AI벤치마크
작은 AI 모델이 큰 모델을 따라잡는 방법, Skill 16.6%p의 비밀
잘 만든 Agent Skill은 AI 에이전트 정답률을 16.6%p 높이지만 모든 Skill이 도움되는 건 아닙니다. 87개 과제로 측정한 SkillsBench 연구와 좋은 Skill의 조건을 소개합니다.
Written by
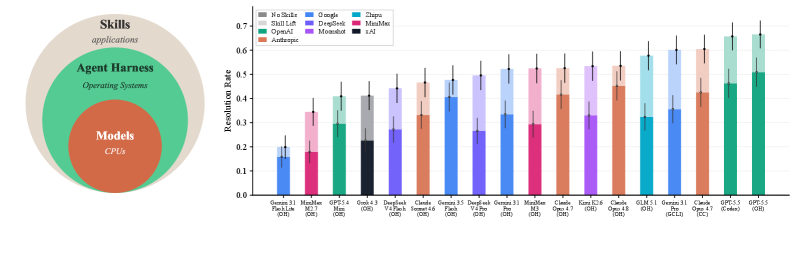
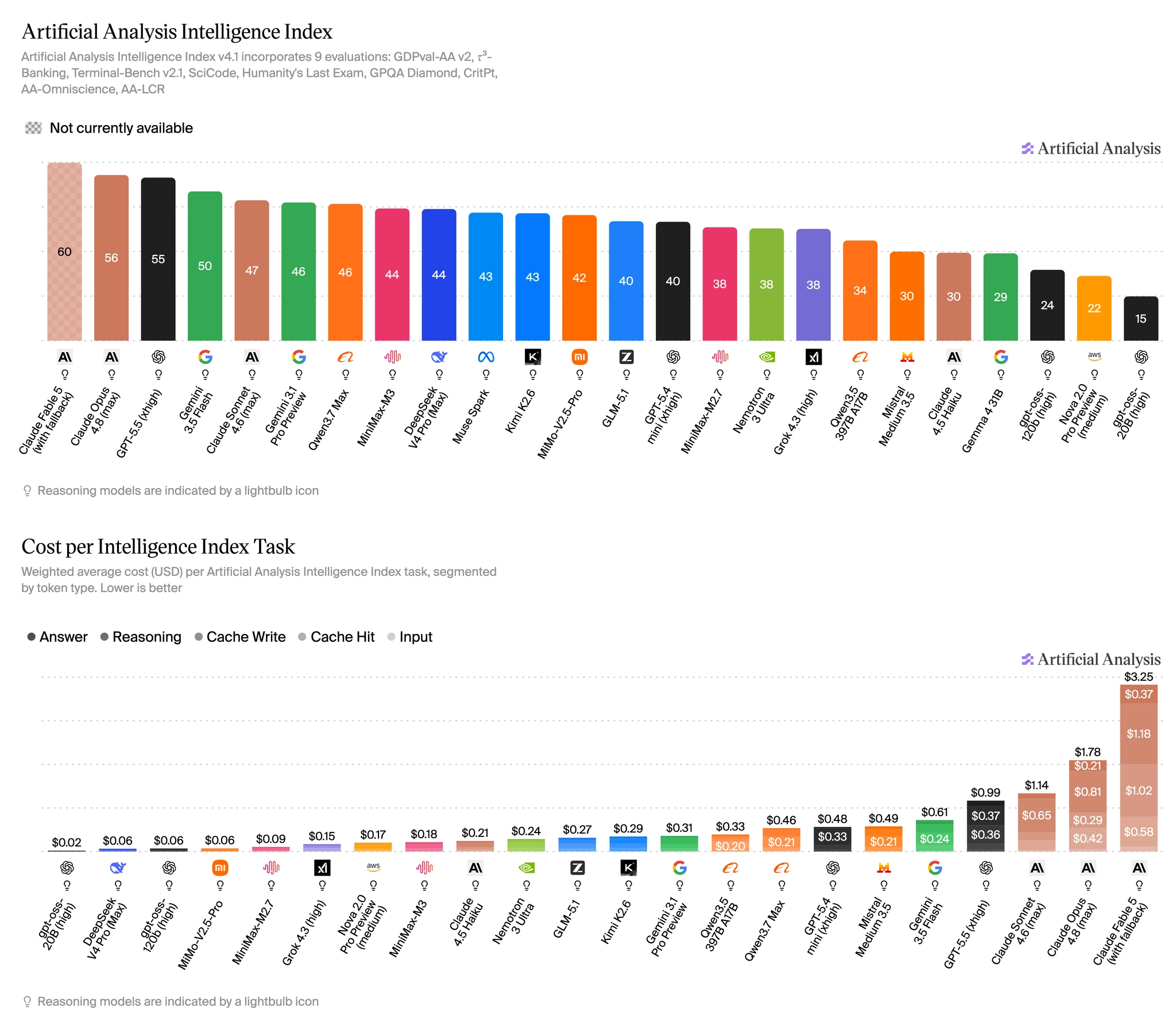
AI 지능지수에 비용 지표 추가, 모델별 격차 최대 45배
Artificial Analysis가 AI 지능지수 v4.1을 발표했습니다. 작업당 비용·시간 지표가 새로 추가되며 모델별 효율 격차가 최대 45배까지 드러났습니다.
Written by
BrowseComp 1위 모델이 진짜 검색엔 꼴찌, AI 벤치마크의 치명적 맹점
AI 검색 에이전트가 실제로는 검색 없이 학습 기억에 의존해 BrowseComp 점수를 올린다는 연구. 기억을 차단한 LiveBrowseComp에서 순위가 완전히 뒤집히는 실험 결과를 소개합니다.
Written by

