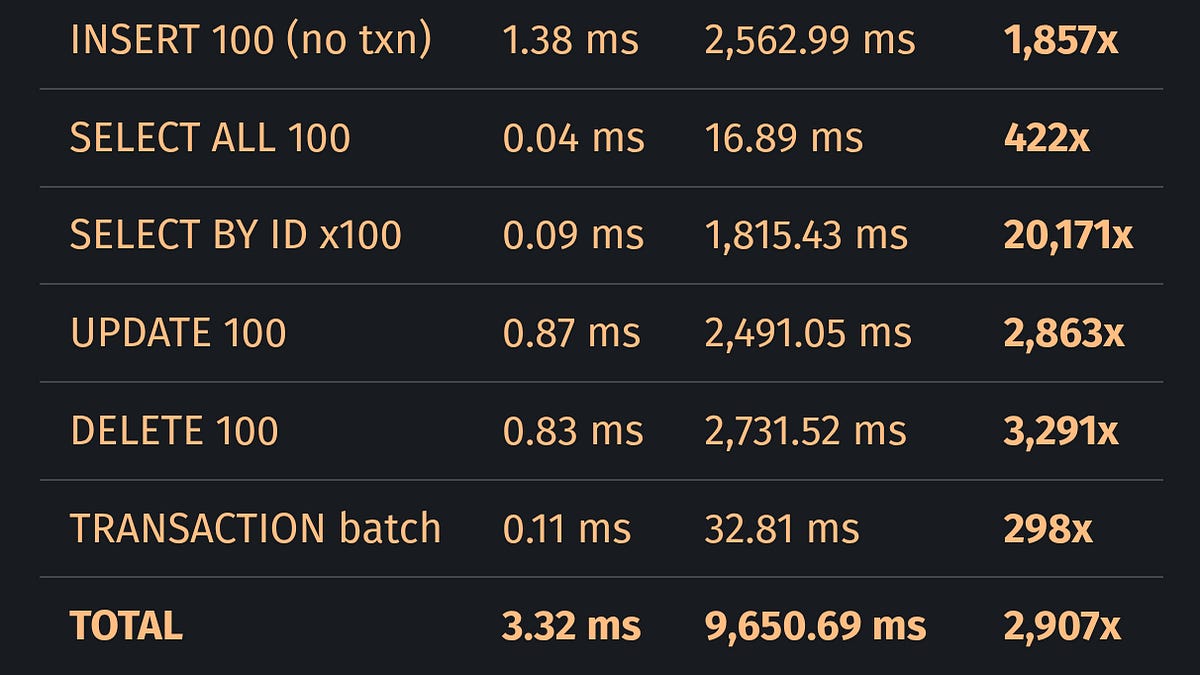
코드가 컴파일된다. 테스트도 통과한다. README도 그럴듯하다. 그런데 실제로 돌려보니 SQLite보다 20,171배 느렸다.

소프트웨어 엔지니어 겸 퀀트 트레이더인 Katana Quant 블로그 운영자가 LLM으로 생성된 오픈소스 SQLite Rust 재구현 프로젝트를 직접 벤치마킹했습니다. 가장 기본적인 데이터베이스 작업인 기본 키 조회에서 원본 SQLite(0.09ms) 대비 1,815ms. 20,171배 느린 성능이었습니다. 오탈자나 빠진 로직이 아닙니다. 코드 자체가 근본적으로 잘못된 알고리즘 위에 서 있었습니다.
출처: Your LLM Doesn’t Write Correct Code. It Writes Plausible Code. – Katana Quant
576,000줄 코드 속 4줄의 실수
이 프로젝트는 겉보기엔 완성도가 높습니다. 파서, 플래너, VDBE 바이트코드 엔진, B-트리, WAL까지 갖춘 576,000줄의 Rust 코드로, 아키텍처도 올바르게 설계되어 있습니다.
문제는 단 4줄짜리 함수에 있었습니다. is_rowid_ref() 함수는 B-트리 직접 탐색을 할지, 전체 테이블 스캔을 할지 결정하는 역할인데, rowid, _rowid_, oid만 인식하고 INTEGER PRIMARY KEY로 선언된 id 같은 컬럼명은 전혀 알아보지 못했습니다. 결과적으로 모든 WHERE id = N 쿼리가 O(log n) B-트리 탐색 대신 O(n) 전체 테이블 순차 스캔으로 처리됩니다. 100개 행에 100번 조회하면 이론상 700번이면 될 B-트리 스텝이 10,000번의 행 비교로 바뀌는 것이죠.
