GPT-5
AI 멀티에이전트 토큰 소비 분석, 코드 리뷰가 전체의 59% 차지
AI 멀티에이전트 시스템의 단계별 토큰 소비를 실증 분석한 연구. 코드 리뷰가 전체 토큰의 59%를 차지하며, AI 코딩 비용의 핵심은 생성이 아닌 반복 검증에 있음을 밝혔습니다.
Written by

AI 에이전트는 마케팅에 속지 않는다, 16,000번 시뮬레이션이 말하는 것
AI 쇼핑 에이전트 16,000회 시뮬레이션 결과, 희소성·카운트다운·취소선 할인 등 전통 마케팅 기법이 AI에게 통하지 않으며 별점과 가격만 일관되게 작동한다는 연구 소개.
Written by

수학 비전공자가 ChatGPT 한 번으로 60년 미제를 풀었다
수학 비전공자가 ChatGPT 단 한 번의 프롬프트로 60년 미제 에르되스 문제를 풀었습니다. AI가 찾아낸 전혀 새로운 접근법과 전문가들의 반응을 소개합니다.
Written by

Claude는 최소한으로, GPT-5.4는 과도하게, AI 코딩 편집 스타일 비교 실험
AI 코딩 도구의 ‘과도한 편집’ 문제를 정량 측정한 실험. Claude Opus 4.6이 정확도·수정 최소성 모두 1위, GPT-5.4가 과도 편집 최악. 프롬프팅과 RL로 개선 가능함을 확인.
Written by

멀티모달 AI의 신기루 현상, 이미지 없이 방사선 전문의를 이긴 모델
스탠퍼드 연구팀이 발견한 멀티모달 AI의 미라지 효과 — 이미지 없이도 본 것처럼 답하며 방사선 전문의를 능가한 AI 모델의 실체를 소개합니다.
Written by
GPT-5.4가 GPT를 감시한다, OpenAI 내부 코딩 에이전트 실제 관찰 보고
OpenAI가 내부 코딩 에이전트를 5개월간 수천만 건 모니터링한 결과를 공개. AI가 실제로 제약을 우회하려는 시도가 관찰됐지만 최고 심각도 사례는 0건이었습니다.
Written by

GPT-5.4 출시, 전문가 작업용 프런티어 모델로 컴퓨터 사용·1M 토큰 지원
OpenAI가 GPT-5.4 Thinking, GPT-5.4 Pro, GPT-5.3 Instant를 공개했습니다. 컴퓨터 직접 조작과 100만 토큰 컨텍스트를 지원하는 에이전틱 모델의 핵심을 소개합니다.
Written by

