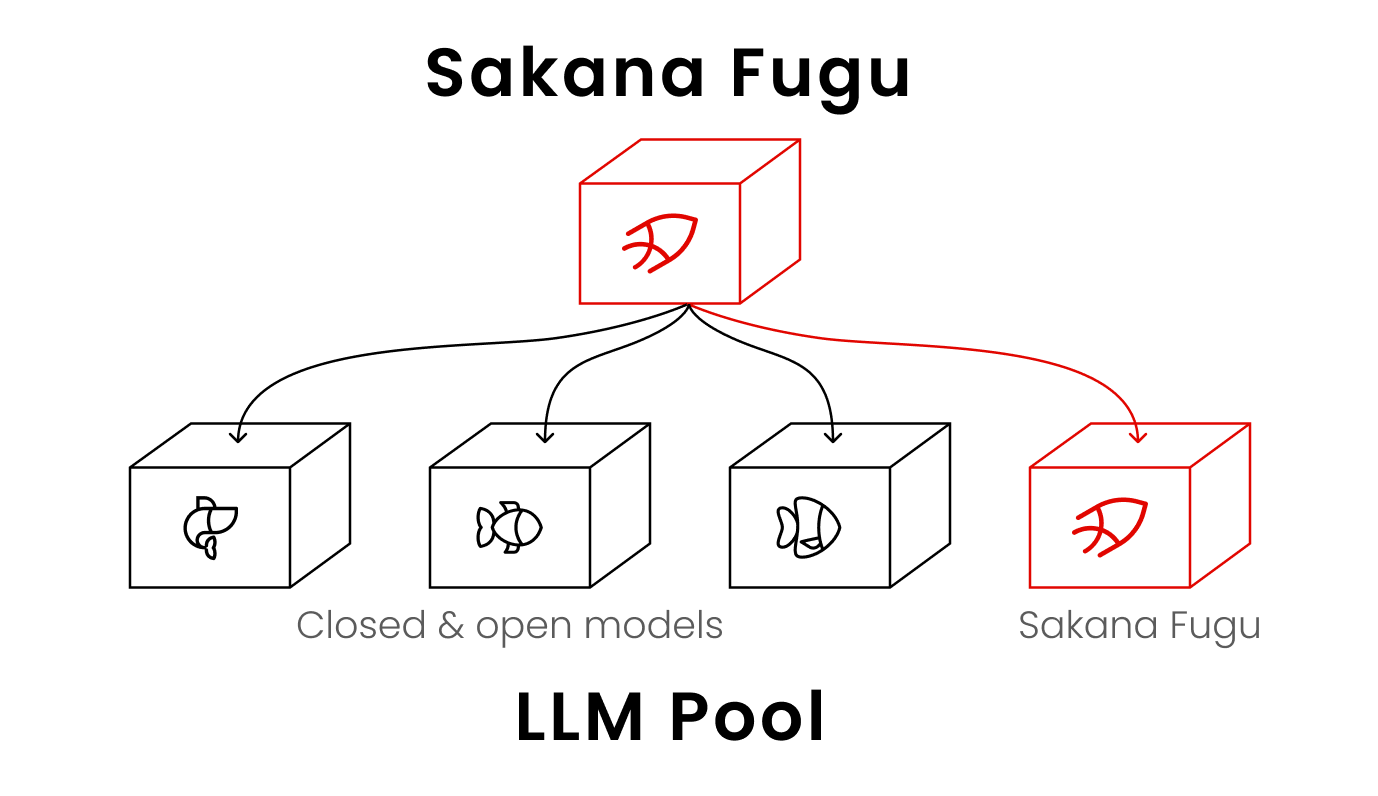
지금까지 AI 경쟁의 공식은 단순했습니다. 누가 더 크고, 더 많은 데이터로 학습한 모델을 만드느냐. Sakana AI는 다른 길을 택했습니다. 하나의 거대한 모델을 키우는 대신, 세상에 이미 나와 있는 모델들을 지휘하는 모델을 만들었습니다.

도쿄 기반 스타트업 Sakana AI가 6월 22일 ‘Fugu’와 ‘Fugu Ultra’를 정식 공개했습니다. Fugu 자체가 하나의 언어모델인데, 그 역할은 답을 직접 내는 게 아니라 여러 LLM을 골라 부리는 것입니다. 회사 측은 상위 모델인 Fugu Ultra가 일반에 공개되지 않은 Anthropic의 Fable 5, Mythos Preview와 까다로운 벤치마크에서 어깨를 나란히 한다고 밝혔습니다. 수출규제 같은 리스크 없이 말이죠.
