과제물은 완벽했습니다. 그냥 “잘 쓴 과제” 수준이 아니라 “전문 컨설팅 회사의 보고서처럼 여러 번 다듬어진” 수준이었죠. 하지만 NYU 스턴 경영대학원의 Panos Ipeirotis 교수가 수업 중 학생들을 불러 질문하자, 놀라운 일이 벌어졌습니다. 자신이 제출한 과제의 기본적인 결정조차 두 번의 후속 질문 후에는 설명하지 못했거든요. 이 간극은 떨림 탓으로 돌리기엔 너무나 일관적이었습니다.
AI 시대, 전통적인 과제 평가 방식은 “죽었고, 끝났다”고 Ipeirotis 교수는 말합니다. 이제 학생들은 대부분의 시험 문제를 AI로 풀 수 있으니까요. 그래서 교수는 역발상을 시도했습니다. AI로 AI 부정행위를 잡는 것이죠.

NYU 교수 Panos Ipeirotis가 AI/ML 제품 관리 수업에서 음성 AI 에이전트를 활용한 구술시험을 실시했습니다. 36명의 학생을 대상으로 한 이 실험은 총 15달러, 학생당 42센트의 비용이 들었고, 학생들의 지식 격차뿐 아니라 교수 자신의 교수법 문제까지 드러냈습니다.
출처: NYU professor fights AI cheating with AI-powered oral exams that cost 42 cents per student – THE DECODER
학생당 42센트, 인간 채점의 50분의 1 비용
구술시험은 실시간 사고와 실제 결정에 대한 방어를 요구하지만, 대규모 수업에서는 물리적으로 불가능합니다. AI가 사람보다 일관성 있게 면접을 진행한다는 연구에서 영감을 받은 Ipeirotis 교수와 공동 강사 Konstantinos Rizakos는 ElevenLabs Conversational AI로 구축한 음성 에이전트로 기말시험을 치렀습니다.
