모델 세대가 올라갈수록 같은 작업을 처리하는 데 더 많은 토큰을 씁니다. GitHub가 자사 데이터로 확인한 추세입니다. 성능은 좋아졌지만, 사용량 기반 과금에서는 그게 곧 비용이고 지연이며, 에이전트가 작업을 끝낼 때까지 남은 컨텍스트 여유이기도 합니다.

GitHub가 Copilot의 토큰 효율을 끌어올린 작업을 공식 블로그에 정리했습니다. 핵심은 두 갈래입니다. 하나는 매 턴 반복되는 비용을 하니스(harness, 모델에 요청을 준비해 보내는 실행 계층) 차원에서 줄이는 것이고, 다른 하나는 작업 성격에 맞는 모델을 자동으로 고르는 것입니다. 흥미로운 건 효율의 정의가 바뀌었다는 점입니다. 토큰을 적게 쓰는 게 아니라, 더 똑똑하게 쓰는 쪽으로요.
출처: Getting more from each token: How Copilot improves context handling and model routing – GitHub Blog
보이지 않는 반복 비용
에이전트가 한 번 일할 때, 모델에 보내는 요청의 상당 부분은 매 턴 똑같이 반복됩니다. 시스템 지시문, 도구 정의, 저장소 컨텍스트, 그리고 대화 기록입니다. 이 반복되는 앞부분을 프롬프트 프리픽스(prompt prefix)라고 부릅니다.
여기서 캐싱이 등장합니다. 요청들이 정확히 같은 프리픽스를 공유하면, 추론 제공자는 그 부분을 매번 다시 계산하지 않고 이미 처리해둔 모델 상태를 재사용할 수 있습니다. 마치 매번 같은 책의 1장부터 다시 읽는 대신, 읽어둔 요약을 꺼내 쓰는 것과 비슷합니다. 캐시된 토큰은 최대 10배까지 저렴해지고, 응답도 빨라집니다. GitHub는 Anthropic 모델 기준으로 이 캐시 적중률을 약 94%까지 끌어올렸습니다. 매 요청에서 새로 계산해야 하는 입력이 일부에 그친다는 뜻입니다.
도구는 필요할 때만 꺼낸다
두 번째 비용은 도구 정의입니다. 에이전트는 MCP 서버가 제공하는 도구, 터미널 명령, 파일 작업 등 많은 도구를 끌어다 씁니다. 문제는 각 도구가 이름·설명·전체 파라미터 명세를 담은 무거운 정의를 가지고 있고, 예전에는 이 전부를 매 요청마다 컨텍스트에 실어 보냈다는 점입니다. 실제로 쓰는 도구가 몇 개뿐이어도 비용은 고정으로 붙고, 도구 목록이 커질수록 부담도 커집니다.
도구 검색(tool search)은 이 짐을 덜어줍니다. 처음에는 모델에게 각 도구의 이름과 설명 같은 가벼운 정보만 보여주고, 무거운 파라미터 명세는 컨텍스트 밖에 둡니다. 모델이 특정 도구가 필요해 검색했을 때 비로소 그 정의를 불러옵니다. 이렇게 하면 모델은 쓰지도 않을 도구에 토큰을 낭비하지 않고, 그만큼 실제 작업에 쓸 여유가 늘어납니다. GitHub 측정으로는 중간값 사용자 기준 한 세션의 토큰 사용량이 약 18% 줄었습니다.
핵심 설계는 따로 있습니다. 이렇게 나중에 불러오는 도구들은 프롬프트 프리픽스가 아니라 컨텍스트의 끝에 붙습니다. 덕분에 캐시된 프리픽스가 다시 쓰여지지 않고, 앞서 만든 캐싱 이점이 턴이 이어져도 계속 작동합니다.
작업마다 맞는 모델을 고르는 Auto
효율의 다른 축은 모델 선택입니다. GitHub의 평가에서 모든 작업에 한결같이 최고인 단일 모델은 없었습니다. 많은 경우 더 효율적인 모델이 같은 결과를 냈고, 더 강력한 모델은 깊은 추론이 필요한 작업에서만 차이를 만들었습니다.
