에이전트설계
챗봇의 실패는 거기서 끝나지만, 에이전트의 실패는 이어진다
AI 에이전트 프로젝트가 반복적으로 실패하는 구조적 안티패턴을 정리. 도구 남발, 컨텍스트 로트, 쓰기 권한 관리까지 에이전트가 왜 이상하게 굴 때가 있는지 다룹니다.
Written by

에이전트 vs 파이프라인, AI 개발의 기본 선택지를 비교하다
LLM 프로그램을 파이프라인으로 짤 것인가, 에이전트로 짤 것인가. 맥락 수집·비용·안전성·미래 대응력 측면에서 두 방식을 비교하고 판단 기준을 제시합니다.
Written by

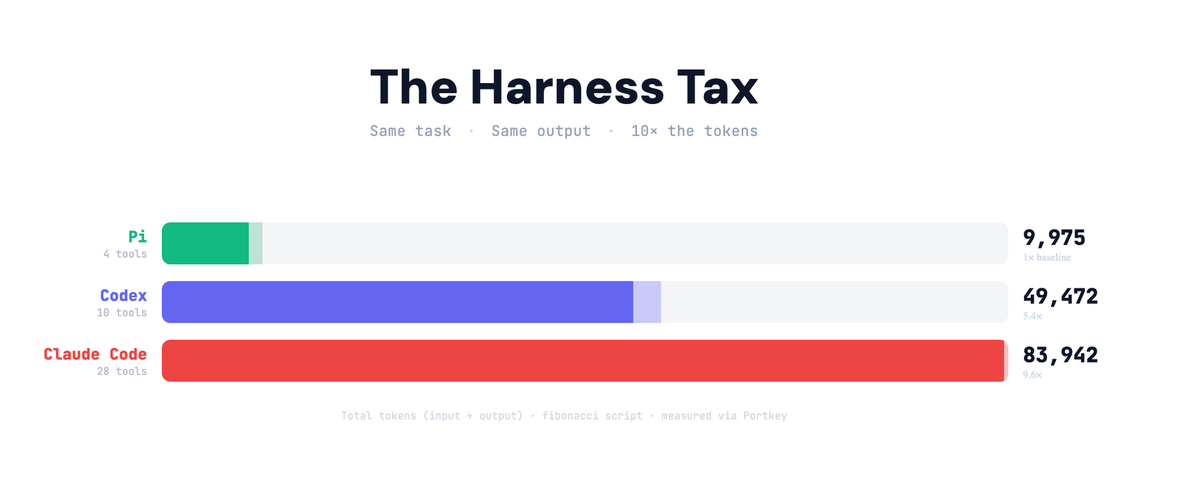