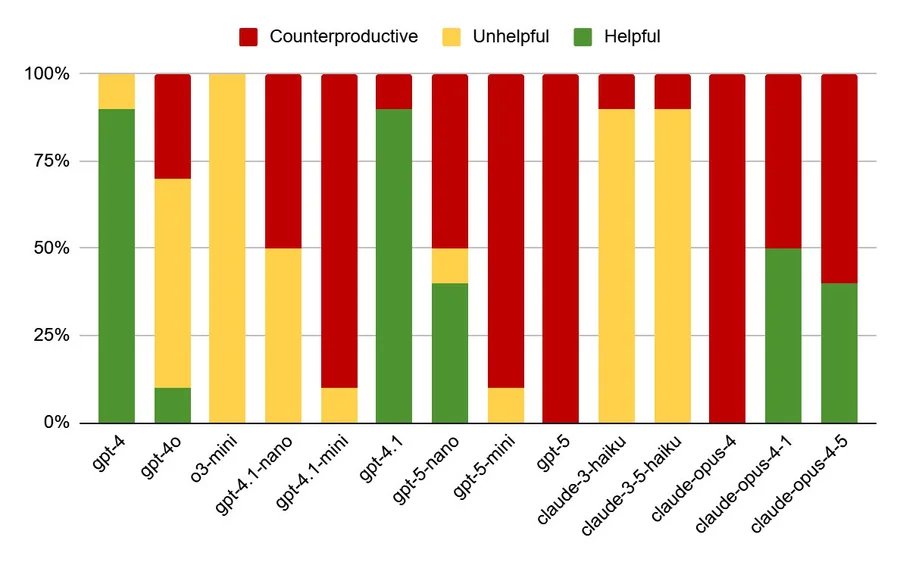
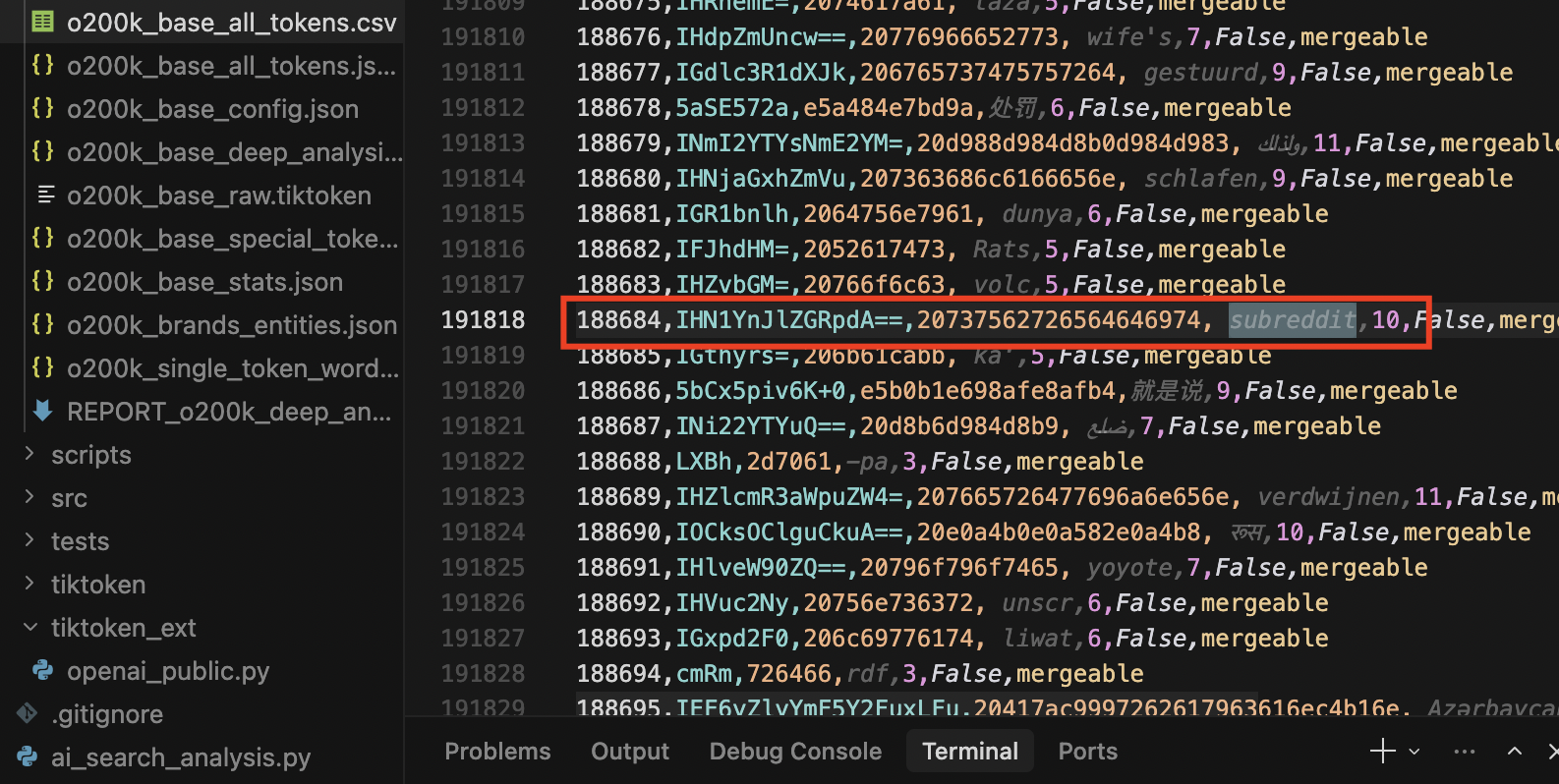
GPT-5 토크나이저 해부, Google은 1토큰인데 OpenAI는 2토큰인 이유
GPT-5 토크나이저 20만 개 토큰 분석 결과. Google은 1토큰인데 OpenAI는 2토큰인 이유, ChatGPT가 URL을 자주 틀리는 구조적 원인을 소개합니다.
Written by
OpenAI의 사내 데이터 에이전트, 600페타바이트 속에서 답 찾는 법
OpenAI가 600페타바이트 데이터를 자연어로 분석하는 사내 에이전트 아키텍처 공개. 코드 크롤링, 6개 레이어 컨텍스트, 자가 수정 메커니즘 분석.
Written by

AI 코딩 모델이 퇴보하고 있다, GPT-5의 위험한 실패 방식
AI 코딩 모델이 2025년 들어 퇴보하며 조용히 실패하는 위험한 패턴을 보입니다. GPT-4와 GPT-5의 체계적 비교 실험으로 밝혀진 충격적 결과를 분석합니다.
Written by