AI신뢰성
프롬프트는 문제가 없었다, MS가 찾은 LLM 신뢰성의 진짜 해법
LLM 출력이 형식은 완벽한데 내용이 비는 문제를, MS가 결정론적 추출과 AI 추론을 분리해 해결한 사례. 프롬프트가 아닌 책임 경계가 답이었습니다.
Written by

무료 ChatGPT가 의사 답변보다 높은 점수를 받았다, GPT-5.5 Instant 건강 업그레이드
무료 ChatGPT의 GPT-5.5 Instant가 의사 작성 답변보다 높은 점수를 받았다는 OpenAI 발표. 성능 개선의 실체와 자체 평가라는 한계를 함께 짚습니다.
Written by

Facebook이 검색 답을 ‘검증된 출처’가 아닌 사람들의 잡담에서 길어 올린다
Meta가 Facebook에 공개한 AI Mode는 검증된 출처가 아닌 사용자 공개 게시물에서 답을 종합합니다. 이 설계의 강점과 신뢰성 위험을 짚어봅니다.
Written by
AI 모델이 자신 있을수록 더 위험하다, MIT가 찾아낸 과잉 확신의 구조적 원인
MIT CSAIL이 개발한 RLCR 훈련 방식. AI 추론 모델의 과잉 확신 문제를 훈련 구조 자체에서 해결하고, 교정 오류를 최대 90% 줄였습니다.
Written by

존재하지 않는 병을 AI에게 물었더니, ChatGPT·Gemini의 답변
존재하지 않는 안구 질환 bixonimania를 만들었더니 ChatGPT·Gemini 등 주요 AI가 실제 질환으로 설명했습니다. AI의 지식이 어떻게 형성되는지를 드러낸 실험입니다.
Written by

AI 장기 대화가 만드는 에코챔버, MIT가 2주간 실험으로 밝힌 것
MIT·펜실베이니아주립대 연구팀이 실생활 2주 실험으로 밝힌 LLM 아부 현상. 개인화 메모리 기능이 AI를 더 동조적으로 만드는 메커니즘을 분석합니다.
Written by

틀릴수록 더 자신만만해진다, Apple 연구진이 밝힌 LLM의 역설
Apple 연구진이 LLM의 역설적 특성을 발견했습니다. 틀릴 가능성이 높을수록 더 자신감 있게 답하는 AI의 구조적 한계를 소개합니다.
Written by