시험은 두 부분으로 구성됐습니다. 먼저 에이전트가 학생의 최종 프로젝트에 대해 목표, 데이터, 모델링 결정, 평가, 실패 모드를 물었습니다. 그다음 수업에서 다룬 케이스 중 하나를 선택해 관련 질문을 했죠.
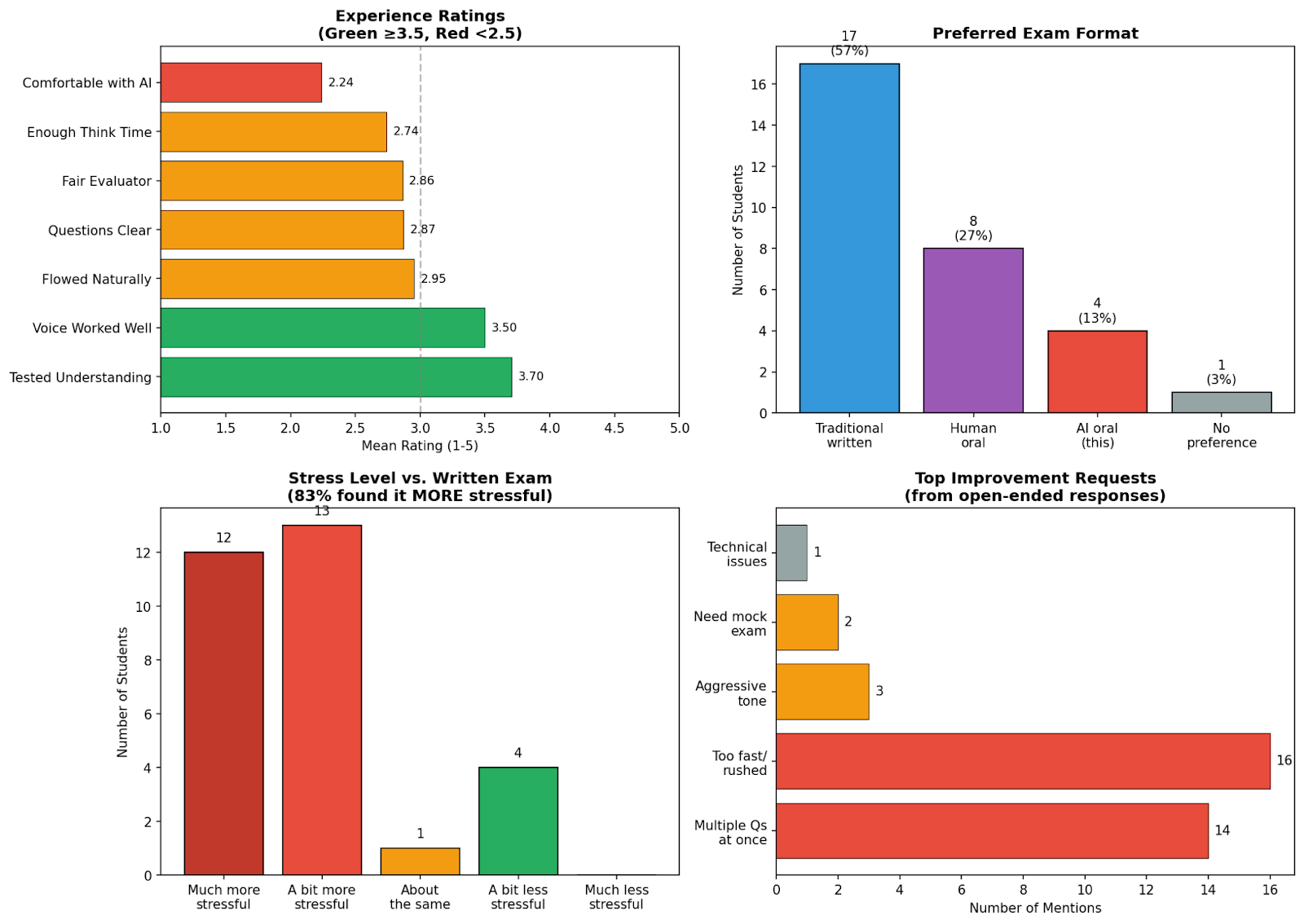
9일간 36명의 학생이 평균 25분씩 시험을 치렀습니다. 총 비용은 15달러였습니다. 주요 평가자인 Claude에 8달러, Gemini에 2달러, OpenAI에 30센트, ElevenLabs에 약 5달러가 들었죠. 학생당 42센트입니다.
비교해보면, 36명 × 25분 × 2명의 인간 채점자 = 30시간의 작업입니다. 시간당 25달러의 조교 임금으로 계산하면 750달러죠. 학계에서는 이 비용 차이가 구술시험 실시 여부를 결정하는 경우가 많다고 Ipeirotis 교수는 말합니다.
초기 버전은 위협적이었고, “랜덤”은 88%가 같은 선택
첫 버전에는 문제가 있었습니다. 일부 학생들은 에이전트의 엄격한 톤에 불만을 제기했어요. 교수들은 동료의 목소리를 복제했는데, 학생들은 그것이 “강렬하고” “거만하다”고 느꼈습니다. 한 학생은 “에이전트가 저한테 소리를 질렀어요”라고 이메일을 보냈죠.
다른 문제들도 있었습니다. 에이전트는 여러 질문을 한 번에 했고, 요청받았을 때 그대로 반복하는 대신 다르게 표현했으며, 멈춤 중에 너무 빨리 끼어들었습니다.
특히 흥미로운 문제는 무작위성이었습니다. 시험에는 여러 케이스 스터디가 있었는데, AI에게 “이 중에서 무작위로 하나를 골라 질문하라”고 지시했거든요. 그런데 AI는 88%의 경우 ‘Zillow’라는 특정 케이스만 골랐습니다. 교수가 프롬프트에서 Zillow를 아예 빼버리자, 이번엔 21번의 테스트 중 16번이나 ‘예측 치안’ 케이스를 선택했죠. 진정한 무작위가 아니라 특정 선택지에 편향된 겁니다.
