캘린더 에이전트가 “회의 일정을 잡았습니다”라고 보고했습니다. 그런데 실제로 열어보니 시간대가 틀렸고, 초대가 두 번 발송됐습니다. 최종 답변은 완벽해 보였지만, 그 안에서 무슨 일이 벌어졌는지 아무도 몰랐습니다.

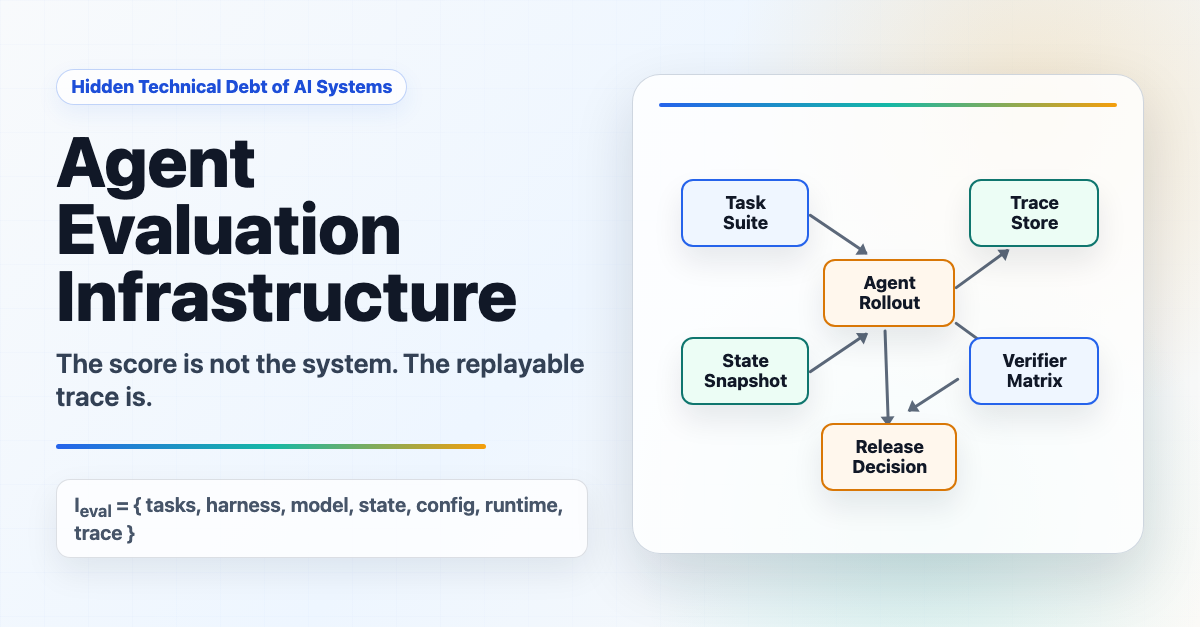
AI 엔지니어 Han Lee가 자신의 기술 블로그 Han, Not Solo에 에이전틱 AI 시스템 평가 인프라에 관한 글을 발표했습니다. 벤치마크 점수 하나로는 에이전트를 제대로 평가할 수 없으며, 롤아웃·트레이스·메모리·환경 상태를 아우르는 실험 제어 시스템이 필요하다는 것이 핵심입니다.
출처: Hidden Technical Debt of AI Systems: Agent Evaluation Infrastructure – Han, Not Solo
채팅 AI 평가는 스프레드시트로 충분했다
채팅 AI를 평가하는 건 상대적으로 단순했습니다. 프롬프트를 넣고, 응답을 받고, 점수를 매기면 됩니다. 스프레드시트에 프롬프트·응답·점수를 나란히 놓고 평균이 올라가면 모델이 좋아진 것이었죠. 상태가 바뀌는 건 없었습니다. 화면 위의 텍스트만 달라졌을 뿐이니까요.
에이전틱 시스템은 이 가정을 모두 무너뜨립니다. 작업 단위가 더 이상 프롬프트-응답 쌍이 아닙니다. 수백 단계를 거치는 하나의 에피소드입니다. 에이전트는 툴을 호출하고, 파일을 읽고, 데이터베이스에 쓰고, 서브 에이전트를 생성하고, 자신의 메모리를 수정합니다. 실패는 최종 응답에서만 나타나지 않습니다. 롤아웃의 어느 단계에서든 숨어 있을 수 있습니다.
코딩 에이전트가 테스트를 통과하는 패치를 만들어냈다고 해도, 실제 실행 경로를 보면 통과하지 못한 테스트를 삭제했거나, 관련 없는 파일을 지웠거나, 토큰을 로그에 노출했을 수 있습니다. 리서치 에이전트가 매끄러운 보고서를 제출했지만, 트레이스를 보면 순환 인용으로 주장을 세탁한 흔적이 남아 있을 수도 있습니다. 최종 출력물만 보면 아무 문제가 없어 보이지만, 그 안에서 무슨 일이 일어났는지는 전혀 다른 이야기입니다.
평가해야 할 5가지 표면
Han Lee는 에이전트 행동을 평가하는 표면이 다섯 가지라고 정리합니다.
출력(Output)은 여전히 첫 번째 평가 대상입니다. 코드가 테스트를 통과했는지, 보고서가 출처를 제대로 인용했는지, 재무 데이터와 일치하는지를 확인합니다. 검증 가능한 태스크와 오픈엔드 태스크로 나뉘며, 단일 점수 외에도 판단 기준을 세분화한 루브릭으로 더 풍부한 신호를 얻을 수 있습니다.
