LLM평가
내가 만든 AI 답변이 잘 나왔는지, G-Eval은 이렇게 채점한다
정답 없는 AI 출력을 사람 평가에 가깝게 채점하는 G-Eval의 원리와, LLM을 심판으로 쓸 때 따라오는 편향을 함께 짚어봅니다.
Written by

RAG가 그럴듯한 답을 내놓고도 틀리는 이유, 세 도구가 보는 방식
RAG가 그럴듯한 답을 내놓고도 틀리는 이유와, RAGAS·TruLens·DeepEval 세 평가 프레임워크가 이를 각각 다르게 잡아내는 철학을 다룹니다.
Written by
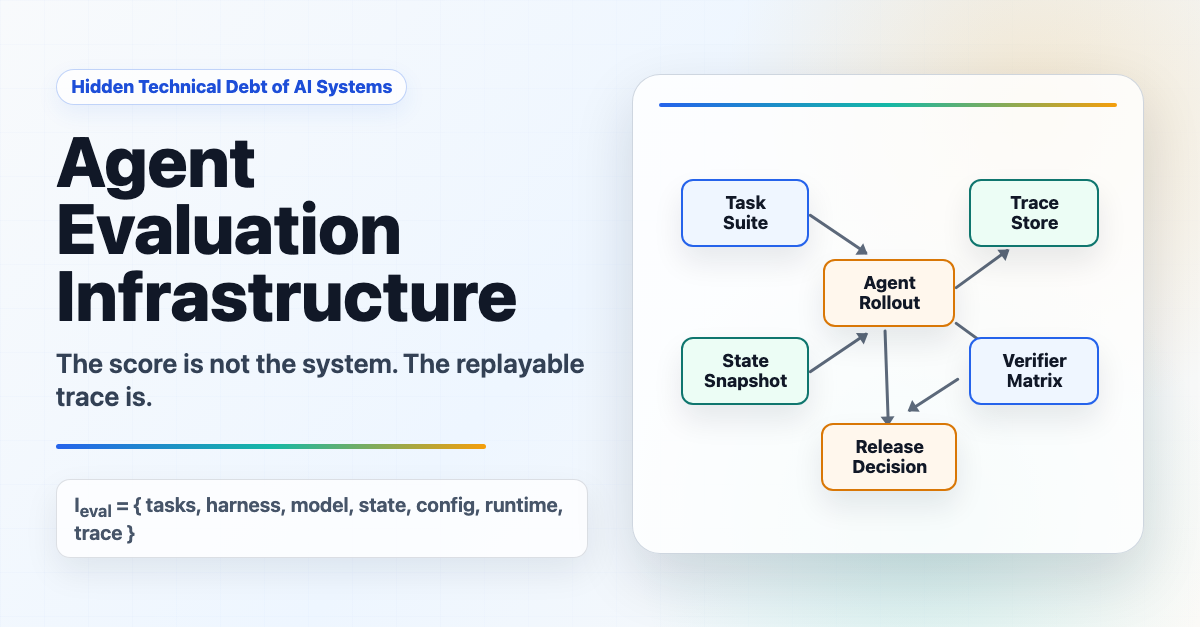
AI 에이전트 평가가 어려운 진짜 이유, 숨겨진 기술 부채
채팅 AI 평가와 달리 에이전틱 AI는 출력·트레이스·메모리·환경 상태 등 5가지 표면을 다루는 실험 제어 시스템이 필요합니다. 평가 부채가 어떻게 쌓이는지 소개합니다.
Written by
BrowseComp 1위 모델이 진짜 검색엔 꼴찌, AI 벤치마크의 치명적 맹점
AI 검색 에이전트가 실제로는 검색 없이 학습 기억에 의존해 BrowseComp 점수를 올린다는 연구. 기억을 차단한 LiveBrowseComp에서 순위가 완전히 뒤집히는 실험 결과를 소개합니다.
Written by

LLM eval에서 반복되는 5가지 함정, 데이터 사이언티스트라면 이렇게 다릅니다
LLM 시스템 평가에서 반복되는 5가지 함정과 데이터 사이언티스트적 접근법. eval 설계, 메트릭, 실험 설계 등 데이터 사이언스 역량이 LLM 시스템의 핵심인 이유를 소개합니다.
