AI연구
2년 검증 통과한 암호 알고리즘, Claude가 60시간 만에 반쯤 뚫었다
미국 표준 후보로 2년간 전문가 검증을 통과한 암호 서명 알고리즘 HAWK, Claude Mythos Preview가 단 60시간 만에 붙잡고 키 강도를 절반으로 낮췄습니다. 구현 실수가 아니라 알고리즘 자체의 수학적 허점을 AI가 찾아낸 첫 사례라 더 눈에 띕니다. 축소판 AES 공격도 함께 공개된 Anthropic의 암호분석 실험을 정리했습니다.
Written by

LLM에 문제해결 요령 학습시켰더니 새 과제서 10% 향상
LLM에게 정답 대신 문제 해결 요령 자체를 학습시켰더니, 한 번도 본 적 없는 새 과제에서도 평균 10% 더 나은 성능을 냈다는 다기관 공동연구 논문을 소개합니다.
Written by
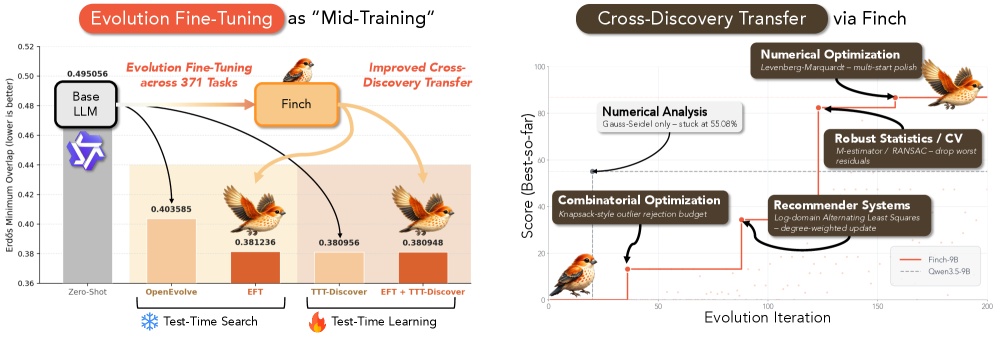
사람은 못 읽지만 AI는 알아듣는다, LLM끼리의 압축 언어 BabelTele
사람은 못 읽지만 AI는 알아듣는 초고밀도 표현 BabelTele. 원문의 27.9% 길이로 압축해도 의미 99.5%를 보존한 상하이교통대 연구를 소개합니다.
Written by
파일을 작게 만드는 도구가 어떻게 셰익스피어를 쓸까
압축과 예측이 수학적으로 같다는 DeepMind 연구와 gzip으로 텍스트를 생성한 실험을 통해, 언어모델을 압축기로 보는 새로운 관점을 소개합니다.
Written by

Sakana AI, AI 스스로 코드 고쳐 성능 높이는 RSI 연구소 정식 출범
Sakana AI가 AI 스스로 코드를 수정해 성능을 높이는 재귀적 자기개선(RSI) 전문 연구소를 출범했습니다. 컴퓨팅 군비경쟁의 대안이 될 수 있을지 주목됩니다.
Written by

AI 튜터가 법학 교수를 이겼다, 스탠퍼드 연구가 확인한 75% 우위
스탠퍼드 로스쿨 연구에서 AI 답변이 법학 교수 답변을 75%의 대결에서 앞섰습니다. 정답이 없는 판단 영역에서도 AI가 전문가 수준에 도달했다는 첫 엄밀한 증거를 소개합니다.
Written by

AlphaEvolve 1년 성과, AI가 수학 난제부터 TPU 회로까지 설계한 방법
Google DeepMind AlphaEvolve 출시 1년 성과 정리. 수학 난제 해결부터 TPU 회로 설계, 물류 최적화까지 알고리즘 진화 AI가 만들어낸 실질적 결과를 소개합니다.
Written by

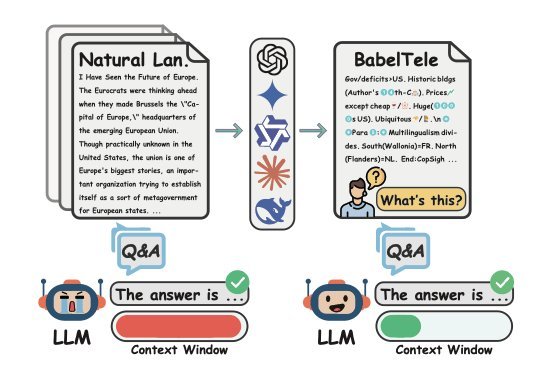
LLM이 문서에서 스스로 공부하는 법, Ctx2Skill 멀티에이전트 프레임워크
LLM이 전문 문서에서 스킬을 자동 추출·진화시키는 Ctx2Skill 프레임워크 소개. 파인튜닝 없이 어떤 모델에도 적용 가능한 멀티에이전트 셀프플레이 방식을 다룹니다.
Written by
ChatGPT 150만 대화 분석 결과, 대부분의 사람들이 쓰는 방식은 단 3가지
OpenAI와 하버드가 150만 대화를 분석한 결과, ChatGPT 사용의 75%는 정보 검색·실용 조언·글쓰기 세 가지에 집중됩니다. 사람들이 AI에게 가장 많이 하는 것은 ‘시키기’가 아니라 ‘묻기’였습니다.
Written by
GPT-5.5 등장, 프롬프트 4번으로 학술 논문이 나오는 시대
OpenAI가 출시한 GPT-5.5의 실제 성능을 분석합니다. 코딩, 학술 연구 사례와 함께 여전히 남아있는 한계까지 살펴봅니다.
Written by
