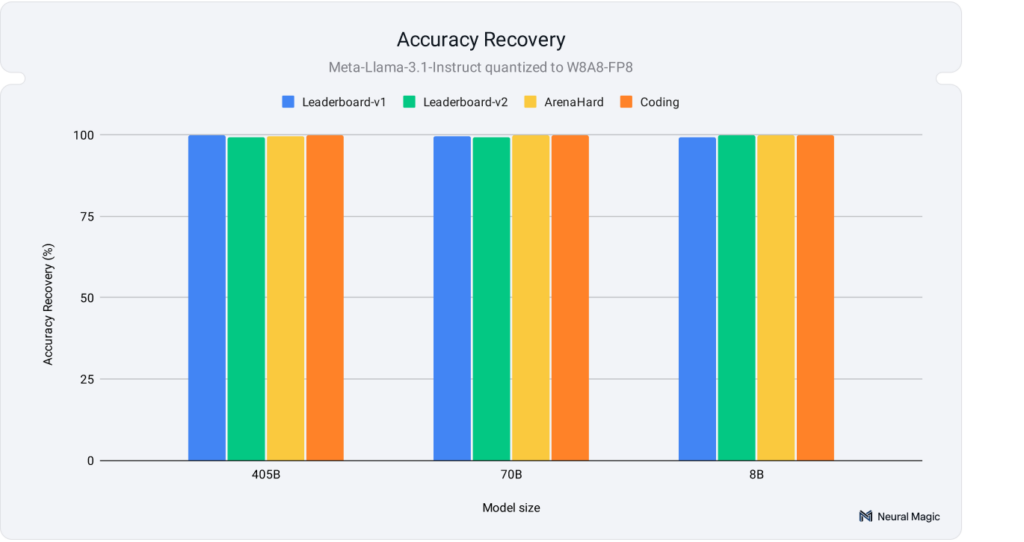
“양자화하면 정확도가 떨어진다”는 우려가 AI 커뮤니티에 오랫동안 있었습니다. Red Hat이 50만 건 이상의 평가를 수행한 결과, 이 논쟁은 사실상 종결됐습니다. 올바른 캘리브레이션과 하이퍼파라미터 튜닝을 거치면 8비트 모델은 원본의 99% 이상, 4비트 모델도 96~99% 수준의 정확도를 유지합니다.

2026년 현재, 양자화는 더 이상 선택적 최적화 기법이 아닙니다. AI 인프라의 핵심이 됐죠. 8GB 노트북에서도 70B 파라미터 모델을 돌릴 수 있고, 클라우드 비용을 월 20달러에서 0달러로 줄일 수 있습니다. 문제는 “양자화를 할까 말까”가 아니라 “어떤 방식을 선택할까”입니다.
정확도 논쟁의 종결
Red Hat 연구팀은 Llama 3.1 모델(8B, 70B, 405B)로 세 가지 양자화 방식을 테스트했습니다. W8A8-INT(8비트 정수), W8A8-FP(8비트 부동소수점), W4A16-INT(4비트 가중치, 16비트 활성화)를 OpenLLM Leaderboard, Arena-Hard, HumanEval 같은 벤치마크에서 평가했죠.
결과는 명확했습니다. 8비트 모델은 OpenLLM Leaderboard에서 원본의 99% 이상 점수를 회복했고, 4비트 모델도 96~99% 범위를 유지했습니다. 특히 코딩 벤치마크인 HumanEval에서는 8비트가 99.9%, 4비트가 98.9% 정확도를 기록하며 실용성을 입증했습니다.
커뮤니티가 우려했던 이유는 부적절한 캘리브레이션, 프롬프트 템플릿 민감도, 하이퍼파라미터 튜닝 부족 때문이었습니다. 이런 문제를 해결하면 양자화 모델은 원본과 구별하기 어려울 정도로 작동합니다.
텍스트 유사도 평가도 이를 뒷받침합니다. ROUGE, BERTScore, Semantic Textual Similarity 지표에서 양자화 모델의 출력이 원본과 거의 동일한 의미를 유지했습니다. 70B와 405B 모델은 단어 선택과 구조까지 원본과 비슷했고, 8B 모델도 핵심 의미는 보존했습니다.
세 가지 주요 방식 비교
양자화 방법은 크게 세 가지로 정리됩니다. GPTQ, GGUF, AWQ입니다. 각각 다른 목적에 최적화되어 있어서, 하드웨어와 용도에 따라 선택이 달라집니다.
GPTQ (Gradient Post-Training Quantization)
GPTQ는 GPU 추론 속도에 초점을 맞춥니다. 학습 후 가중치만 양자화하는 방식이라 빠르게 배포할 수 있죠. NVIDIA A100 같은 고성능 GPU에서 4비트로 압축하면 3~4.5배 속도 향상을 얻습니다. Llama-3.1-8B 기준으로 평균 정확도 손실은 1.26% 수준입니다.
단점은 활성화를 압축하지 않는다는 겁니다. 그래서 활성화 오버헤드에 민감한 하드웨어에서는 이점이 제한적입니다. 재학습이 필요 없고 원샷 압축이 가능해서 프로덕션 파이프라인에 빠르게 통합할 수 있습니다.
GGUF (이전 GGML)
GGUF는 CPU와 GPU를 모두 활용합니다. GPU가 부족하거나 Apple Silicon 같은 환경에서 강점을 보이죠. 레이어 일부를 GPU에 올리고 나머지는 CPU로 처리해서, 제한된 VRAM으로도 대형 모델을 실행할 수 있습니다.
Llama 3.1 8B를 Q4_K_M 포맷으로 양자화하면 정확도는 92% 유지하면서도 파일 크기가 75% 줄어듭니다. Ollama, llama.cpp, LM Studio 같은 도구와 호환성이 좋아서 로컬 AI 구축에 가장 많이 쓰입니다.