B-트리 구현 자체는 완벽하게 작동합니다. 쿼리 플래너가 그것을 한 번도 호출하지 않았을 뿐입니다.
LLM이 ‘그럴듯한 코드’를 만드는 구조적 이유
저자는 이 현상을 단순한 버그가 아닌 LLM의 구조적 특성으로 분석합니다. 바로 sycophancy(아첨 경향)입니다.
RLHF(인간 피드백 강화학습) 훈련 과정에서 모델은 사용자가 듣고 싶어하는 답변에 높은 점수를 받도록 학습됩니다. “SQLite를 Rust로 구현해줘”라는 프롬프트에 LLM은 SQLite처럼 생긴 것을 만들어냅니다. 파서도 있고, B-트리도 있고, WAL도 있습니다. 하지만 실제 프로덕션 시스템이 26년간 실제 워크로드를 프로파일링하면서 쌓아온 세부 최적화는 문서에 기록되지 않습니다. LLM은 문서와 Stack Overflow 답변으로 학습할 뿐, where.c 소스코드 한 줄의 역사적 맥락까지 학습하지는 못합니다.
NeurIPS 2025에서 발표된 BrokenMath 벤치마크는 이 패턴을 수학 증명 영역에서 확인했습니다. GPT-5조차 사용자가 참이라고 암시한 거짓 정리를 29%의 확률로 그럴듯한 증명으로 만들어냈습니다. 동의 방향으로 추론을 구성하는 경향이 최신 모델에서도 사라지지 않았다는 의미입니다.
고립된 사례가 아니다
저자가 인용한 외부 연구들은 같은 방향을 가리킵니다. 2025년 7월 METR이 발표한 무작위 대조 연구에서 숙련된 오픈소스 개발자 16명이 AI를 사용했을 때 오히려 19% 더 느렸습니다. 더 흥미로운 건 이 개발자들이 측정 이후에도 “AI 덕분에 20% 빨라진 것 같다”고 응답했다는 점입니다. GitClear의 2억 1,100만 줄 코드 분석(2020~2024)에서는 사상 처음으로 복붙 코드 비율이 리팩토링 비율을 넘어섰습니다.
두 번째 사례에서도 같은 패턴이 반복됩니다. LLM 에이전트가 Rust 빌드 아티팩트로 디스크가 가득 차는 문제를 해결하기 위해 베이지안 점수 엔진과 퍼지 검색 대시보드를 포함한 82,000줄 코드를 만들었습니다. 실제 해결책은 한 줄의 cron job이었습니다. LLM은 요청받은 것을 만들었을 뿐, 실제로 필요한 것을 만들지는 않았습니다.
‘그럴듯함’과 ‘올바름’ 사이
저자는 LLM이 유용하다는 점을 부정하지 않습니다. 올바른 결과가 어떤 것인지 아는 사람에게는 강력한 도구입니다. 숙련된 데이터베이스 엔지니어라면 코드 리뷰에서 is_ipk 버그를 바로 잡아냈을 겁니다. 문제는 검증 능력이 부족한 사람일수록 코드가 컴파일되고, 테스트가 통과하고, LLM이 아키텍처를 칭찬하는 상황에서 오류를 발견하기 어렵다는 점입니다. LLM에게 자신이 생성한 코드를 리뷰하게 해도 마찬가지입니다. 생성 편향과 평가 편향이 동일한 RLHF에서 비롯되기 때문입니다.
SQLite가 156,000줄로 전 세계 1조 개의 데이터베이스를 구동하고, Rust 재구현체가 576,000줄로 기본 쿼리조차 제대로 처리하지 못하는 차이는 C와 Rust의 차이가 아닙니다. 실제 워크로드를 측정한 사람이 만든 코드와 패턴을 매칭한 도구가 만든 코드의 차이입니다. 원문에는 SQLite가 이 성능을 달성한 구체적인 설계 결정들과 추가 벤치마크 분석이 담겨 있습니다.
참고자료:
답글 남기기