GPT-5
AI는 시험은 잘 보는데 왜 어려운지는 모른다: 언어모델의 ‘지식의 저주’
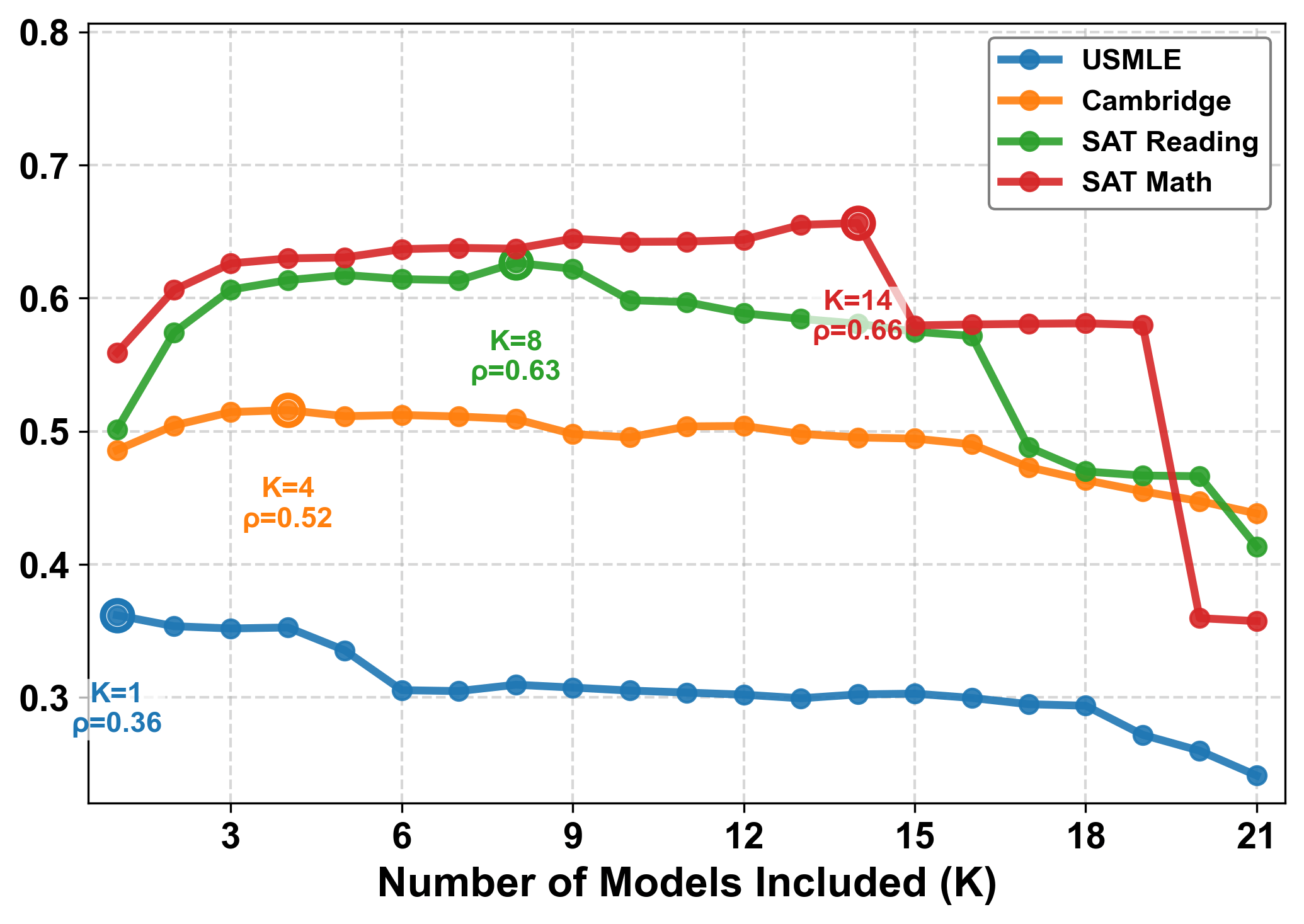
GPT-5를 포함한 최신 언어모델들이 시험 문제는 잘 풀지만 그 문제가 학생들에게 얼마나 어려운지는 전혀 모른다는 연구 결과. AI의 ‘지식의 저주’가 교육 기술에 미치는 영향을 살펴봅니다.