Written by

AI 에이전트, 프로덕션에 올리기 전에 반드시 알아야 할 것들
에이전트는 기존 소프트웨어와 다르게 모니터링해야 합니다. LangChain이 정리한 자연어 입력의 무한성과 LLM 비결정성 문제, 그리고 어노테이션 큐·LLM 평가자를 활용한 프로덕션 옵저버빌리티 전략을 소개합니다.
Written by
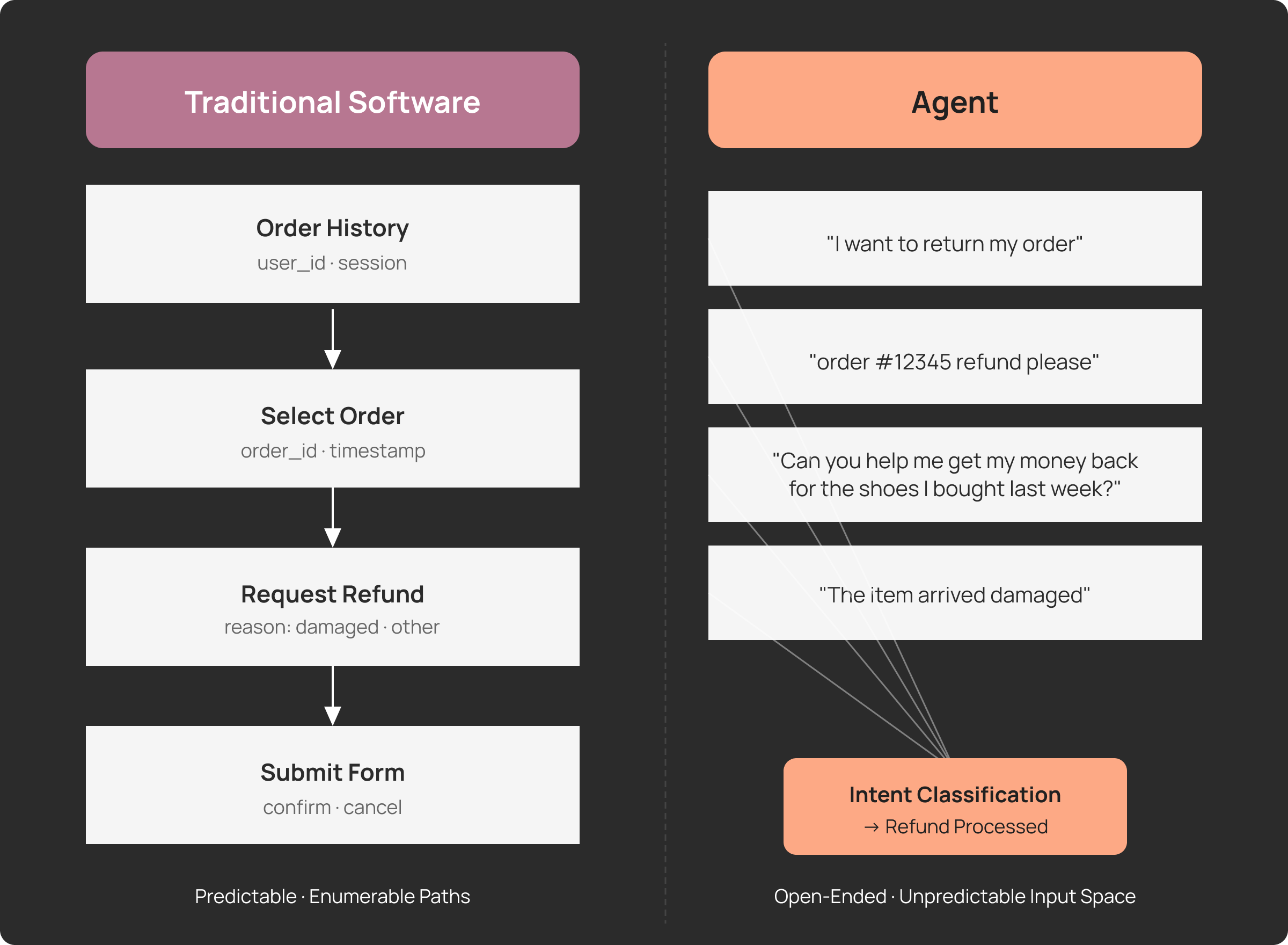