Claude Code vs Pi, 같은 작업에서 토큰 사용이 10배 차이 나는 이유
Claude Code와 Pi를 같은 작업으로 비교했더니 토큰 소비가 10배 차이. 에이전트가 자기 자신에게 쓰는 하네스 세금 개념을 설명합니다.
Written by
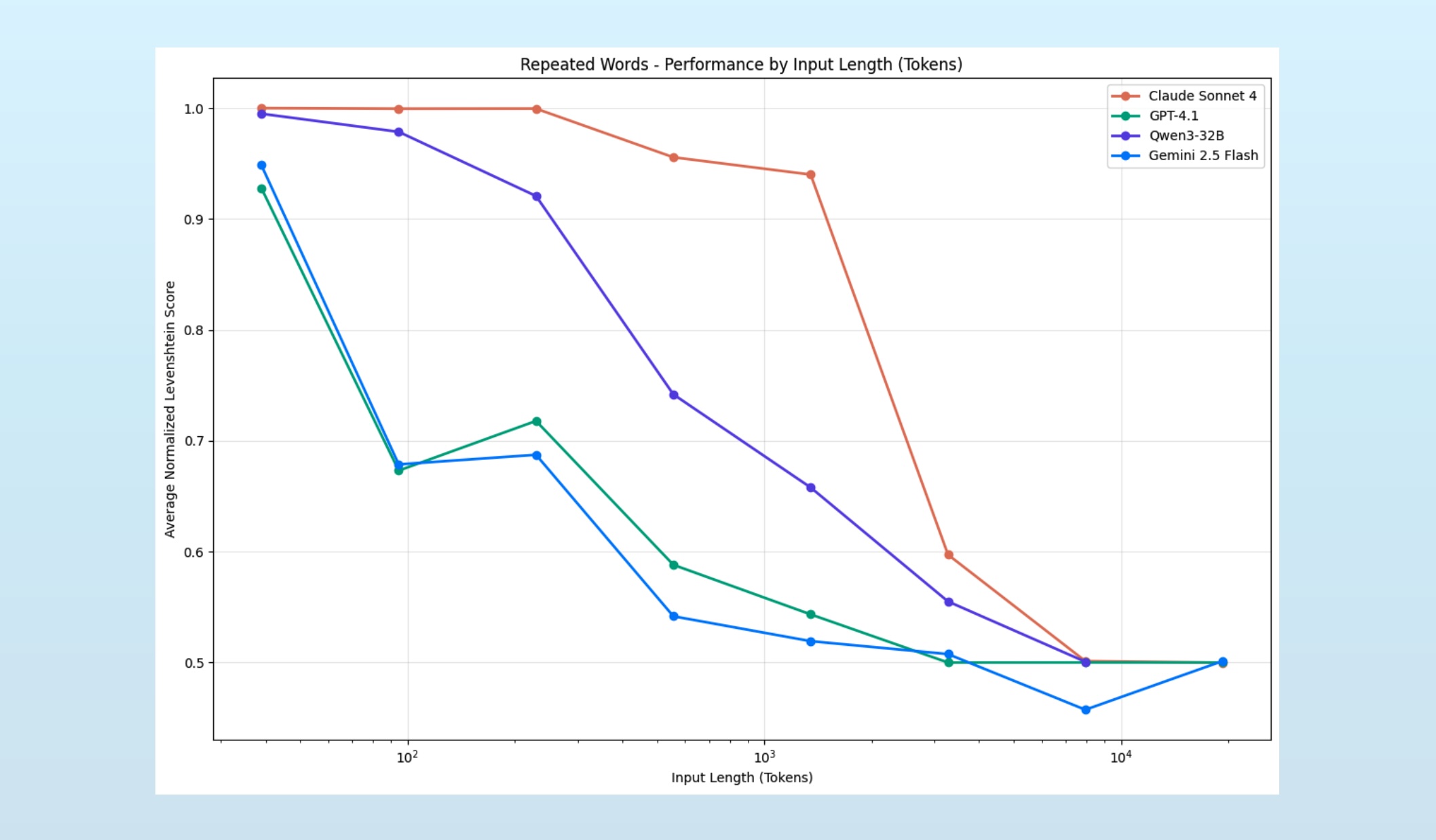
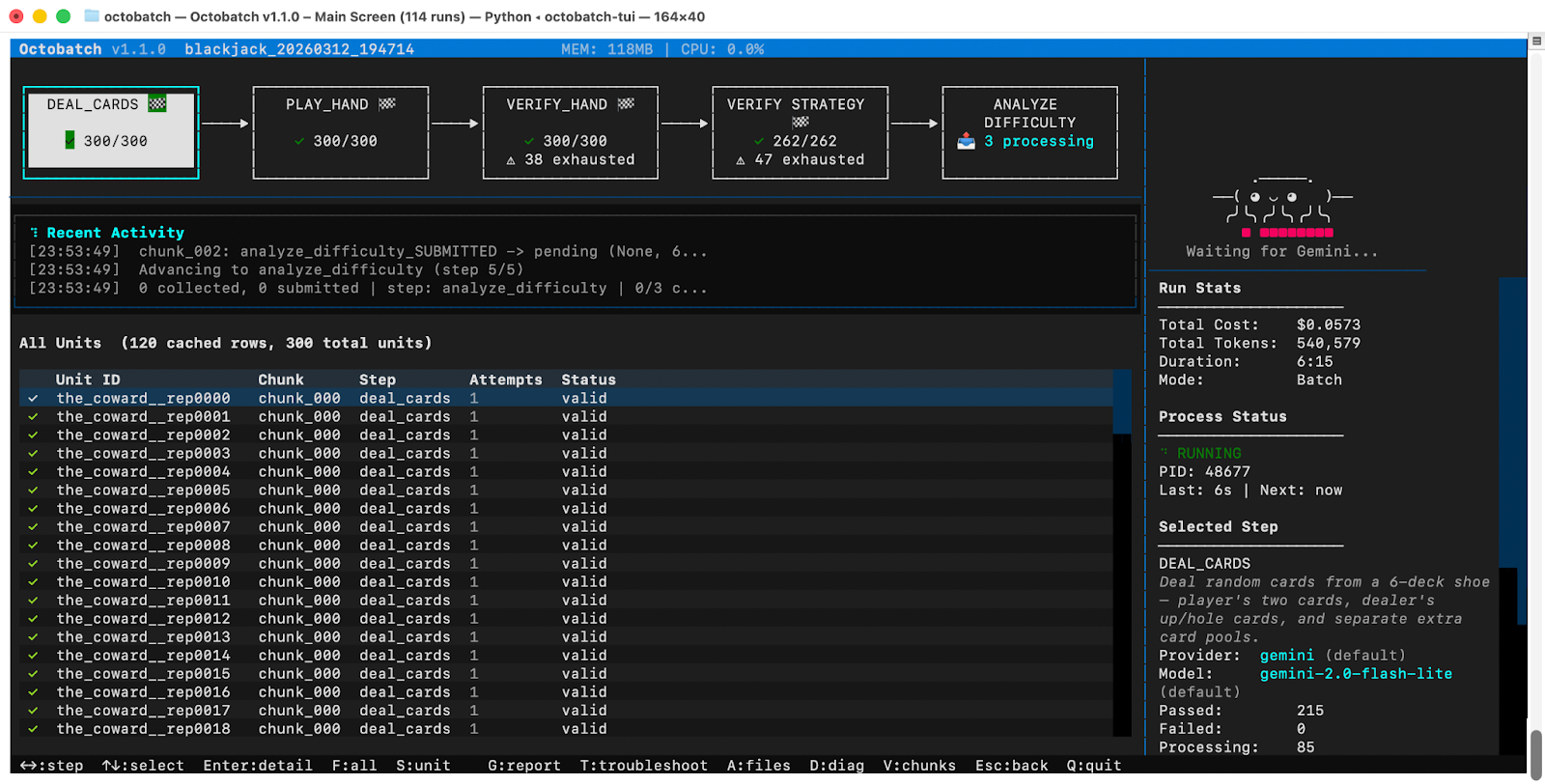
LLM 파이프라인 통과율 37%→94%, 블랙잭으로 증명한 설계 원칙
LLM 파이프라인 통과율을 37%에서 94%로 높인 블랙잭 실험 분석. “LLM이 할 수 있다”와 “LLM이 해야 한다”는 다르다는 설계 원칙을 데이터로 증명합니다.