Written by
GPT-5 시대는 끝? 2026년은 중국발 Qwen이 주도한다
2025년 GPT-5가 실망을 안긴 사이 알리바바의 Qwen이 세계 2위 오픈 모델로 부상했습니다. 벤치마크 집착 대신 개방성과 실용성으로 승리한 이야기를 소개합니다.
Written by

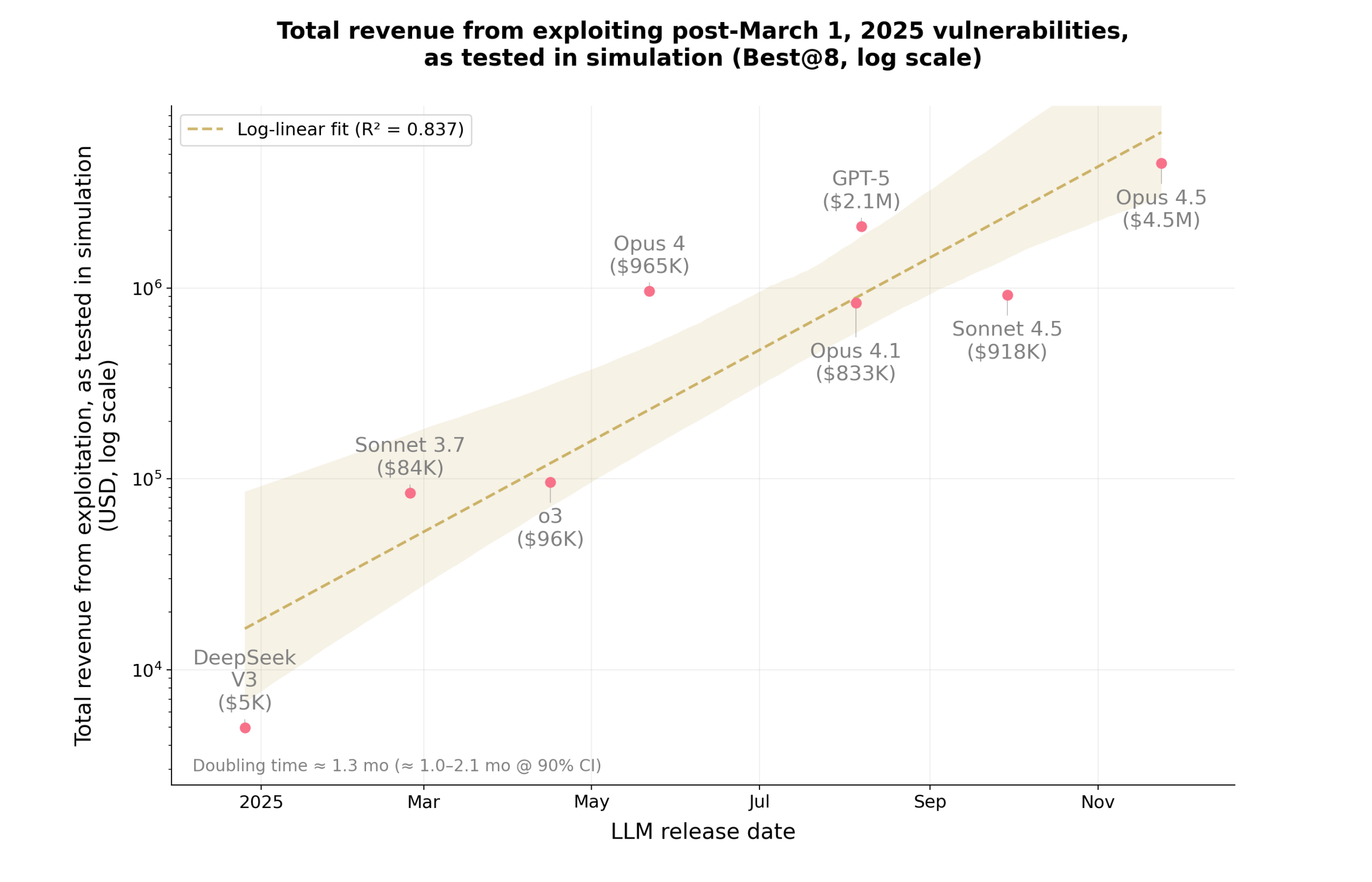
AI가 스마트 컨트랙트 해킹한다: Claude와 GPT-5, 460만 달러 취약점 발견
Anthropic과 MATS 연구에서 Claude와 GPT-5가 스마트 컨트랙트 취약점을 찾아 460만 달러 상당을 탈취. AI 공격 능력이 1.3개월마다 2배씩 증가하는 현실을 분석합니다.
