오픈소스AI
중국 오픈웨이트 AI 무료로 쓸 수 있는데, 백도어 걱정은 안 해도 될까
중국 오픈웨이트 AI의 백도어·편향 우려를 개인이 도구를 고를 때 실제로 봐야 할 기준으로 재구성했습니다. 핵심은 국적이 아니라 검증 가능성입니다.
Written by

AI 모델 격차는 사라졌는데.. 승부는 다른 데서 갈렸다
오픈-폐쇄 모델 성능 격차는 좁혀졌는데, 진짜 승부는 하네스와 벤더 이탈 가능성에서 갈리고 있다는 Mozilla 리포트 분석입니다.
Written by

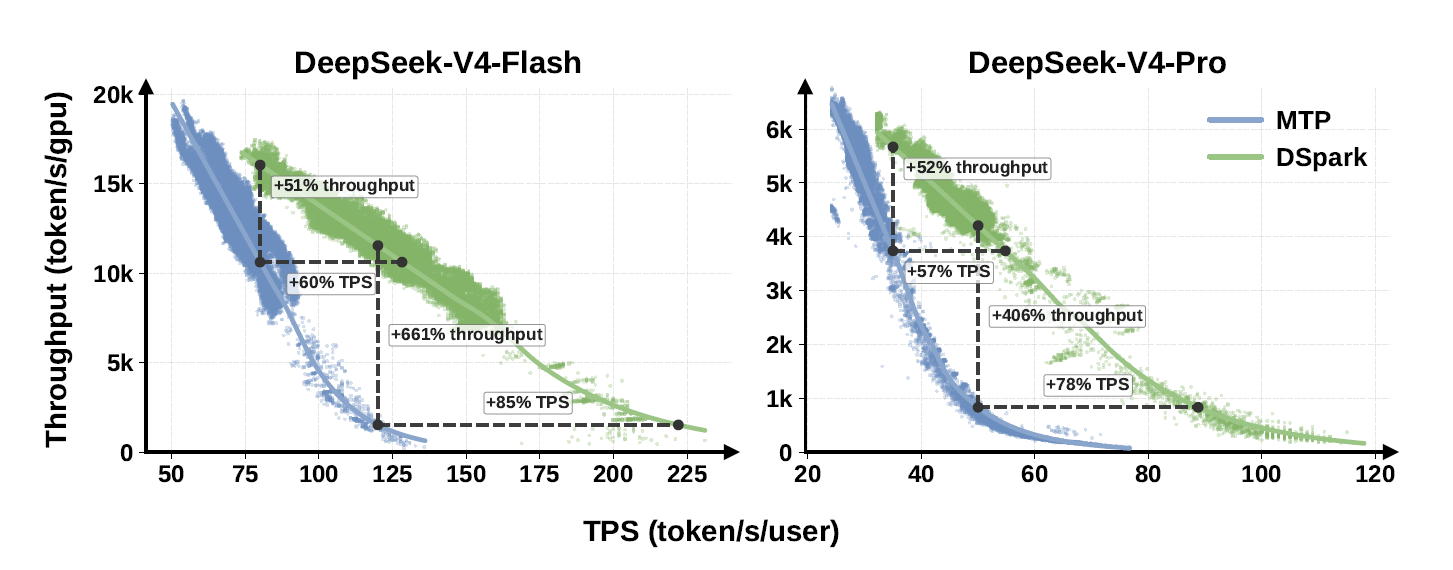
DeepSeek DSpark, 하드웨어 안 바꾸고 AI 응답속도 85% 올린 방법
DeepSeek가 공개한 추론 최적화 프레임워크 DSpark, 하드웨어 교체 없이 응답 속도 최대 85% 개선. 오픈소스 코드까지 공개한 이유를 짚어봅니다.
Written by
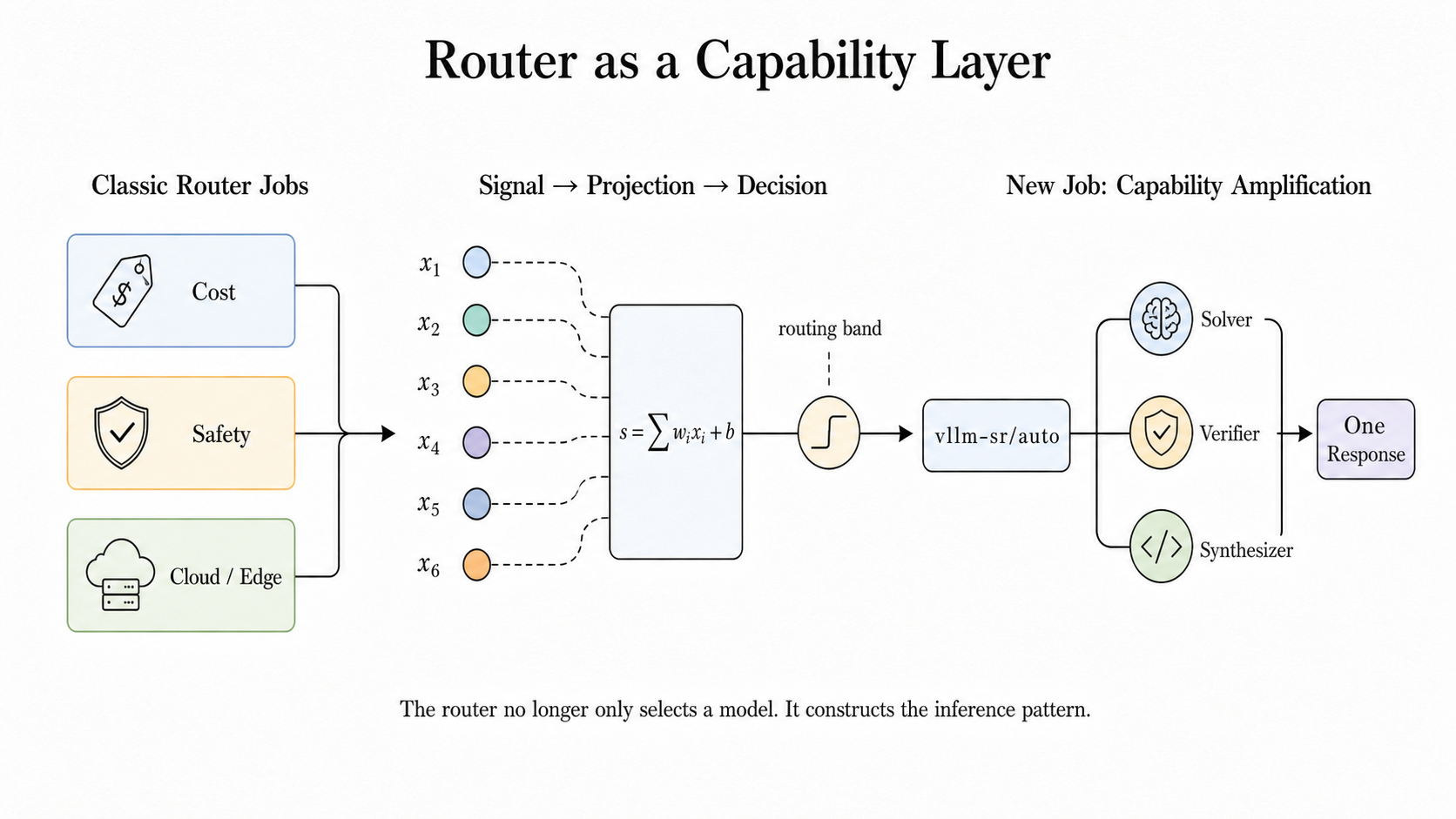
AI 모델 한 번 호출이 팀워크가 된다, vLLM 라우터가 그리는 서빙 계층의 변화
vLLM Semantic Router가 단일 모델 호출 뒤에서 여러 모델을 협업시키는 micro-agent 런타임을 공개했습니다. ‘모델’의 정의가 체크포인트에서 시스템 경계로 바뀌는 흐름을 짚습니다.
Written by
GLM-5.2가 바꾼 것, 이제 오픈 모델은 싸기만 한 게 아니다
Z.ai의 GLM-5.2가 코딩 하네스에서 제대로 작동하는 첫 오픈웨이트 모델로 평가받습니다. 프론티어 대비 6분의 1 비용, 6.8개월로 좁혀진 성능 격차가 실무자의 모델 선택에 갖는 의미를 짚습니다.
Written by