Written by
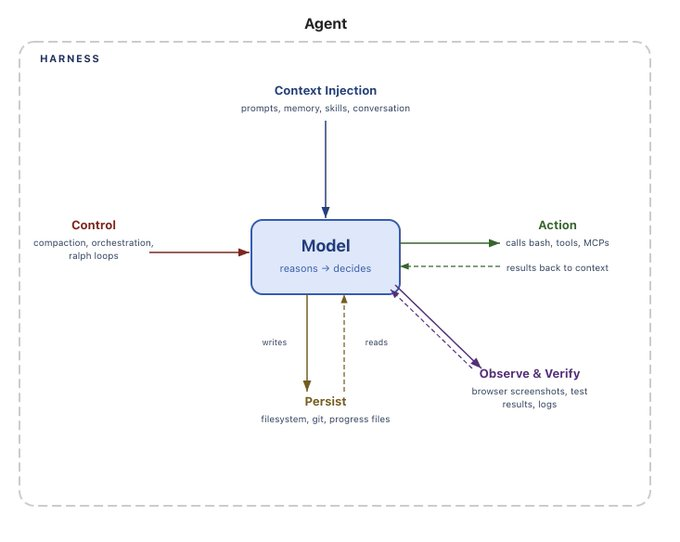
AI 에이전트 성능을 좌우하는 하네스 설계, LangChain이 정리한 핵심 구조
에이전트 성능을 결정하는 건 모델만이 아닙니다. LangChain이 ‘하네스’의 개념과 파일시스템·샌드박스·컨텍스트 관리 등 핵심 구성요소를 체계적으로 정리했습니다.
Written by
AI 에이전트 워크플로우 3가지 패턴, 언제 어떤 걸 써야 할까
AI 에이전트 워크플로우 3대 패턴(순차·병렬·평가자-최적화)의 작동 원리와 언제 어떤 패턴을 써야 하는지 실무 관점에서 소개합니다.