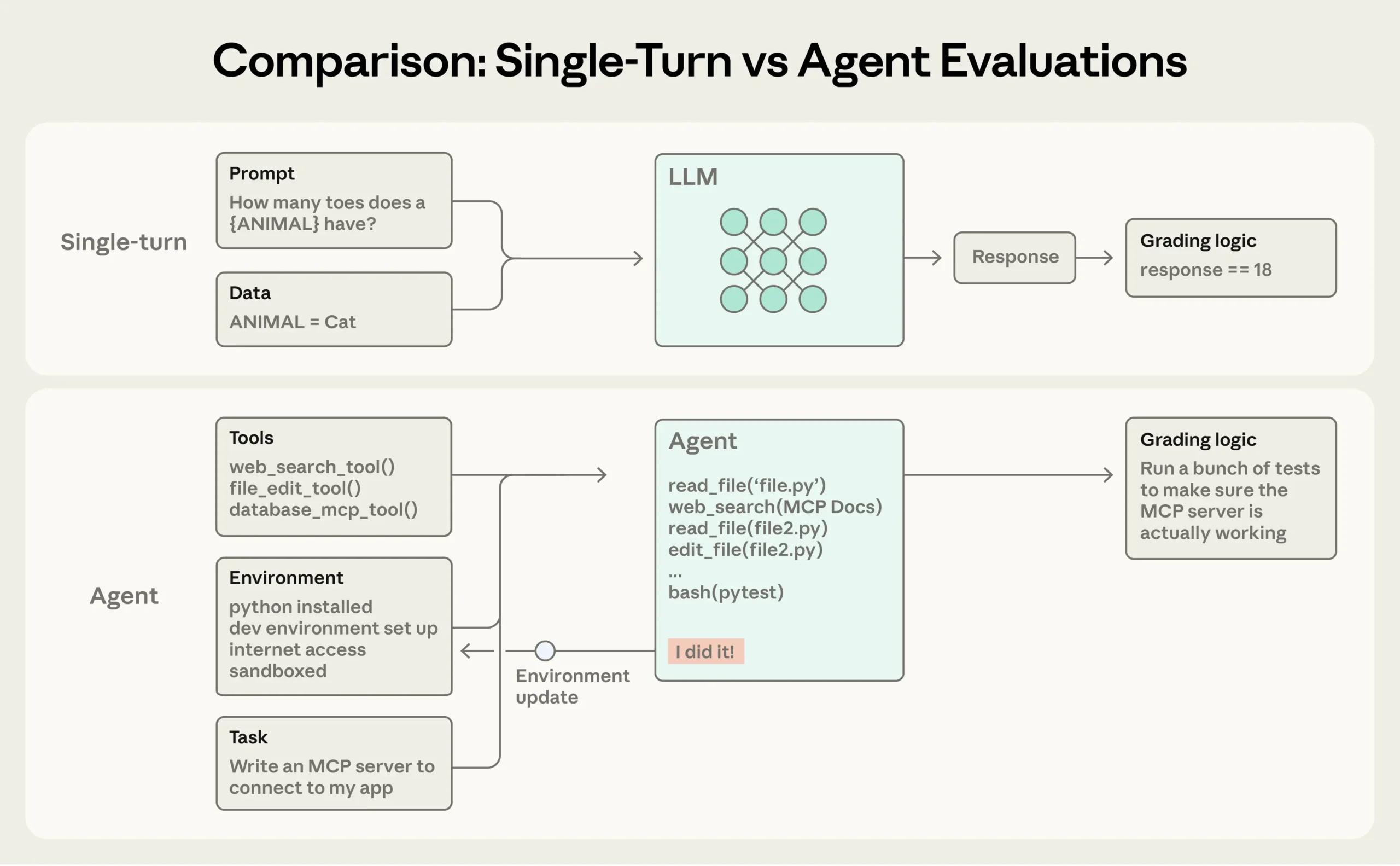
Claude Code 개발팀이 밝히는 AI 에이전트 평가의 모든 것
AI 에이전트 개발 시 평가 시스템을 어떻게 구축할까? Anthropic이 Claude Code 개발 경험을 바탕으로 공개한 실전 가이드. 에이전트 유형별 평가 전략과 20-50개 태스크로 시작하는 로드맵을 소개합니다.