블록 크기를 유연하게 조정할 수 있고 메타데이터가 풍부해서 다양한 플랫폼에서 작동합니다. GPU가 없는 환경이나 8GB RAM 노트북에서도 쓸 수 있다는 게 최대 장점입니다.
AWQ (Activation-aware Weight Quantization)
AWQ는 품질 유지에 집중합니다. 모든 가중치가 똑같이 중요하지 않다는 전제에서 출발하죠. 활성화 패턴을 분석해서 중요한 가중치는 보호하고 나머지만 양자화합니다.
이 방식은 창의적 글쓰기나 코딩처럼 일관성이 중요한 작업에서 빛납니다. Llama-2-7B 기준으로 GPTQ보다 1.45배 빠르면서 평균 정확도 손실은 1.27%에 그칩니다. 멀티모달 모델에서 텍스트와 이미지 데이터를 동시에 처리할 때도 정확도를 잘 유지합니다.
캘리브레이션 세트에 과적합하지 않아서 일반화 성능이 좋습니다. 다만 변환 속도가 약간 느리고 CPU 지원이 제한적입니다.
상황별 선택 가이드
Poniak Times가 제시한 결정 매트릭스를 보면 선택이 명확해집니다.
저사양 GPU로 파인튜닝하려면 QLoRA를 쓰세요. 4비트 어댑터 튜닝으로 성능을 보존하면서 VRAM을 79%까지 줄입니다. 학습 후 빠른 배포가 목표라면 GPTQ가 답입니다. 재학습 없이 원샷 압축으로 바로 프로덕션에 투입할 수 있죠.
멀티모달 작업에서 INT4 안정성이 필요하다면 AWQ를 선택하세요. 활성화 패턴 기반으로 중요 채널을 보호합니다. 엣지 디바이스에 배포하려면 SmoothQuant가 좋습니다. 가중치와 활성화 균형을 맞춰서 엣지 하드웨어에 최적화되어 있습니다.
범용 호환성이 필요하면 GGUF를, NVIDIA GPU에서 순수 처리량을 원하면 GPTQ를, 창의적 글쓰기나 코딩 정확도를 중시하면 AWQ를 쓰세요.
하드웨어별로 보면 8GB RAM 노트북에는 GGUF Q4_K_S, RTX 3060/3070에는 GPTQ 4비트, RTX 4070~4090에는 AWQ 4비트나 GGUF Q5, Apple Silicon에는 GGUF Q4_K_M, AMD ROCm 카드에는 vLLM의 AWQ 4비트가 적합합니다.
2026년의 새로운 트렌드
FP8 학습이 고성능 컴퓨팅에서 부상하고 있습니다. Amazon SageMaker P5 인스턴스 같은 플랫폼에서 LLM 학습 메모리를 18% 줄입니다. NVIDIA Hopper GPU 전용이지만 안정적이고 캘리브레이션만 제대로 하면 FP16/BF16 대비 속도와 처리량이 크게 향상됩니다.
레이어별 혼합 정밀도 기법도 발전했습니다. 어텐션 메커니즘 같은 중요 레이어는 8비트나 16비트를 유지하고, 덜 민감한 부분은 4비트나 2비트로 공격적으로 압축합니다. 이렇게 하면 품질을 최대화하면서 메모리 사용을 최소화할 수 있죠.
INT2와 그 이하 비트 연구도 진행 중입니다. 격자 이론 통찰을 활용해서 GPTQ를 Babai 알고리즘과 연결하는 연구가 나오고 있습니다. 조 단위 파라미터 모델이 현실화되면서 이런 초저비트 양자화가 필수가 될 겁니다.
하드웨어 혁신도 이를 뒷받침합니다. FP8 전용 GPU와 RISC-V 가속기가 등장하면서 양자화 효율이 더 올라갑니다. vLLM과 TensorRT-LLM 같은 프레임워크는 배칭, KV-캐시, 추측 디코딩을 통합해서 처리량을 2배 높입니다.
비용과 에너지 절감
양자화의 실질적 이점은 비용입니다. 클라우드 배포에서 같은 서버로 더 많은 추론 요청을 처리할 수 있어서 운영비가 줄어듭니다. 메모리 대역폭과 연산 전력이 낮아져서 에너지 비용도 감소하죠.
Red Hat 연구에 따르면 W8A8 양자화는 모델 크기를 50% 압축하면서 멀티 요청 시나리오에서 평균 1.8배 속도 향상을 냅니다. W4A16은 모델을 3.5배 압축하고 단일 스트림 시나리오에서 2.4배 빠릅니다.
엣지 디바이스에서는 더 극적입니다. NVIDIA Jetson이나 Raspberry Pi에서 INT4 모델은 전력 소비를 50%까지 줄입니다. 실시간 음성 비서나 IoT 분석 같은 애플리케이션을 배터리로 오래 구동할 수 있죠.
양자화는 이제 AI 경제학의 핵심입니다. 누가 이 기술을 마스터하느냐가 향후 몇 년간 LLM 배포 경쟁력을 좌우할 겁니다.
참고자료:
- Model Quantization: Run Large AI Models on Limited Hardware – Analytics Vidhya
- We ran over half a million evaluations on quantized LLMs—here’s what we found – Red Hat Developer
- The 2025 State of Model Quantization: QLoRA, GPTQ, AWQ & Future Trends – Poniak Times
- AWQ vs GPTQ vs GGUF: AI Quantization Comparison (2025) – Local AI Master
- Which Quantization Method is Right for You? (GPTQ vs. GGUF vs. AWQ) – Maarten Grootendorst
답글 남기기