Written by

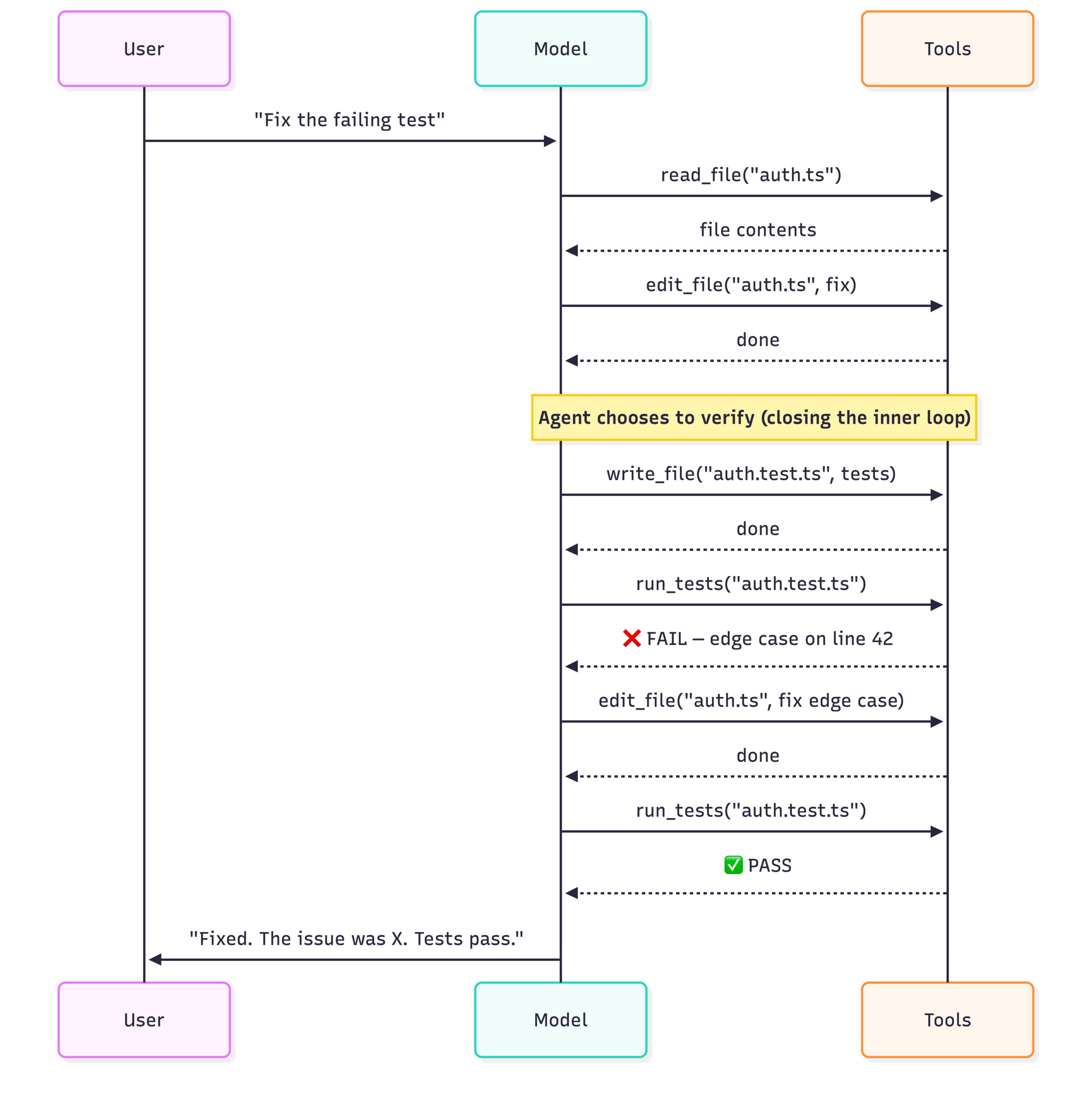
AI 에이전트 성능을 가르는 두 가지 설계 원칙, 이너 루프와 AGENTS.md
AI 에이전트 성능을 결정하는 이너 루프(자기 검증)와 아우터 루프(세션 간 학습), AGENTS.md 작성 원칙을 ETH 취리히 연구 데이터와 함께 소개합니다.