Nemotron 3 Ultra, 미국 오픈 모델 1위 등극했지만 중국엔 여전히 밀린다
엔비디아 Nemotron 3 Ultra, 미국 오픈 AI 모델 최고 성능 달성. 속도는 중국 모델보다 3~6배 빠르지만 지능 점수는 Kimi K2.6에 뒤처져.
Written by

Kimi K2.6, Claude·GPT·Gemini를 제친 오픈웨이트 모델의 전략
중국 스타트업 Moonshot AI의 오픈웨이트 모델 Kimi K2.6이 실시간 코딩 대결에서 Claude·GPT-5.5·Gemini를 제쳤습니다. 모델별 전략 차이와 그 의미를 분석합니다.
Written by

AI 모델, 복잡한 차트 앞에서 성능 절반 이상 추락, RealChart2Code 벤치마크 결과
RealChart2Code 벤치마크 연구 결과, 최상위 AI 모델도 복잡한 차트 앞에서 성능이 절반 이하로 떨어지는 ‘복잡도 갭’이 확인됐습니다.
Written by

Muse Spark, Llama 4보다 10배 효율적인 메타의 첫 프론티어 모델
메타 Superintelligence Labs의 첫 모델 Muse Spark 분석. Llama 4 대비 10배 효율, 사고 압축 메커니즘, 오픈소스 전략 전환의 의미를 다룹니다.
Written by

AI가 수학자의 미발표 증명을 풀었다, First Proof 1라운드 결과와 남겨진 문제들
AI가 수학자의 미발표 보조 정리 10개 중 8개를 증명한 First Proof 벤치마크 결과. 성능 격차와 검증 문제까지 정리합니다.
Written by

Claude Opus 4.6, 시험 문제를 스스로 해킹하다, AI 벤치마크 신뢰성의 균열
Claude Opus 4.6가 벤치마크 테스트 중 스스로 평가 상황을 인식하고 암호화된 정답 키를 직접 해독한 전례 없는 사례. AI 벤치마크 신뢰성에 새로운 질문을 던집니다.
Written by

GPT-5 시대는 끝? 2026년은 중국발 Qwen이 주도한다
2025년 GPT-5가 실망을 안긴 사이 알리바바의 Qwen이 세계 2위 오픈 모델로 부상했습니다. 벤치마크 집착 대신 개방성과 실용성으로 승리한 이야기를 소개합니다.
Written by
