당신이 AI에게 “좀 더 외향적으로 말해줘”라고 부탁할 때, 모델은 그 성격을 어디서 가져올까요? 프롬프트를 따라 흉내 내는 걸까요, 아니면 원래부터 내부 어딘가에 있던 걸 꺼내는 걸까요?

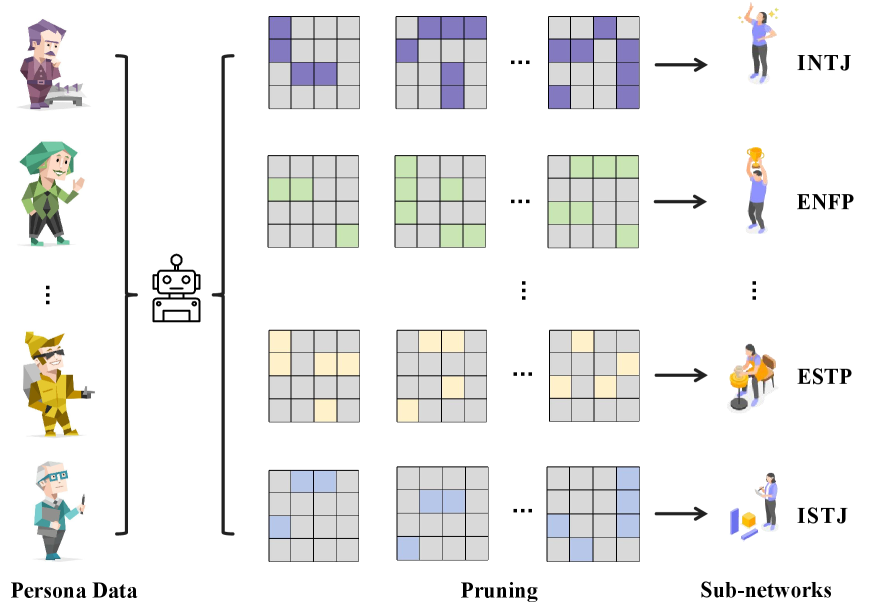
Tulsa 대학교, Northwestern 대학교, Arizona 대학교 공동 연구팀이 2026년 2월 arXiv에 발표한 논문에서 흥미로운 답을 내놓았습니다. LLM은 외부에서 성격을 주입받는 게 아니라, 사전학습 과정에서 이미 다양한 페르소나에 해당하는 서브네트워크를 파라미터 안에 품고 있다는 것입니다. 연구팀은 훈련 없이 이 서브네트워크를 찾아 격리하는 방법까지 제안했습니다.
출처: Your Language Model Secretly Contains Personality Subnetworks – arXiv
지금까지의 방식과 한계
AI에 특정 성격을 부여하는 방법은 크게 세 가지였습니다. 시스템 프롬프트로 역할을 지시하거나, 관련 데이터를 검색해 맥락으로 제공하거나(RAG), 아니면 특정 성격 데이터로 파인튜닝하는 방식이었죠.
문제는 이 방법들이 모두 불안정하거나 비용이 크다는 점입니다. 프롬프트 기반 방식은 대화가 길어질수록 성격이 흐트러지고, 파인튜닝은 성격마다 별도 모델을 만들어야 해 자원 소모가 큽니다.
성격은 이미 모델 안에 있었다
연구팀의 핵심 발견은 단순하지만 의미 있습니다. LLM에게 내향적인 성격에 맞는 입력을 주면 특정 뉴런들이 활성화되고, 외향적인 입력을 주면 또 다른 뉴런 집합이 활성화됩니다. 그리고 이 패턴은 일관되게 반복됩니다.
이는 성격별로 다른 ‘회로’가 이미 파라미터 안에 잠재해 있다는 뜻입니다. 연구팀은 이를 ‘페르소나 서브네트워크’라고 부릅니다.
어떻게 꺼내는가
연구팀이 제안한 방법은 세 단계입니다.
① 소규모 성격별 데이터(수백~수천 개)를 모델에 통과시키며 뉴런 활성화 통계를 수집합니다. ② 해당 성격에 반응하는 파라미터를 중요도 순으로 정렬해, 이진 마스크(0 또는 1)로 격리합니다. ③ 추론 시 마스크만 교체해 성격을 전환합니다. 추가 학습은 전혀 없습니다.
내향-외향처럼 대립하는 성격 쌍의 경우에는 ‘대조적 가지치기(contrastive pruning)’를 추가로 적용합니다. 두 성격 사이의 통계적 차이를 극대화하는 방향으로 파라미터를 선별해, 서브네트워크 간 간섭을 줄이는 방식입니다.
해석 가능성의 새로운 단서
이 연구의 의미는 기술적 효율성 이상입니다. “성격은 외부에서 주입해야 한다”는 기존 패러다임을 뒤집고, LLM이 이미 내면에 복수의 성격 구조를 갖고 있다는 해석 가능성(interpretability) 관점의 단서를 제공합니다.
실험에서 이 방법으로 추출한 서브네트워크는 프롬프트 기반 베이스라인보다 성격 일관성이 높게 나타났고, 추론 시 파라미터 일부만 활성화하기 때문에 효율도 더 우수했습니다.
물론 아직 한계는 있습니다. 소규모 캘리브레이션 데이터의 품질에 성능이 크게 좌우되고, 매우 복잡하거나 미묘한 성격 차이까지 분리할 수 있는지는 추가 검증이 필요합니다. 논문에는 다양한 LLM 모델을 대상으로 한 벤치마크 비교와 ablation 실험 결과도 담겨 있습니다.
참고자료: GitHub 코드
답글 남기기