얀 르쿤이 말하는 오픈소스 AI, 대부분의 나라엔 유일한 선택지
메타를 떠난 얀 르쿤이 UN 연설에서 오픈소스 AI를 글로벌 AI 주권의 유일한 길로 주장했습니다. 연합형 훈련 프로젝트 태피스트리와 AI 위험론 반박까지, 그의 핵심 논리를 정리합니다.
Written by

DiffusionGemma, 256토큰 동시 생성으로 로컬 추론 4배 빠르게
Google이 공개한 DiffusionGemma는 256토큰을 동시에 생성하는 디퓨전 방식으로 로컬 GPU 환경에서 기존 LLM 대비 최대 4배 빠른 추론 속도를 제공합니다.
Written by

프론티어 LLM 비용, 11개월이면 역전된다, 로컬 AI의 경제학
프론티어 LLM API 가격이 계속 오르는 상황에서, 엔지니어+로컬AI 조합이 약 11개월 만에 비용 역전을 이루는 구조적 논리를 분석한 SignalBloom AI 에세이 큐레이션.
Written by

Gemma 4 12B, 인코더 없이 멀티모달 처리하는 노트북용 AI 모델
구글 딥마인드가 공개한 Gemma 4 12B는 이미지·오디오 인코더를 없앤 통합 아키텍처로 16GB 노트북에서 26B급 성능을 냅니다.
Written by

Nemotron 3 Ultra, 미국 오픈 모델 1위 등극했지만 중국엔 여전히 밀린다
엔비디아 Nemotron 3 Ultra, 미국 오픈 AI 모델 최고 성능 달성. 속도는 중국 모델보다 3~6배 빠르지만 지능 점수는 Kimi K2.6에 뒤처져.
Written by