Written by
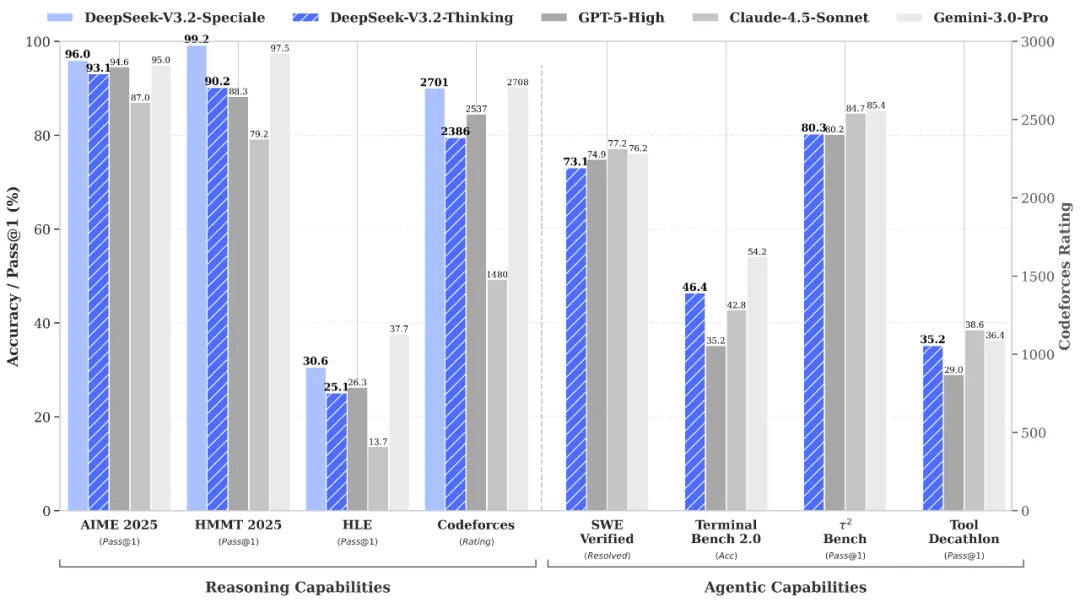
DeepSeek V3.2, 추론 비용 70% 낮춘 AI 모델로 GPT-5에 도전장
중국 DeepSeek가 추론 비용 70% 절감한 AI 모델 V3.2로 GPT-5에 도전장. 올림피아드 금메달급 성능을 MIT 라이선스로 무료 공개한 배경과 의미.
Written by
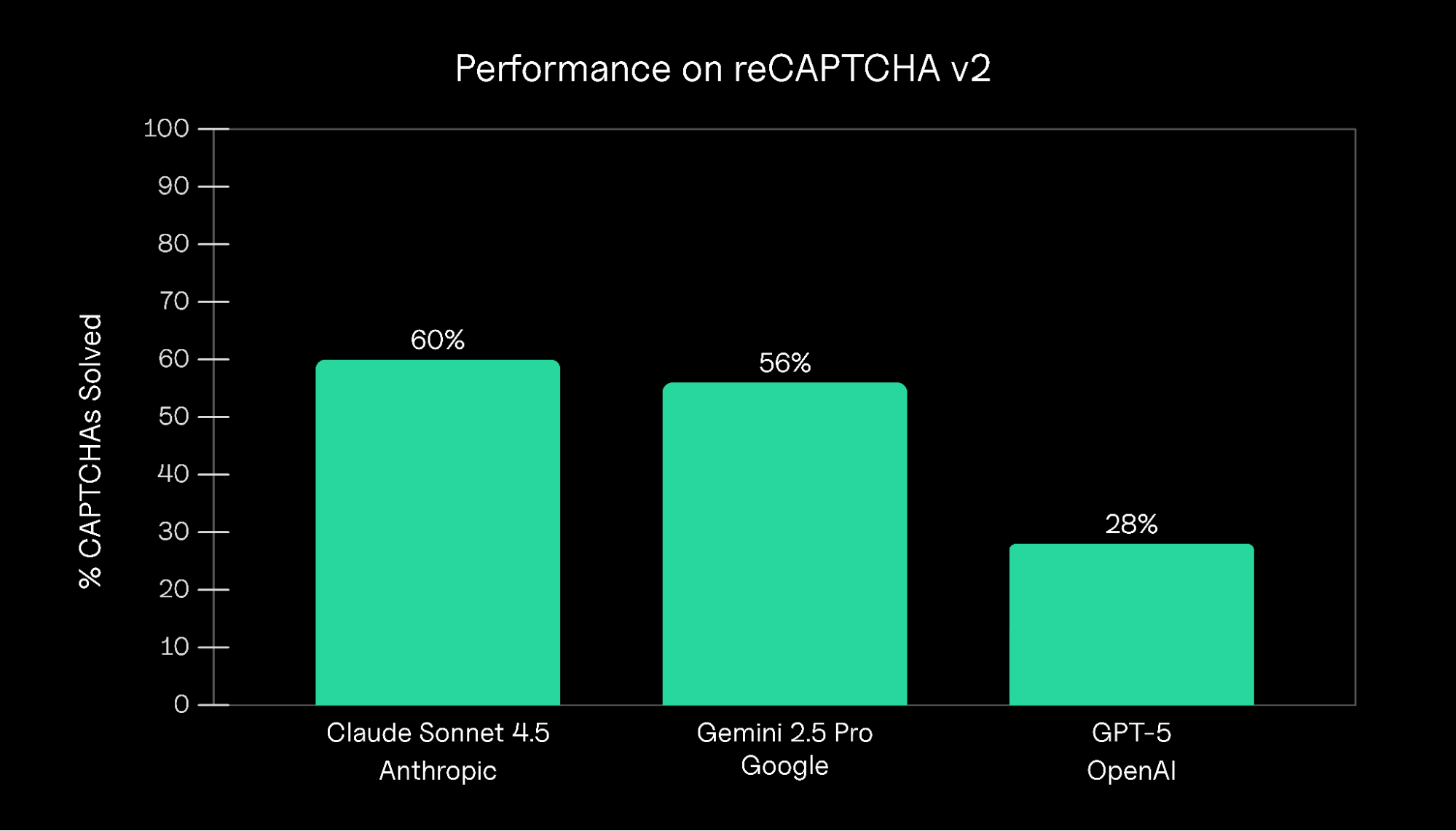
CAPTCHA의 종말?: Claude 60% vs GPT-5 28%, 과도한 추론이 실패를 부른다
최신 AI 모델들의 CAPTCHA 풀이 능력 벤치마크. Claude 60% vs GPT-5 28%, 과도한 추론이 오히려 실패를 초래하는 역설을 분석합니다.
Written by
Kimi K2 Thinking: 1조 파라미터로 GPT-5를 제친 오픈소스 모델의 비밀
중국 스타트업 Moonshot AI의 Kimi K2 Thinking이 GPT-5와 Claude를 제치고 추론 벤치마크 1위를 기록했습니다. 1조 파라미터 오픈소스 모델의 파괴적 가성비를 소개합니다.
Written by
AI 쇼핑 에이전트의 충격적 약점: 선택지가 많을수록 성능 급락
Microsoft Research가 AI 쇼핑 에이전트를 테스트한 결과, 선택지가 많을수록 성능이 급락하고 조작에 취약한 충격적 약점이 드러났습니다. AI 에이전트 경제의 실현 가능성을 다시 생각하게 하는 연구입니다.
Written by

매주 120만 명이 ChatGPT와 자살 상담: AI 정신건강 위기의 실체와 대응
OpenAI가 공개한 충격적 데이터 분석. 매주 120만 명이 ChatGPT와 자살 상담을 나누고 56만 명이 정신병 증상을 보이는 AI 정신건강 위기의 실체와 GPT-5 업데이트를 통한 대응 전략을 살펴봅니다.
Written by

GPT-5 기반 Aardvark, 취약점 92% 탐지하며 보안 연구의 새 기준 제시
OpenAI가 GPT-5 기반 자율형 보안 연구 에이전트 Aardvark를 공개했습니다. 벤치마크 테스트에서 92% 취약점 탐지율을 기록하며 인간 보안 연구자처럼 코드를 읽고 분석하는 새로운 접근 방식을 제시합니다.