출처: Sakana Fugu: One Model to Command Them All – Sakana AI
모델을 호출하는 모델이란 무엇인가
전통적인 멀티 에이전트 시스템은 사람이 직접 설계합니다. 어떤 모델이 기획을 맡고, 어떤 모델이 실행하고, 어떤 모델이 검증할지 규칙을 짜야 했죠. 복잡하고 손이 많이 갑니다.
Fugu는 이 조율 자체를 학습한 언어모델입니다. 사용자는 하나의 API 엔드포인트로 요청을 보내고, 나머지는 Fugu가 내부에서 판단합니다. 작동 흐름은 대략 이렇습니다.
- 요청을 받아 혼자 풀어도 되는지, 전문가 팀이 필요한지 판단합니다.
- 필요하면 에이전트 풀에서 적합한 모델들을 골라 작업을 위임합니다. 이때 자기 자신을 재귀적으로 호출하기도 합니다.
- 각 모델의 결과를 검증하고, 하나의 신뢰할 만한 답으로 통합합니다.
겉에서 보면 그냥 모델 하나를 부르는 것 같지만, 안에서는 전문가들의 협업이 돌아가는 셈입니다. 이 접근은 Sakana AI가 ICLR 2026에 발표한 두 논문, 모델에게 Thinker·Worker·Verifier 역할을 나눠 맡기는 TRINITY와 자연어로 협업 전략을 스스로 찾아내는 Conductor에 기반합니다.
Fable, Mythos와 어깨를 나란히 했다는 성적표
벤치마크를 보면 Fugu Ultra는 SWE Bench Pro(73.7), GPQA-D(95.5), MRCRv2(93.6) 같은 코딩·과학·추론 지표에서 Opus 4.8, Gemini 3.1 Pro, GPT 5.5 같은 기반 모델들을 대체로 앞섭니다. 눈에 띄는 건 풀에 들어 있지도 않은 Fable 5, Mythos Preview와 비등하다는 주장입니다. 이 두 Anthropic 모델은 공개돼 있지 않아 Fugu의 에이전트 풀에 포함될 수 없었습니다. 바꿔 말하면, 더 좋은 부품 없이도 조율만으로 최상위권에 닿았다는 이야기입니다.
벤치마크보다 인상적인 건 긴 작업에서의 모습입니다. 한 정성 평가에서 Fugu Ultra는 소형 GPT의 학습 레시피를 자율적으로 개선하는 실험을 맡아, H100 한 장으로 14시간 동안 123번의 실험을 돌리며 배치 크기와 학습률, 옵티마이저 설정을 스스로 바꿔 나갔습니다. 최종 성능은 비교한 세 프론티어 모델을 모두 앞섰습니다. 베타 테스터들도 논문 재현, 보안 점검, 코드 리뷰처럼 길고 지저분한 작업에서 가장 큰 차이를 느꼈다고 합니다. 한 엔지니어는 다른 도구가 버그 세 개를 짚을 때 Fugu는 스무 개 넘게 찾아냈다고 전했습니다.
왜 하필 지금 오케스트레이션인가
Sakana가 이 제품을 내놓은 맥락이 중요합니다. 회사는 단일 벤더 의존이 더 이상 가설이 아니라 현실의 리스크라고 말합니다. 근거로 든 것이 최근 Anthropic의 Fable·Mythos 모델에 부과된 수출규제입니다. 규제와 외교 정책이 바뀌면 최상위 AI에 대한 접근이 하룻밤 새 사라질 수 있다는 거죠.
Fugu의 에이전트 풀은 통째로 교체 가능합니다. 한 공급자가 막히면 다른 모델로 우회합니다. 개인 사용자 입장에서 이건 특정 회사의 API 한 곳에 작업 흐름 전체를 묶어두지 않아도 된다는 의미가 있습니다. 새 프론티어 모델이 나오면 풀에 더해져 그 이득이 자연스레 따라오는 구조이기도 합니다.
다만 이 회복탄력성에는 한계가 분명합니다. 풀에 든 모델들이 동시에 막히면 Fugu의 선택지도 같이 줄어듭니다. The Decoder는 오케스트레이션이 견고함을 높이긴 해도 진정한 주권과 같은 말은 아니라고 짚었습니다. 여러 모델을 동시에 부리는 만큼 토큰 사용량과 비용이 얼마나 늘어나는지도 발표에서 충분히 다뤄지지 않은 부분입니다.
거대 단일 모델 경쟁이 한계에 부딪힌 자리에서, Fugu는 “더 잘 지휘하는 모델”이라는 다른 축을 제시합니다. 정성 사례로 든 가나 고문서 읽기, 루빅스큐브 솔버, 블라인드 체스 같은 실험들은 원문에서 영상과 함께 더 자세히 볼 수 있습니다.
참고자료:
답글 남기기