Written by
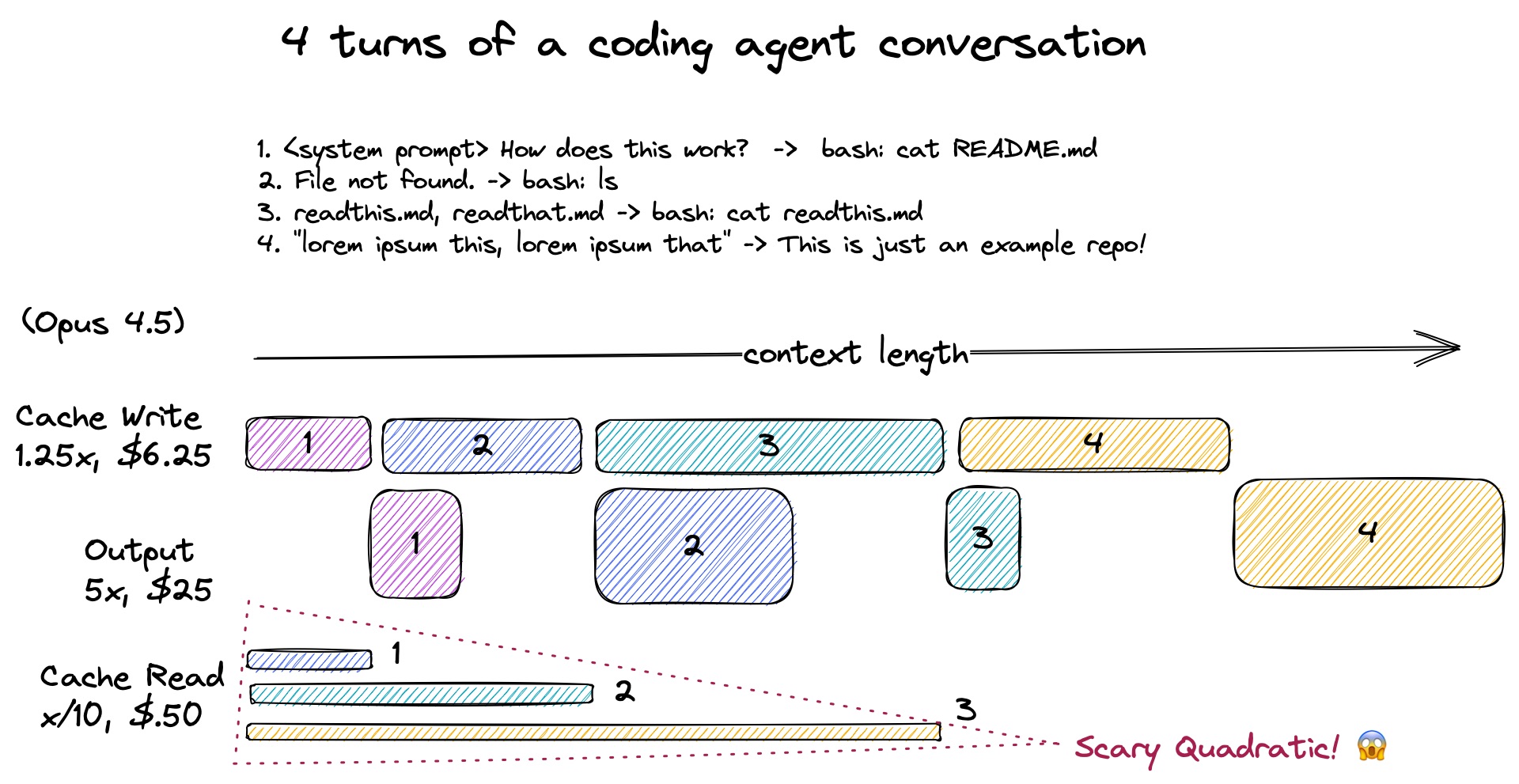
AI 코딩 에이전트 비용, 대화할수록 폭발하는 이유와 해결책
AI 코딩 에이전트는 대화가 길어질수록 캐시 읽기 비용이 2차 함수로 폭증합니다. 실제 250개 대화 데이터로 분석한 비용 구조와 그 원인을 소개합니다.
Written by
긴 컨텍스트 LLM의 숨겨진 함정, Context Rot 현상과 RLM 해결책
긴 컨텍스트를 처리할 때 LLM 성능이 저하되는 Context Rot 현상과, 이를 해결하는 RLM(Recursive Language Model) 접근법을 소개합니다.
Written by