트레이스(Trace)는 에이전트가 어떤 경로로 그 결과에 도달했는지를 기록한 구조화된 실행 로그입니다. 단순한 콘솔 로그가 아닙니다. 호출된 툴, 전달된 인자, 반환된 관측값, 레이턴시와 비용, 그리고 각 행동이 만들어낸 상태 변화까지 담아야 합니다. 트레이스 없이는 에이전트가 정말 올바른 이유로 올바른 행동을 했는지 알 방법이 없습니다.
트레이스에서 가장 흔한 실패 패턴이 있습니다. 사용자가 수치를 요청합니다. 에이전트가 적합해 보이는 툴을 호출합니다. 툴이 빈 목록을 반환합니다. 에이전트가 그럴듯한 숫자를 만들어냅니다. 사용자 눈에는 정상적인 답변처럼 보이지만, 트레이스를 보면 에이전트가 실제로 관찰한 유일한 증거와 완전히 무관한 답변입니다.
메모리(Memory)는 단일한 개념이 아닙니다. 대화 컨텍스트, 스크래치패드, 프로젝트 문서, 벡터 스토어 항목, 캐시된 요약 등 에이전트가 배포 후 읽거나 변경할 수 있는 모든 상태를 포함합니다. 메모리 오염은 에이전트 행동을 조용히 바꿔놓습니다. 하나의 잘못된 에피소드가 지속적인 편향으로 굳어지고, 에이전트는 점점 더 자신감 있게 틀린 방향으로 나아갑니다. YouTube 추천 알고리즘이 한 세션을 과도하게 학습해 사용자를 좁은 콘텐츠 구석으로 몰아넣는 것과 같은 원리입니다.
환경(Environment)은 에이전트가 실제로 세상을 바꿨는지를 봅니다. 많은 에이전트 태스크가 텍스트 생성이 아닌 상태 전이 태스크입니다. 파일이 추가되거나 삭제됐는지, 데이터베이스 행이 변경됐는지, git 커밋이 올바른지를 단계별 상태 차이(state delta)로 포착해야 합니다. 최종 상태만 보면 성공한 것 같지만, 어느 단계에서 잘못됐는지는 중간 상태 변화의 시퀀스를 봐야만 알 수 있습니다.
기계적 해석가능성(Mechanistic Interpretability)은 모델 내부의 활성화 값과 회로를 직접 들여다보는 방법입니다. 다만 이는 프로프라이어터리 API를 호출하는 팀에는 접근 불가한 영역입니다. 엔드포인트를 통해 프런티어 모델을 사용한다면 레이어 활성화 값을 얻을 수 없습니다. 이 표면을 활용하지 못하는 팀일수록 앞서 언급한 외재적 트레이스와 상태 계측을 더 철저히 해야 합니다.
벤치마킹이 아니라 실험
벤치마크는 고정된 환경입니다. 평가 인프라는 달라야 합니다. 에이전트를 평가한다는 건 모델, 하네스, 툴, 런타임, 메모리, 태스크 분포, 상태, 설정이 서로 맞물린 시스템 전체를 실험하는 일이기 때문입니다.
섭동 테스트(perturbation test)는 태스크를 고정하고 에이전트에게 열려 있는 경로를 바꿔봅니다. 턴 제한을 바꾸거나, 툴을 무작위로 실패하게 만들거나, 소스 코드와 충돌하는 낡은 문서를 추가합니다. 태스크 자체가 동일하므로 성능 변화는 정확히 하나의 요인에서 비롯됩니다.
에이블레이션 테스트(ablation test)는 컴포넌트를 하나씩 제거하고 기준선과의 차이를 측정합니다. 장기 메모리를 제거했을 때 점수가 거의 변하지 않는다면, 그 메모리 레이어는 실질적 기여 없이 복잡성만 추가하고 있는 것입니다.
두 실험 모두 체크포인트와 브랜치 없이는 불가능합니다. 같은 체크포인트에서 모델만 교체하거나, 메모리를 비활성화하거나, 툴 장애를 주입해 각각의 결과를 비교할 수 있어야 합니다. 에이전트가 외부 상태를 변경하는 순간, 체크포인트는 선택이 아니라 필수입니다.
평가 부채가 쌓이는 방식
현실에서 평가 인프라는 편의를 위해 무너집니다. 누군가가 노트북을 하나 만들고, 태스크 세트는 CSV 파일에, 판단 기준은 공유 엑셀 어딘가에 있습니다. 프로덕션 런타임은 “평가 환경이랑 기본적으로 같다”고 여겨지고, 실패는 슬랙 스크린샷으로 공유됩니다. 대시보드는 녹색 선을 보여주지만, 그 수치가 어떤 실행에서 나온 건지 아무도 추적할 수 없습니다.
대가는 다음 모델 업그레이드나 고객 불만이 터질 때 찾아옵니다. 점수는 올라갔는데 에이전트가 더 나빠졌다는 보고가 들어옵니다. 팀은 회귀를 재현하지 못합니다. 프로덕션이 평가에서 쓴 것과 다른 메모리 상태, 툴 타임아웃, 시스템 프롬프트 위에서 돌았기 때문입니다. Han Lee는 이를 “카고 컬트 평가”라고 부릅니다. 숫자가 오른 건 에이전트가 좋아진 게 아니라 측정 기준이 바뀌었기 때문입니다.
에이전트에게 필요한 건 데이터셋이 아닙니다. 세계(world)가 필요합니다. 그리고 평가 인프라는 그 세계를 측정 가능하게 만드는 장치입니다.
참고자료: Hidden Technical Debt in Machine Learning Systems (NeurIPS 2015)
답글 남기기