Grok Code Fast 1 모델의 코드 편집 성공률이 6.7%에서 68.3%로 뛰었습니다. 모델을 업그레이드한 것도, 학습 데이터를 추가한 것도 아닙니다. 단지 코드를 편집하는 방식만 바꿨을 뿐이죠.

출처: I Improved 15 LLMs at Coding in One Afternoon. Only the Harness Changed. – Can Boluk
오픈소스 코딩 에이전트 개발자 Can Boluk이 16개 LLM 모델을 대상으로 실험한 결과입니다. 그는 모델 자체가 아닌 “harness”(코드 편집 인터페이스)를 개선했고, 대부분의 모델에서 성능이 크게 향상되었습니다. 특히 약한 모델일수록 개선 폭이 컸죠.
Harness 문제란 무엇인가
AI 코딩 도구를 평가할 때 우리는 보통 “어떤 모델이 더 좋은가?”에 집중합니다. GPT-5.3이냐, Claude Opus냐, Gemini냐. 하지만 Boluk은 다른 질문을 던집니다. “모델이 아무리 좋아도, 그 능력을 코드로 옮기는 도구가 형편없다면?”
Harness는 모델의 출력(텍스트)과 실제 코드 변경 사이의 다리입니다. 모델이 “이 부분을 고쳐야 해”라고 이해해도, 그걸 실제 파일에 반영하려면 특정 형식으로 표현해야 하죠. 문제는 각 도구마다 이 형식이 다르고, 모델마다 특정 형식에 강하거나 약하다는 점입니다.
현재 주요 방식들:
- Patch (OpenAI Codex): diff 형식 사용. 정확한 구조를 요구하지만 다른 모델들은 이 형식에 익숙하지 않음. Grok 4는 50.7%, GLM-4.7은 46.2% 실패율 기록.
- String Replace (Claude Code, Gemini): 정확한 텍스트를 찾아 교체. 공백 하나만 달라도 실패. “String to replace not found” 에러가 너무 흔해서 GitHub 이슈 메가스레드가 27개나 생겼습니다.
- Neural Network (Cursor): 아예 별도의 70B 모델을 학습시켜 편집을 처리. harness 문제가 너무 어려워서 또 다른 AI를 동원한 셈이죠.
공통점이 보이나요? 모든 방식이 모델에게 이미 본 내용을 정확히 재현하라고 요구합니다. 공백, 들여쓰기, 특수문자까지 완벽하게요. 모델이 내용은 이해해도 형식을 틀리면 실패합니다.
Hashline: 새로운 접근법
Boluk의 해법은 단순합니다. 코드의 각 줄에 2-3자 해시태그를 붙이는 거죠.
11:a3|function hello() {
22:f1| return "world";
33:0e|}모델이 편집할 때는 이 태그를 참조합니다. “2:f1 줄을 바꿔줘”, “1:a3부터 3:0e까지 교체해줘”처럼요. 파일이 중간에 바뀌었다면 해시가 맞지 않아 편집이 거부됩니다.
이 방식의 핵심은 모델이 내용을 재현할 필요가 없다는 점입니다. 짧은 태그만 기억하면 되죠. 공백을 맞춰야 할 필요도, diff 형식을 완벽히 따를 필요도 없습니다. 태그를 기억한다는 건 곧 해당 코드를 이해한다는 의미니까요.
벤치마크 결과
React 코드베이스에서 무작위로 파일을 선택하고, 의도적으로 버그를 심습니다(연산자 교체, boolean 반전, off-by-one 에러 등). 그리고 모델에게 “이 버그를 고쳐줘”라고 요청하죠. 180개 작업, 3회 반복, 16개 모델로 테스트했습니다.
주요 결과:
- Hashline이 16개 모델 중 14개에서 Patch보다 우수
- 토큰 사용량은 평균 20-30% 절감
- 최대 개선: Grok Code Fast 1 → 6.7%에서 68.3%로 (+61.6%p)
- MiniMax는 성공률이 2배 이상 증가
- Grok 4 Fast는 출력 토큰이 61% 감소 (재시도 루프 제거)
Gemini 3 Flash는 8.3%p 개선되었는데, 이는 대부분의 모델 업그레이드보다 큰 폭입니다. 학습 비용은 0원이었고, 단지 편집 도구를 바꿨을 뿐이죠.