Written by
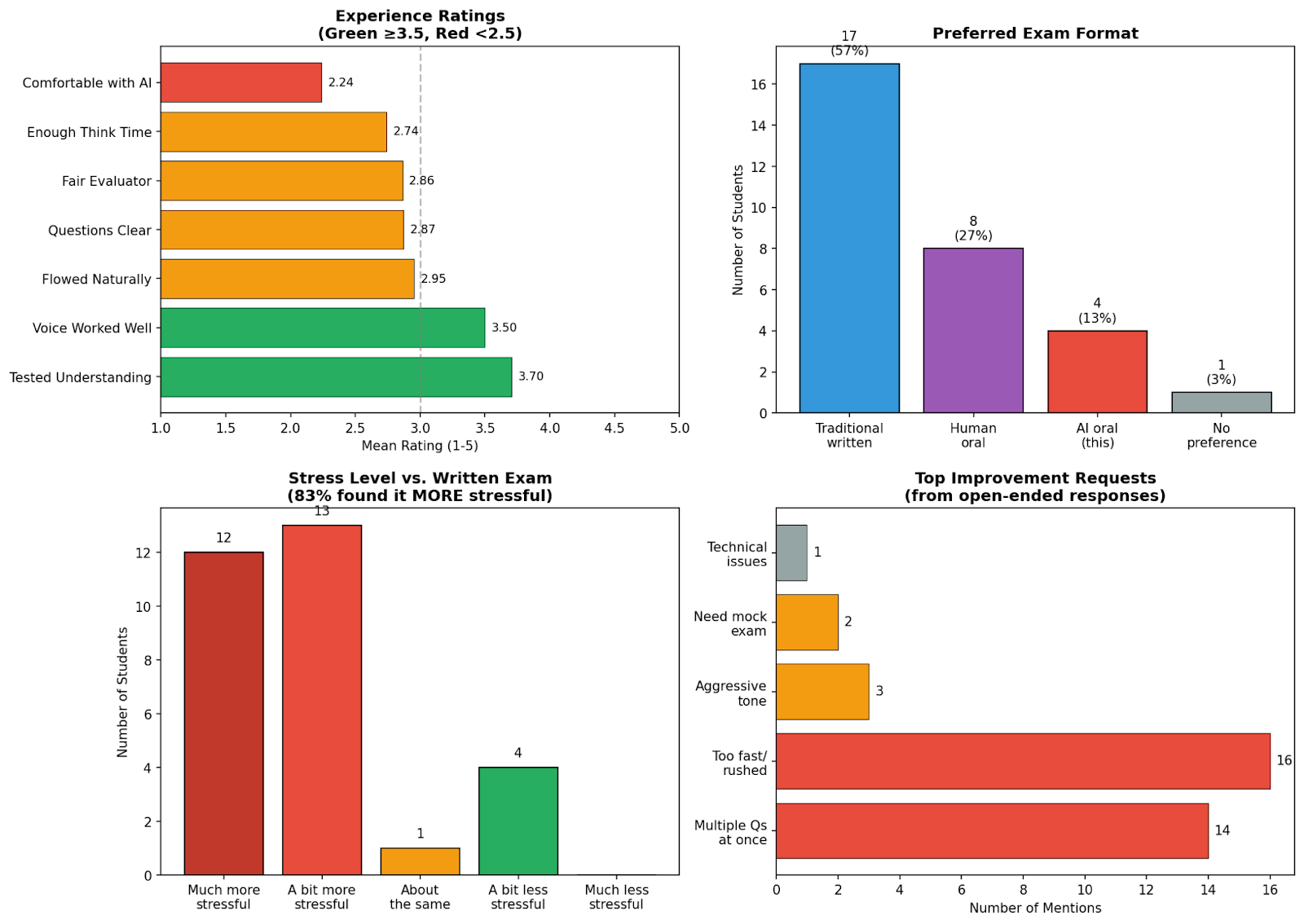
학생당 42센트로 AI 부정행위 잡기: NYU 교수의 AI 구술시험 실험
NYU 교수가 학생당 42센트로 AI 음성 에이전트 구술시험을 실시한 실험. AI 부정행위 시대의 현실적 평가 방법과 그 한계를 소개합니다.
Written by