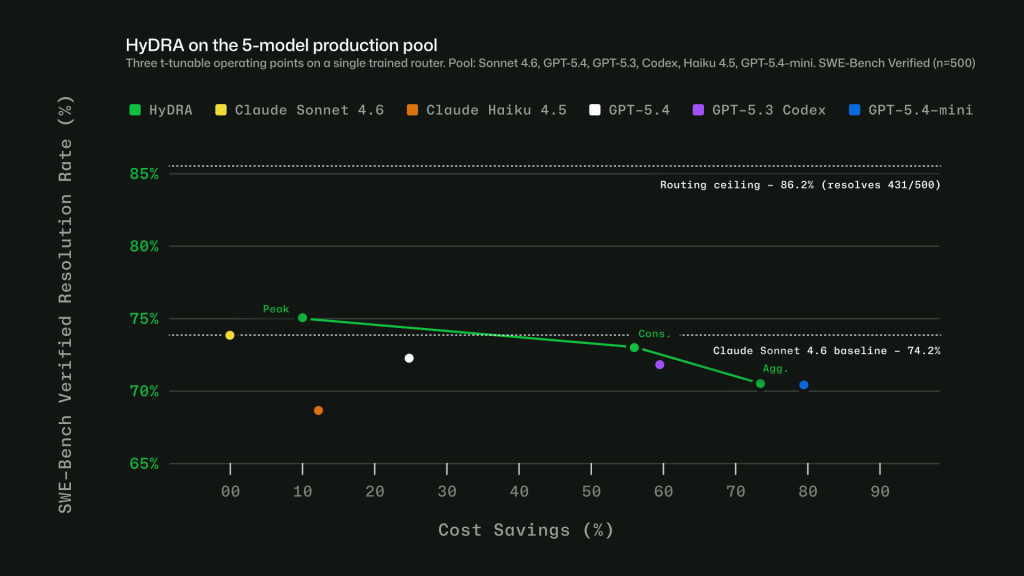
그래서 나온 것이 Auto입니다. 첫 프롬프트 이후 Copilot이 작업의 의도를 파악해 적합한 모델을 자동으로 고릅니다. 판단에는 두 신호가 들어갑니다. 하나는 실시간 모델 상태로, 가용성·이용률·속도·오류율·비용을 추적합니다. 다른 하나는 HyDRA라는 라우팅 모델로, 추론 깊이·코드 복잡도·디버깅 난이도·도구 조율 필요성 같은 요소를 보고 품질 기준을 넘기는 모델들을 추린 뒤 그중 가장 적합한 것을 고릅니다.
흥미로운 트레이드오프도 있습니다. 매 턴 모델을 바꾸면 유연해 보이지만, 모델을 바꾸는 순간 앞서 쌓아둔 프리픽스 캐시가 깨집니다. 그 손실이 라우팅으로 아끼는 것보다 클 수 있습니다. 그래서 Auto는 캐시의 자연스러운 경계에서만 모델을 바꿉니다. 잃을 캐시가 없는 첫 턴, 그리고 오래된 대화를 요약해 프리픽스가 초기화되는 압축(compaction) 직후입니다. 그 사이에는 같은 모델을 유지해 캐시가 계속 쌓이게 둡니다.
효율의 정의가 바뀌었다
이 작업이 흥미로운 건, 더 좋은 모델이나 더 큰 컨텍스트로 문제를 푼 게 아니라는 점입니다. 같은 모델을 두고 그 주변의 낭비를 깎아낸 것입니다. 반복되는 앞부분은 캐시로 재사용하고, 안 쓰는 도구는 컨텍스트에서 빼고, 작업에 맞는 모델로 보내는 식으로요.
사용량 기반 과금이 자리 잡으면서, 매 토큰이 곧 비용이 되는 시대가 됐습니다. 개발자 입장에서 이 변화가 주는 실마리는 분명합니다. 한 세션을 같은 작업에 집중하고, 도중에 모델이나 설정을 자주 바꾸지 않을수록 캐시가 살아 있다는 것입니다. 효율은 더 이상 토큰을 적게 쓰는 문제가 아니라, 같은 토큰으로 더 많은 일을 하게 만드는 문제로 옮겨가고 있습니다.
GitHub는 이 글과 별도로 OpenAI·Anthropic 모델별 캐시 적중률과 토큰 절감 수치를 담은 VS Code 기술 심층편도 공개했는데, 모델마다 캐싱이 어떻게 다르게 작동하는지 궁금하다면 참고할 만합니다.
참고자료: Improving token efficiency for GitHub Copilot in VS Code
답글 남기기