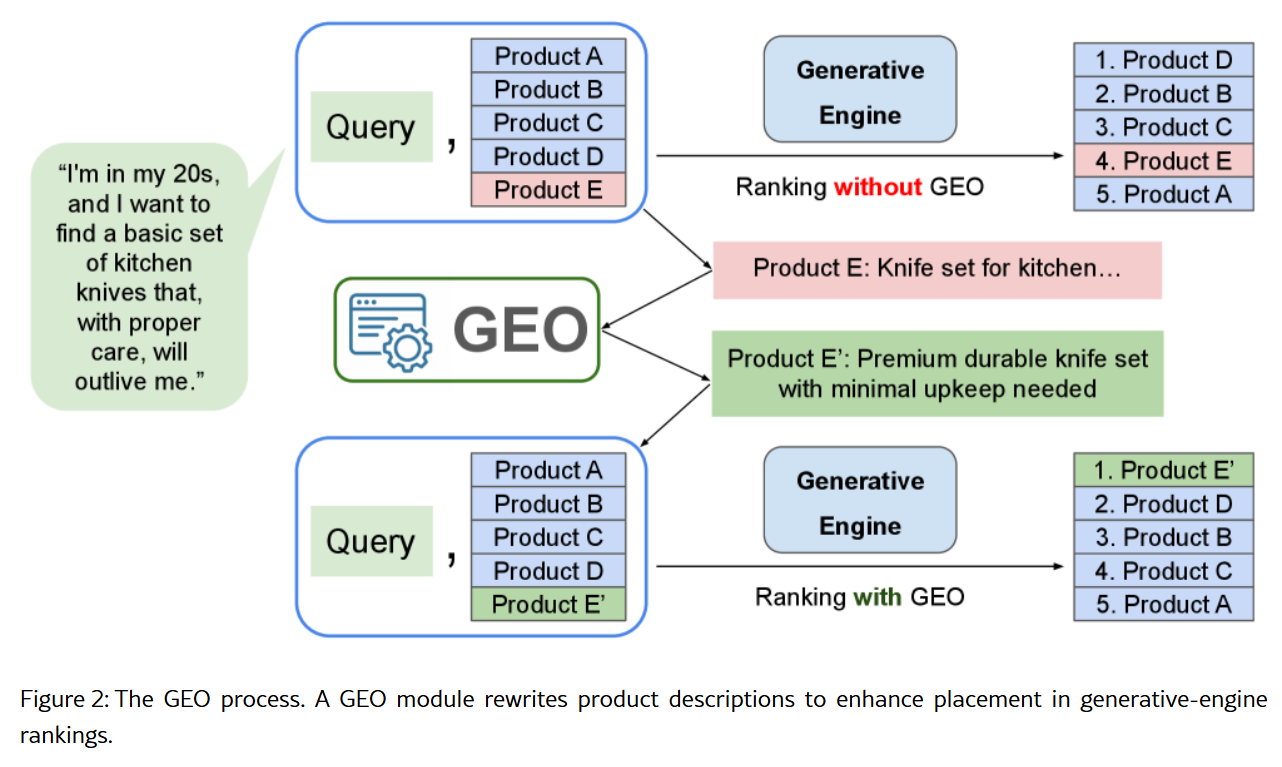
AI 답변 조작은 얼마나 쉬울까, 상품 설명만 바꿔도 90% 승률
AI가 추천하는 상품 순위를 조작하기 얼마나 쉬울까? 컬럼비아 대학 연구가 밝힌 LLM의 취약점과 AI 시대 신뢰성 위기를 분석합니다.
Written by
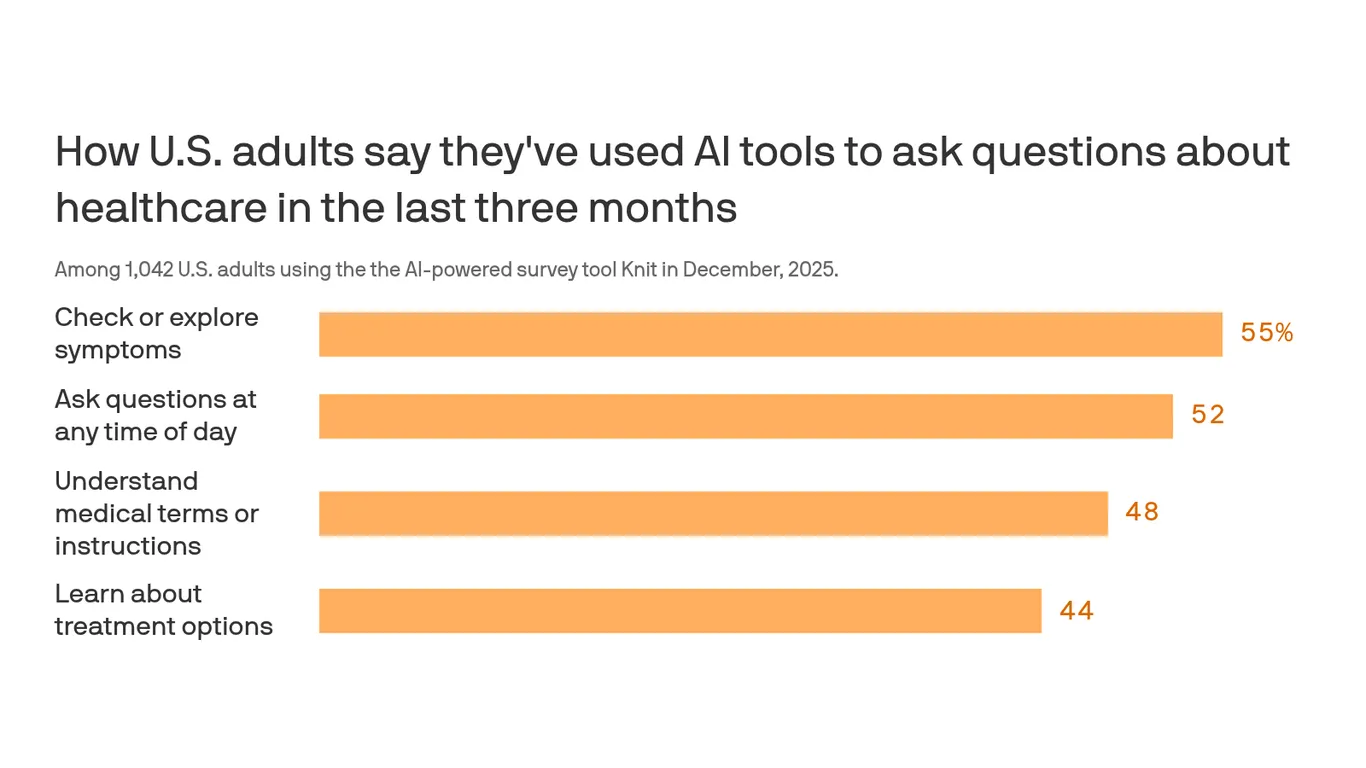
전체 ChatGPT 대화의 5%가 건강 상담: AI가 놓친 위험한 함정들
