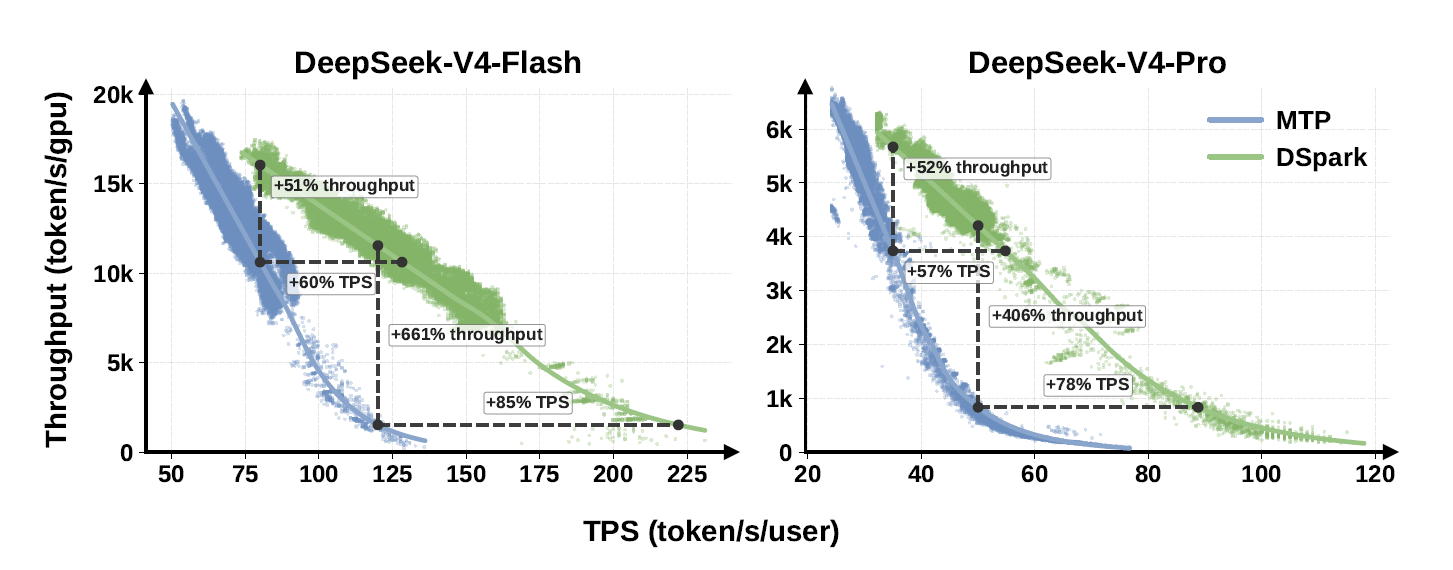
같은 모델을 같은 GPU에 올렸는데, 응답 속도만 최대 85% 빨라졌습니다. 모델을 다시 학습시키지도, 하드웨어를 바꾸지도 않았습니다.

DeepSeek가 지난주 추론 최적화 프레임워크 DSpark를 공개했습니다. 자사의 V4-Flash, V4-Pro 모델에 이미 적용돼 있고, 드래프트 모델을 직접 학습시킬 수 있는 전체 코드베이스 DeepSpec도 MIT 라이선스로 함께 풀었습니다. 핵심은 모델 구조나 파라미터를 건드리지 않고, 추론 방식만 바꿔서 이 정도 속도 차이를 냈다는 것입니다.
출처: DeepSpec – DeepSeek AI
토큰을 하나씩이 아니라 뭉치로 확인한다
일반적인 언어모델은 답을 한 글자(토큰)씩 순서대로 만듭니다. 파라미터가 1조 개를 넘는 모델일수록 GPU는 다음 토큰을 계산할 데이터를 불러오는 데만 시간을 쓰고, 정작 연산은 노는 시간이 길어지죠. 추측 디코딩은 이 문제를 풀기 위해 나온 방법입니다. 작고 가벼운 ‘드래프트’ 모델이 먼저 몇 토큰을 미리 찍어두면, 본 모델이 그 후보들을 한 번에 검증하는 방식이죠. 맞으면 그대로 채택하고, 틀리면 그 지점부터 다시 만듭니다.
문제는 드래프트 모델이 뒤쪽 토큰으로 갈수록 예측이 부정확해진다는 겁니다. DSpark는 여기에 마르코프 헤드라는 구조를 붙여 뒤쪽 토큰의 정확도가 떨어지는 현상을 줄였습니다. 동시에 GPU가 바쁠 때는 검증 깊이를 얕게, 여유 있을 때는 깊게 조절하는 신뢰도 기반 스케줄링을 넣어 낭비되는 연산도 줄였습니다. 이 두 가지가 맞물려 V4-Flash는 최대 85%, V4-Pro는 최대 78%까지 개인 응답 속도가 올라갔습니다.
DeepSeek 모델이 아니어도 통했다
더 눈에 띄는 부분은 따로 있습니다. DeepSeek는 이 방식을 자사 모델뿐 아니라 알리바바의 Qwen3, 구글 딥마인드의 Gemma 계열 오픈모델에도 적용해 테스트했습니다. 그 결과 기존 최고 성능으로 꼽히던 Eagle3 방식보다 한 번에 채택되는 토큰 길이가 30.9% 더 길었죠. 그리고 이 학습 코드 전체를 깃허브에 MIT 라이선스로 공개했습니다. DeepSeek가 만든 완성품만 받는 게 아니라, 원하는 모델에 맞춰 드래프트 모델을 직접 학습시킬 수 있는 도구까지 통째로 가져갈 수 있다는 뜻입니다.
다만 진입장벽이 낮은 건 아닙니다. 기본 학습 설정 기준으로 8개 GPU가 달린 서버 한 대와 약 38테라바이트의 저장공간이 필요하네요. 개인이 노트북에서 바로 돌려볼 수준은 아니고, 자체 추론 서버를 운영하는 팀 정도가 실질적으로 시도해볼 수 있는 규모입니다.
모델 경쟁과는 다른 축
지금까지 오픈소스 모델 경쟁은 대체로 “누가 더 똑똑한 모델을 내놓는가”였습니다. DSpark가 보여준 건 조금 다른 축이죠. 같은 모델이라도 서빙 방식을 어떻게 설계하느냐에 따라 체감 속도가 두 배 가까이 벌어질 수 있다는 것, 그리고 그 차이를 만드는 기술을 누구나 가져다 쓸 수 있게 공개했다는 것입니다. 오픈AI나 Anthropic 같은 곳들도 자체 서빙 스택에서 비슷한 가속 기법을 쓰지만, 학습 코드까지 통째로 공개한 경우는 드뭅니다. 결국 이런 공개가 쌓일수록, 모델 성능만큼이나 ‘얼마나 싸고 빠르게 서빙하는가’가 오픈소스 생태계를 가르는 지점이 될지도 모릅니다.
참고자료:
답글 남기기