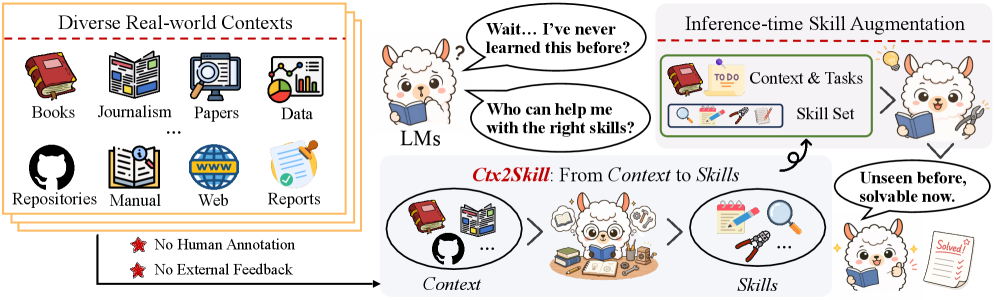
GPT-4.1에게 전문 문서를 통째로 줘도 정작 관련 문제는 11%밖에 못 푼다면, 그 문서를 “읽었다”고 할 수 있을까요? 청화대학교, UIUC, DeepLang AI 공동 연구팀이 이 문제를 정면으로 다룬 논문을 공개했습니다. 핵심은 단순합니다. 문서에서 스킬을 자동으로 추출해 모델에 꽂아주면 됩니다. 하지만 그 스킬을 어떻게 만드느냐가 문제였고, 연구팀은 멀티에이전트 셀프플레이로 이를 해결했습니다.

출처: From Context to Skills: Can Language Models Learn from Context Skillfully? – arXiv (2026.04)
LLM이 문서를 읽어도 왜 못 쓸까
LLM은 훈련 데이터에 없던 지식을 처리할 때 컨텍스트에 의존합니다. 새로운 제품 문서, 내부 규정, 실험 데이터 같은 것들이죠. 연구자들은 이 능력을 컨텍스트 학습(context learning)이라고 부릅니다.
문제는 컨텍스트 학습이 생각보다 잘 안 된다는 점입니다. 긴 문서를 프롬프트에 넣어줘도 모델은 표면적 검색에 그칠 뿐, 문서 속 규칙이나 절차를 깊이 이해해 새 문제에 적용하는 데는 약합니다. 의사가 새 가이드라인을 읽고 치료 방침을 바꾸거나, 엔지니어가 매뉴얼을 보고 절차를 실행하는 것처럼, 사람이 당연하게 하는 일을 LLM은 잘 못합니다.
한 가지 직관적인 해법이 있습니다. 문서에서 규칙과 절차를 자연어 스킬(skill)로 추출해 모델에 주입하는 것입니다. 스킬이란 재사용 가능한 절차적 지식을 담은 자연어 모듈로, 추론 시점에 LLM에 얹어 사용할 수 있습니다. 코딩 에이전트나 웹 내비게이션 에이전트에서 이미 효과가 검증된 방법입니다.
그런데 이걸 컨텍스트 학습에 적용하면 두 가지 벽에 막힙니다.
- 수작업 주석의 비용: 기존 스킬 라이브러리는 대부분 사람이 직접 만들었습니다. 수백 페이지짜리 전문 문서를 보고 고품질 스킬을 추출하는 건 인지적으로도, 경제적으로도 불가능합니다.
- 자동화의 피드백 부재: 코딩이나 수학 문제는 실행 결과나 정답 비교로 스킬 품질을 평가할 수 있습니다. 하지만 컨텍스트 학습 과제에는 그런 외부 신호가 없습니다. 추출한 스킬이 좋은지 나쁜지 판단할 기준이 없는 거죠.
셀프플레이로 스킬을 진화시키다
Ctx2Skill의 핵심은 멀티에이전트 셀프플레이 루프입니다. 외부 피드백 없이도 스킬을 자동으로 발견하고 다듬을 수 있는 구조입니다.
루프는 이렇게 돌아갑니다.
- Challenger가 문서와 자신의 스킬셋을 바탕으로 탐침 과제(probing task)와 채점 기준(rubric)을 생성합니다. 문서의 깊은 이해를 요구하는 문제를 만드는 역할입니다.
- Reasoner가 현재 스킬셋을 참고해 문서를 읽고 그 과제를 풀려 합니다.
- Judge가 Reasoner의 답변을 채점 기준으로 평가해 통과/실패 이진 피드백을 냅니다.
- 실패한 케이스는 Proposer→Generator 에이전트로 라우팅됩니다. 이들은 어떤 컨텍스트 지식이 빠졌는지 진단하고 Reasoner의 스킬을 업데이트합니다.
- 쉽게 통과한 케이스는 Challenger 쪽으로 라우팅되어 더 날카로운 과제 생성 전략에 반영됩니다.
두 진영이 서로를 압박하며 동시에 진화하는 구조입니다. 모델 파라미터는 전혀 건드리지 않고, 자연어 스킬 문서만 반복 수정합니다.
적대적 붕괴를 막는 Cross-time Replay
셀프플레이에는 치명적 위험이 하나 있습니다. 적대적 붕괴(adversarial collapse)입니다. 반복이 거듭될수록 Challenger가 점점 극단적인 문제를 내고, Reasoner의 스킬은 그 병리적 케이스에만 과적합됩니다. 결과적으로 스킬이 쌓일수록 오히려 일반화 능력이 떨어지는 역설이 생깁니다.
연구팀이 제안한 해법은 Cross-time Replay입니다. 매 반복마다 누적된 스킬셋 중 어느 시점의 것이 다양한 대표 케이스에서 가장 균형 잡힌 성능을 내는지를 추적합니다. 그리고 과적합이 시작되기 전, 균형점이 가장 좋았던 스킬셋을 Reasoner의 최종 스킬로 선택합니다. 가장 최근 스킬이 아니라, 가장 범용적인 스킬을 고르는 것입니다.
결과와 의미
CL-bench의 4가지 컨텍스트 학습 과제(도메인 지식 추론, 규칙 시스템 적용, 절차적 실행, 경험적 발견)에서 Ctx2Skill은 모든 백본 모델의 성능을 끌어올렸습니다. GPT-4.1은 11.1%에서 16.5%로, GPT-5.1은 21.2%에서 25.8%로 향상됐습니다.
절대 수치가 크지 않다고 느낄 수도 있습니다. 하지만 이 과제들은 단순 QA가 아니라 모든 채점 기준을 통과해야 정답으로 인정되는 고난도 구조입니다. 그리고 추가 학습도, 파인튜닝도 없이 자연어 스킬 삽입만으로 얻은 수치입니다. 어떤 LLM에도 플러그인처럼 꽂을 수 있다는 점도 실용적 의미가 큽니다.
더 넓은 시각에서 보면, 이 연구는 컨텍스트 자체가 학습 재료가 될 수 있음을 보여줍니다. 외부 데이터도, 사람 주석도 필요 없이 모델이 주어진 문서 안에서 스스로 무엇을 모르는지 발견하고 채우는 과정을 자동화한 것입니다.
논문은 CL-bench 전체 벤치마크 결과, ablation study, 그리고 각 에이전트의 세부 동작 분석을 포함합니다.
참고자료: Ctx2Skill GitHub
답글 남기기