업계의 아이러니한 반응
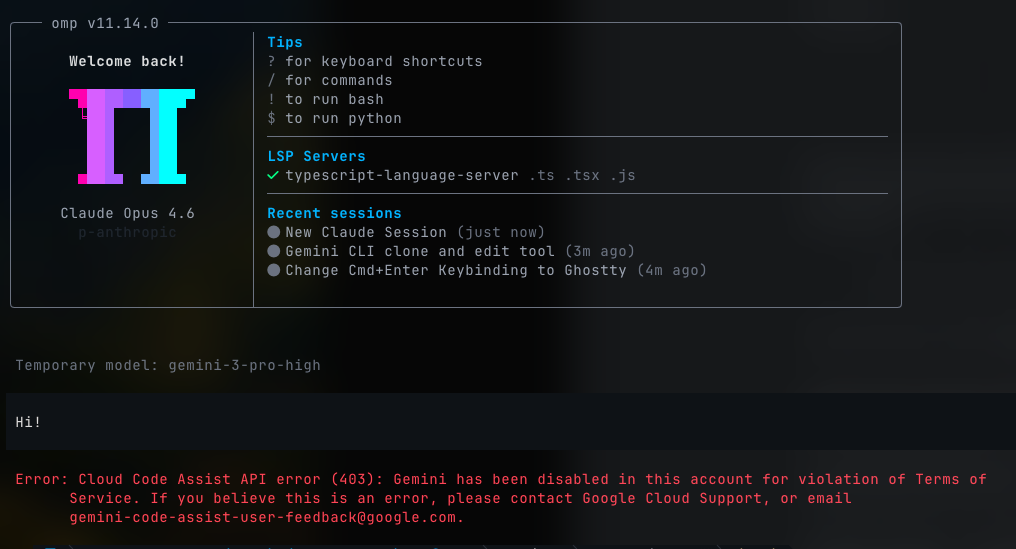
흥미로운 점은 AI 업체들의 반응입니다. Anthropic은 최근 인기 오픈소스 도구인 OpenCode가 Claude Code API를 사용하지 못하도록 차단했습니다. “비공개 API를 역공학했다”는 이유에서죠.
Google은 더 직접적이었습니다. Boluk이 이 벤치마크를 돌리던 중 Gemini 계정이 아예 비활성화되었습니다. 경고도, 설명도 없이요. 아이러니하게도 그의 실험은 Gemini 3 Flash가 새 방식으로 5%p 더 좋아진다는 걸 증명했는데 말이죠.
Boluk은 지적합니다. “어떤 업체도 경쟁사 모델을 위해 harness를 최적화하지 않습니다. Anthropic은 Grok을 위해, xAI는 Gemini를 위해, OpenAI는 Claude를 위해 개선하지 않죠. 하지만 오픈소스 harness는 모두를 위해 개선합니다. 기여자들이 각자 사용하는 모델의 문제를 고치니까요.”
왜 중요한가
이 실험이 시사하는 바는 명확합니다. 모델 성능 논쟁은 불완전한 프레임이라는 거죠. “어떤 모델이 코딩을 더 잘하나?”라는 질문은 “파일럿이 더 뛰어난가?”를 묻는 것과 비슷합니다. 착륙 장치가 고장났다면 아무리 훌륭한 파일럿도 소용없죠.
실제로 대부분의 실패는 모델이 작업을 이해하지 못해서가 아니라, 자신을 표현하지 못해서 발생합니다. Patch 형식에 익숙하지 않은 모델은 올바른 수정안을 알아도 형식 오류로 거부당합니다. String Replace에서는 공백 하나 때문에 실패하죠.
+8%의 성공률 개선은 대부분의 모델 업그레이드보다 큽니다. 그런데 학습 비용은 0원이고, 단 하루 만에 달성했습니다. 우리가 “모델의 한계”라고 생각했던 것 중 상당 부분이 사실은 도구의 한계였던 셈입니다.
Boluk의 결론은 단순하지만 강력합니다. “Harness 문제는 해결될 겁니다. 문제는 한 회사가, 비공개로, 한 모델을 위해 해결할 것인가, 아니면 커뮤니티가, 공개적으로, 모든 모델을 위해 해결할 것인가입니다.”
참고자료:
- oh-my-pi GitHub 저장소 – 벤치마크 코드 및 결과
답글 남기기