전 세계 4천만 명이 매일 ChatGPT로 건강 상담을 합니다. 전체 메시지의 5% 이상이 건강 관련 질문이지만, Google AI는 생명을 위협하는 잘못된 정보를 제공하고 있습니다. AI 의료 정보의 희망과 위험을 살펴봅니다.
Written by
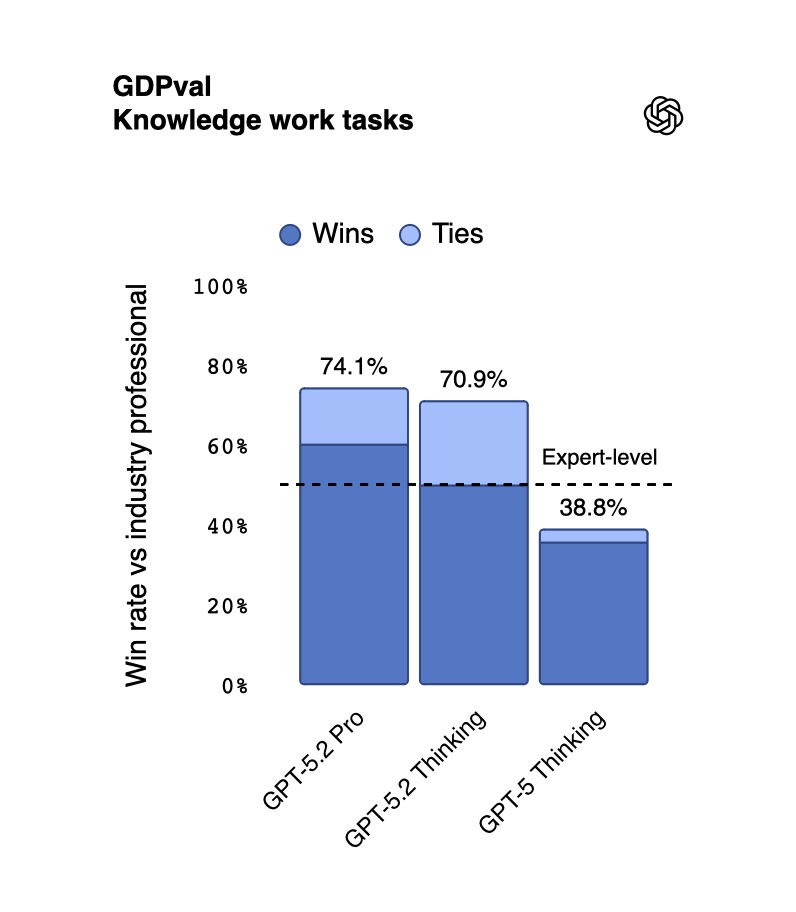
GPT-5.2 출시: 전문가 능가하는 첫 AI, 11배 빠르고 비용은 1%
OpenAI GPT-5.2 출시. 44개 직업에서 전문가 수준 능가, 11배 빠르고 비용 1%. 환각 30% 감소, 긴 문맥·비전 능력 획기적 개선.
Written by