“LLM에게 ‘무작위로 선택하라’고 요청하는 것은 사람에게 ‘1과 10 사이의 숫자를 생각하라’고 요청하는 것과 같습니다. 7을 많이 얻게 될 거예요.” Ipeirotis 교수는 이것이 훈련 데이터의 인간 편향에서 비롯된 잘 알려진 현상이라고 설명합니다.
3개 AI 모델이 서로 비판하며 채점
채점은 Andrej Karpathy의 “Council of LLMs” 접근법을 따랐습니다. Claude, Gemini, ChatGPT 세 모델이 먼저 각 시험 기록을 독립적으로 평가한 다음, 서로의 평가를 검토하고 자신의 평가를 수정했습니다.
초기 합의는 좋지 않았습니다. Gemini는 평균 20점 만점에 17점을 줬고, Claude는 13.4점만 줬죠. AI 간 상호 검토 후 60%의 평가가 1점 이내로 수렴했고, 29%는 정확히 일치했습니다. Gemini는 Claude가 특정 격차를 비판한 것을 본 후 평균 2점씩 점수를 낮췄습니다.
AI가 생성한 피드백은 인간 채점자를 능가했다고 Ipeirotis 교수는 말합니다. 강점과 약점을 구조화된 요약으로 정리했고, 시험에서 직접 인용한 문장을 포함했거든요.
주제별 분석은 교수법 자체의 격차도 드러냈습니다. “실험”에서 학생들은 평균 4점 만점에 1.94점을 받았는데, “문제 정의”의 3.39점과 대조됩니다. 세 명의 학생은 이 주제를 전혀 논의하지 못했고, 만점을 받은 학생도 없었습니다. Ipeirotis 교수는 수업이 A/B 테스팅 방법론을 소홀히 했다고 인정합니다. “외부 채점자가 있어서 무시할 수 없었어요.”
또 다른 발견: 시험 길이와 성적은 상관관계가 없었습니다. 가장 짧은 9분 시험이 최고 점수를 받았고, 가장 긴 64분 시험은 평범한 성적이었습니다.
스트레스는 높지만 공정하다는 평가
학생 설문조사는 엇갈린 반응을 보였습니다. AI 형식을 선호한 학생은 13%에 불과했고, 인간 구술 시험관을 선호한 학생이 두 배였습니다. 83%는 AI 시험이 필기시험보다 더 스트레스가 심하다고 느꼈죠. 하지만 약 70%는 시험이 실제 이해도를 평가한다는 데 동의했고, 이것이 설문에서 가장 높은 평가를 받은 항목이었습니다.
구술시험은 확장이 불가능해지기 전까지는 표준이었다고 Ipeirotis 교수는 요약합니다. AI가 다시 실용적으로 만들었죠. 전통적인 시험에 비해 한 가지 장점은 학생들이 설정을 연습할 수 있다는 것입니다. 질문이 매번 새로 생성되니까요. 유출된 시험 문제는 더 이상 문제가 되지 않습니다.
이 실험은 AI가 교육 평가를 어떻게 바꿀 수 있는지 보여주는 동시에, 그 한계도 솔직하게 드러냅니다. 완벽하지 않지만 확장 가능하고, 무엇보다 저렴하죠. AI 시대의 부정행위 문제에 대한 해법이 또 다른 AI라는 아이러니가, 어쩌면 가장 현실적인 답일지도 모릅니다.
참고자료:
- Fighting Fire With Fire: Scalable Oral Exams Using AI Voice Agents – Ipeirotis 교수 블로그 원문
- LLM Council – Andrej Karpathy의 GitHub 저장소
- Voice Agent Prompts – GitHub Gist
- Grading Panel Prompts – GitHub Gist
답글 남기기