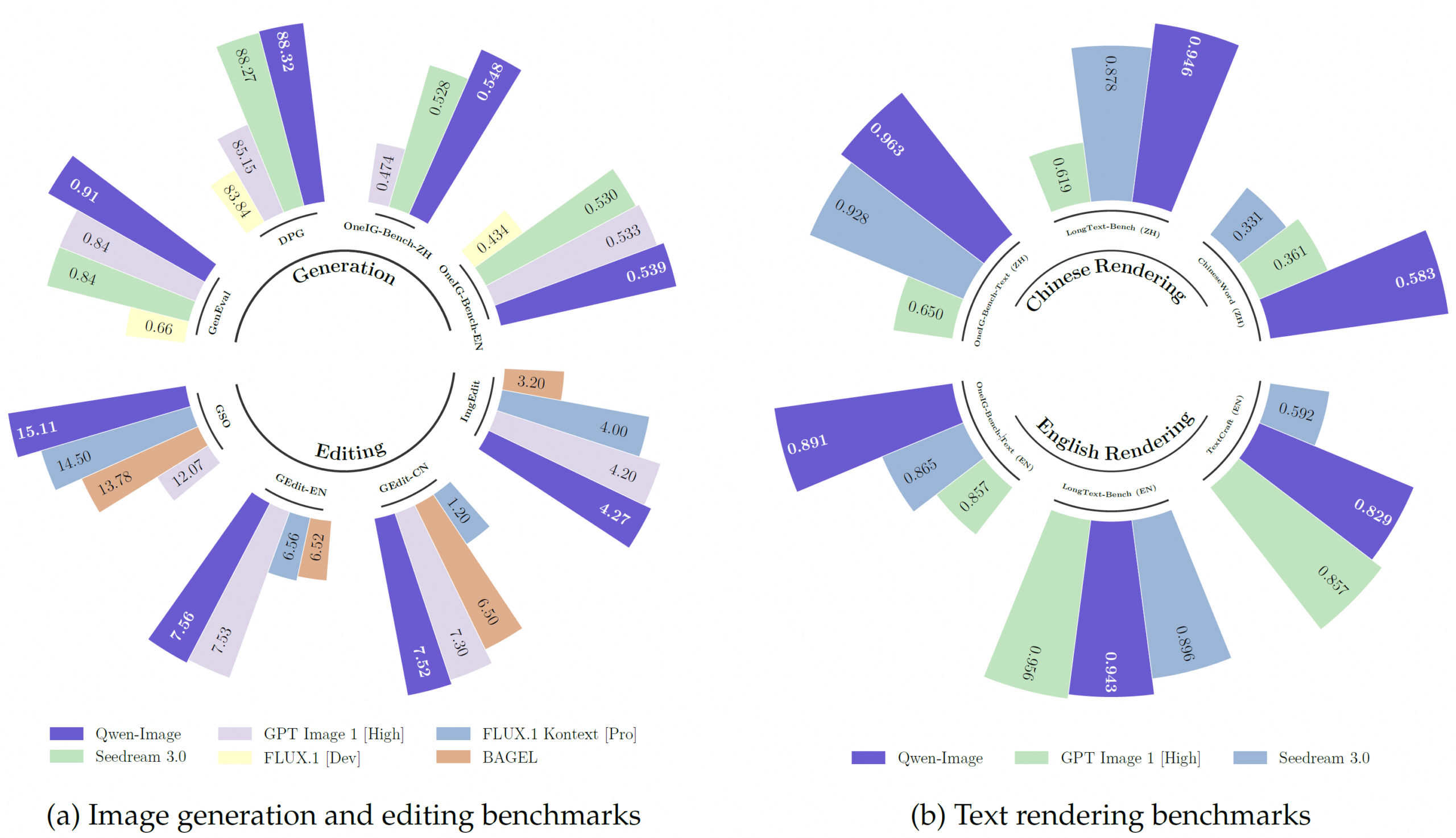
이미지 생성 단계 40→4로, Qwen Image 2.0의 압축과 증류 전략
알리바바 Qwen-Image-2.0 기술 분석. 파라미터는 20B→7B로 줄었는데 성능은 올랐습니다. VAE 압축률 2배 개선과 생성 단계 40→4로 줄인 증류 전략을 소개합니다.
Written by
오픈 웨이트 AI 모델, 무너지면 토큰 가격도 무너진다
오픈 웨이트 AI 모델이 프런티어 랩의 가격을 억제하는 구조적 역할을 해왔는데, Meta·Alibaba·Mistral 등이 잇따라 모델 공개를 중단하거나 라이선스를 조이면서 이 균형이 흔들리고 있습니다.
Written by

