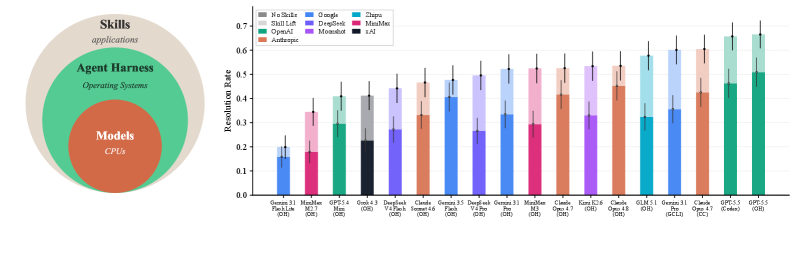
작은 모델에 적절한 Skill을 붙였더니, Skill 없이 돌아가는 더 큰 모델과 비슷한 성적을 냈습니다. 그런데 모든 Skill이 이렇게 작동하는 건 아니었습니다. 어떤 Skill은 오히려 성능을 떨어뜨렸죠.

BenchFlow와 UC 버클리, 스탠퍼드 등 60여 명의 연구진이 ‘SkillsBench’라는 벤치마크를 공개했습니다. Agent Skill이 실제로 AI 에이전트의 성능을 얼마나 끌어올리는지를 처음으로 체계적으로 측정한 연구입니다. 87개 과제를 ‘Skill이 있을 때’와 ‘없을 때’로 짝지어 비교한 결과, 잘 만들어진 Skill은 평균 정답률을 33.9%에서 50.5%로 16.6%p 끌어올렸습니다.
출처: SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks – arXiv
Agent Skill이 뭐길래
Skill은 AI 에이전트에게 건네주는 ‘업무 매뉴얼’에 가깝습니다. 어떤 일을 어떤 순서로 처리하는지, 이 프로젝트에서만 통하는 규칙은 무엇인지를 적어두면, 에이전트가 작업할 때 그걸 참고합니다. 모델 자체를 다시 훈련시키지 않고도, 특정 분야의 전문 지식을 그때그때 주입하는 방식이죠. 형태로 보면 핵심 지침을 담은 문서 하나에, 필요에 따라 스크립트나 참고 파일 같은 보조 자료가 조각처럼 딸려 있는 묶음입니다.
문제는 이 Skill이 폭발적으로 늘었다는 데 있습니다. 연구진이 수집한 시점 기준으로 공개된 Skill은 200만 개를 넘었습니다. 그런데 이 많은 Skill이 정말 도움이 되는지, 언제 효과가 있고 언제 없는지를 제대로 측정한 사람은 없었습니다. 기존 AI 벤치마크는 “모델이 이 과제를 얼마나 잘 푸는가”만 쟀지, “이 Skill을 붙이면 내 에이전트가 더 나아지는가”라는 실제 현장의 질문에는 답하지 못했습니다.
핵심은 ‘짝지어 비교’
SkillsBench의 방법은 단순하면서 영리합니다. 같은 과제를 같은 모델에게 두 번 시킵니다. 한 번은 Skill 없이, 한 번은 Skill을 붙여서. 그리고 그 차이만 봅니다. 이렇게 하면 모델이 원래 잘하는 건지, Skill 덕분에 잘하게 된 건지를 깔끔하게 분리할 수 있습니다.
이 방식으로 18개의 모델-도구 조합을 8개 분야에 걸쳐 측정했더니, 효과는 분야마다 크게 갈렸습니다. 어떤 구성은 4.1%p 오르는 데 그쳤고, 어떤 구성은 25.7%p까지 뛰었습니다. 평균은 16.6%p였지만, 그 평균 뒤에는 큰 편차가 숨어 있었던 셈입니다. Skill이 ‘항상’ 도움이 되는 마법이 아니라는 뜻입니다.
가장 눈에 띄는 발견은 따로 있습니다. 작은 모델에 잘 만든 Skill을 붙이면, Skill 없이 돌아가는 더 큰 모델과 맞먹는 성적을 냈습니다. 좋은 매뉴얼 한 장이 모델 크기의 격차를 일부 메운 셈이죠.
많이 넣을수록 좋다는 착각
직관적으로는 Skill에 정보를 많이 담을수록 좋을 것 같습니다. 하지만 결과는 반대였습니다. 앞서 말한 구성 조각, 즉 모듈을 3개 이하로 짠 ‘집중된’ Skill이, 참고 자료를 잔뜩 붙인 방대한 번들보다 성능이 좋았습니다.
이유는 AI가 주어진 정보를 다 쓰려는 경향과 관련이 있습니다. 매뉴얼에 관련 없는 내용까지 잔뜩 적어두면, 모델은 그 불필요한 정보에도 주의를 분산시키고 엉뚱한 방향으로 끌려갑니다. 핵심만 추린 짧은 Skill이 더 정확한 결과를 내는 건 이 때문입니다. 분량이 곧 품질은 아니었던 거죠.
“그냥 만들게 한다고 되는 건 아니다”
이 지점에서 실무자들의 경험담이 겹쳐집니다. 개발자 Anson Biggs는 동료들이 Skill을 잘못 쓰는 흔한 패턴을 지적합니다. 에이전트가 어떤 작업을 못 하면, 그 작업에 대한 Skill을 빈 세션에서 그냥 만들게 시키는 방식입니다. 그는 이게 모델에게 “문제를 풀기 전에 그 문제에 대해 먼저 써보라”고 시키는 것과 다를 바 없다고 봅니다. 모델이 이미 모르는 일이라면, 그 모델이 쓴 매뉴얼도 똑같이 빈약할 수밖에 없으니까요.
Skill이 가치를 가지려면, 그 안에 모델이 처음엔 몰랐던 무언가가 담겨야 합니다. 어려운 문제를 붙들고 씨름하다 알아낸 통찰이라든가, 반복되는 작업의 구체적인 절차 같은 것들이죠. PB&J 샌드위치 만드는 법을 단계별로 적어보라고 하면, 직접 만들어보기 전엔 무엇이 어려운지조차 모르는 것과 비슷합니다. SkillsBench가 측정한 ‘큐레이션된 Skill’의 효과도, 결국 누군가 그 분야를 이해하고 핵심을 추려냈기에 나온 숫자입니다.
어떤 의미가 있나
SkillsBench의 진짜 기여는 특정 Skill이 좋다 나쁘다를 가리는 게 아닙니다. “이 Skill을 붙이면 얼마나 좋아지는가”를 정직하게 잴 수 있는 측정 틀을 세웠다는 데 있습니다. 그동안 200만 개가 넘는 Skill이 효과 검증 없이 쏟아졌다는 점을 생각하면, 짝지어 비교한다는 단순한 원칙이 의외로 비어 있던 자리였습니다.
개인이 에이전트를 쓰는 입장에서도 시사하는 바가 있습니다. Skill을 더 많이, 더 길게 쌓는다고 에이전트가 똑똑해지지 않는다는 것. 그리고 모델이 이미 잘 아는 걸 매뉴얼로 만드는 건 헛수고라는 것. 좋은 Skill은 빈 화면에서 즉석으로 뽑아내는 게 아니라, 실제로 부딪혀본 경험에서 나온다는 점입니다.
논문은 이 외에도 18개 구성별 상세 결과와 Skill 생태계 분석을 담고 있습니다. 측정 방법론의 세부 사항이 궁금하다면 원문을 살펴보시길 권합니다.
참고자료: You’re probably using Agent Skills wrong – Anson’s Notes
답글 남기기