Written by

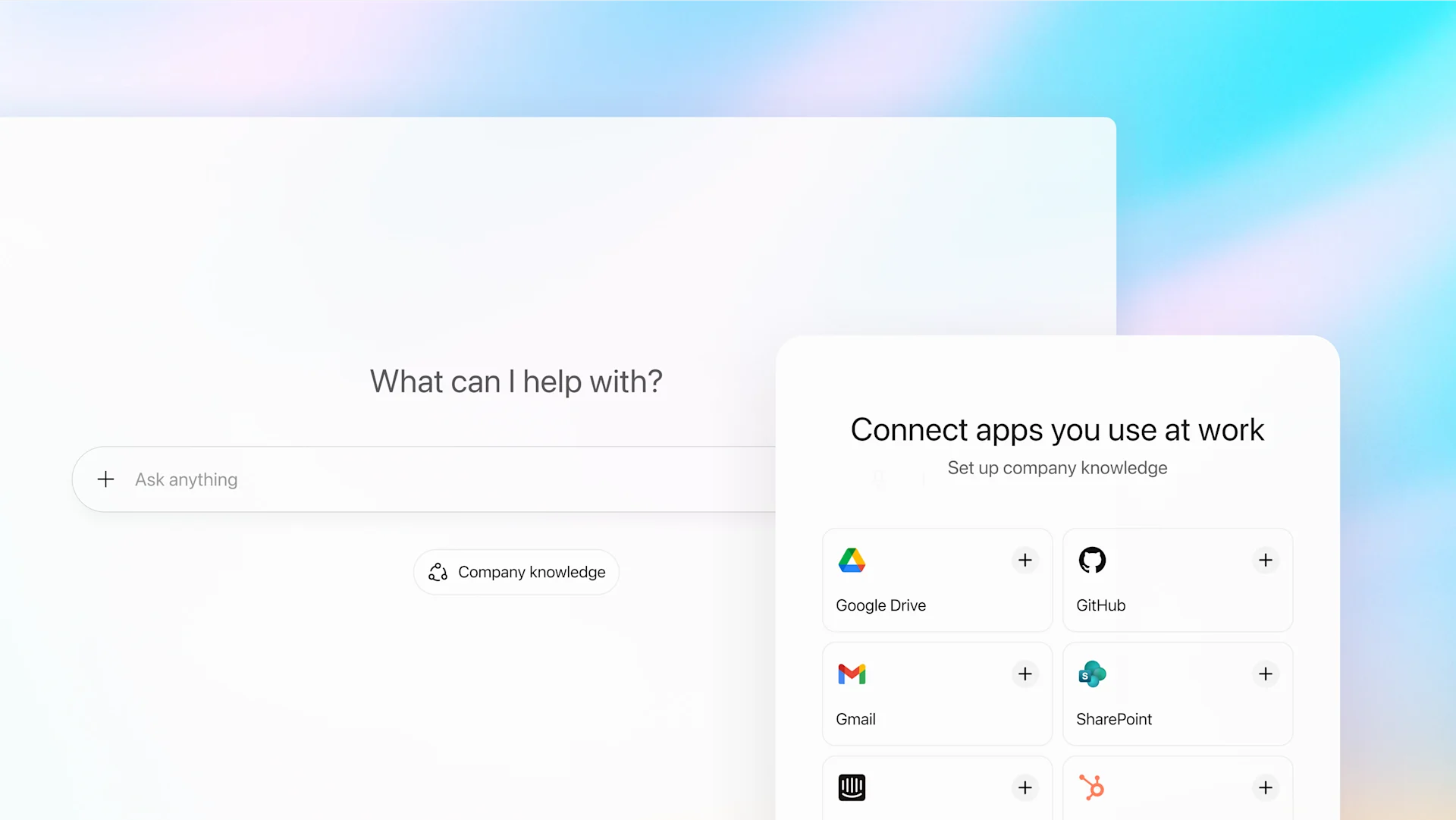
ChatGPT가 회사 전체 정보를 검색한다: GPT-5 기반 Company Knowledge 활용법
ChatGPT Company Knowledge로 Slack부터 GitHub까지 회사 전체 정보를 한 번에 검색하는 방법. GPT-5 기반 통합 검색과 실전 활용법 소개.
Written by