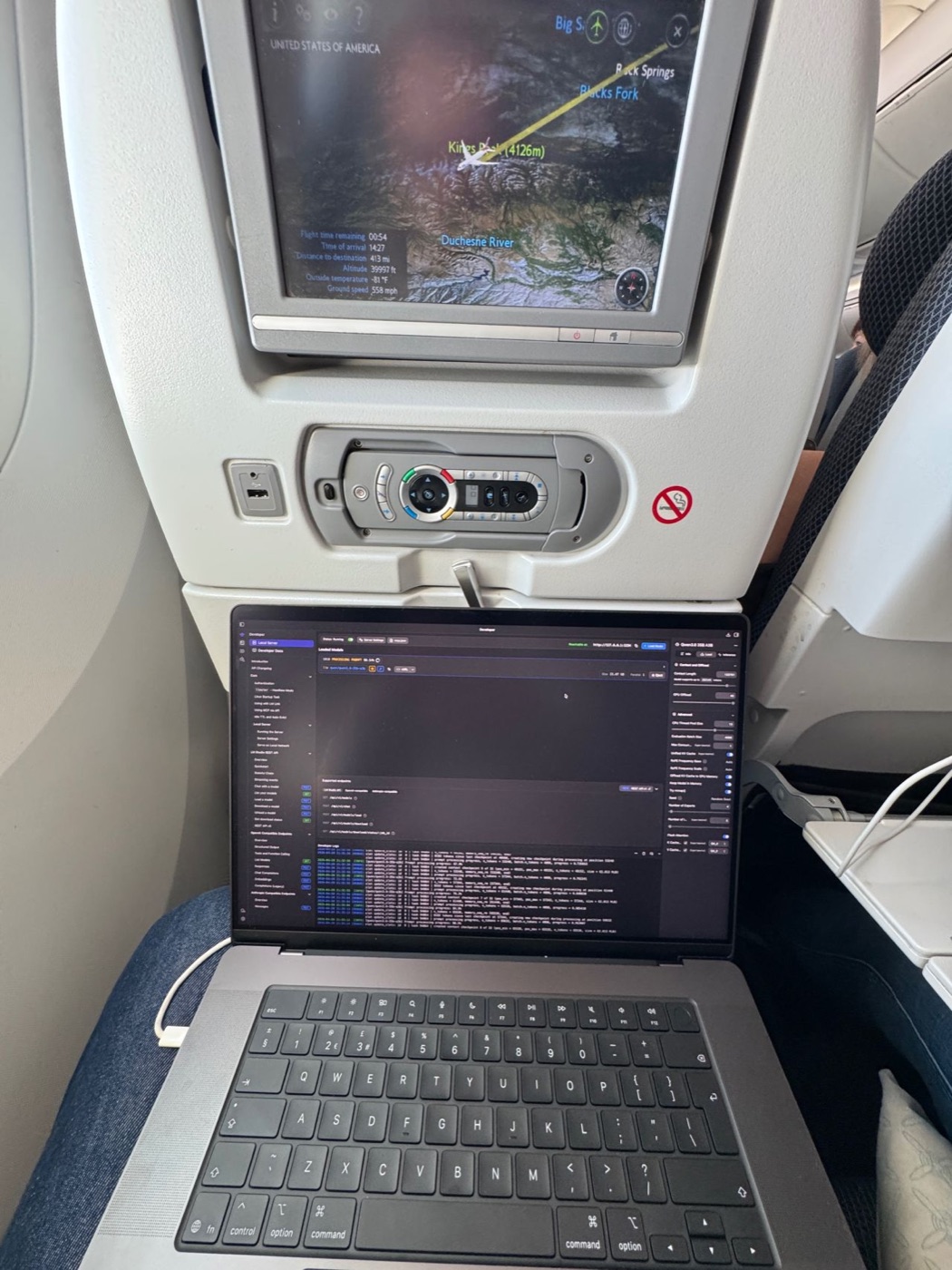
와이파이 없는 10시간, MacBook 하나로 AI 개발을 끝냈다
기내 와이파이 없이 10시간 비행하며 로컬 LLM만으로 실제 개발 작업을 수행한 엔지니어의 실전 후기. 전력·발열·컨텍스트 한계와 케이블 하나로 34W가 사라진 흥미로운 에피소드를 담았습니다.
Written by
21GB로 코딩 에이전트 상위권, Qwen3.6-35B-A3B 오픈소스 공개
알리바바 Qwen 팀이 공개한 Qwen3.6-35B-A3B, MoE 구조로 21GB로 압축해 노트북에서 실행 가능하면서 코딩 에이전트 상위권 성능을 냅니다.
Written by

Qwen3.6-Max, 코딩 벤치마크 1위지만 오픈소스는 없다, Alibaba의 전략 전환
Alibaba가 Qwen 최초의 클로즈드 웨이트 모델 Qwen3.6-Max-Preview를 출시했습니다. 코딩 벤치마크 6개 1위, 오픈소스 포기의 의미를 분석합니다.
Written by

이미지 속 실수 하나가 전부를 망친다, Qwen팀의 HopChain이 고친 방법
알리바바 Qwen팀이 개발한 HopChain은 AI 비전 모델이 다단계 추론 시 오류가 누적되는 문제를 훈련 데이터 구조에서 해결합니다. 24개 벤치마크 중 20개 성능 향상.
Written by

Qwen3.6-Plus, 에이전틱 코딩 강화해 Claude Opus 4.5급 성능 도달
Alibaba Qwen 팀이 에이전틱 코딩에 특화된 Qwen3.6-Plus를 공개했습니다. Claude Opus 4.5급 성능을 내세우며 독점 모델 전략으로 전환하는 배경을 소개합니다.
Written by

멀티 에이전트 오케스트레이션 실전: Microsoft Agent Framework로 만드는 AI 팟캐스트 스튜디오
Microsoft가 공개한 멀티 에이전트 시스템으로 팟캐스트를 완전 자동 제작합니다. 로컬 AI 모델과 Agent Framework를 활용한 실전 사례를 소개합니다.
Written by