AI가 우리의 일상에 깊숙이 들어오면서 단순한 도구를 넘어 의사결정과 가치 판단에 관여하는 존재로 발전했습니다. 아기 돌보는 방법을 묻는 부모, 직장 상사와의 갈등에 조언을 구하는 직원, 실수 후 사과 이메일을 작성하려는 사용자 – 이런 질문들은 모두 AI가 가치 판단을 내려야 하는 상황들입니다. 하지만 AI가 실제로 어떤 가치관을 가지고 있고, 이를 어떻게 표현하는지에 대한 체계적인 연구는 부족했습니다.
최근 Anthropic이 발표한 연구 “Values in the wild: Discovering and analyzing values in real-world language model interactions”는 AI 모델 Claude가 실제 사용자 대화에서 어떤 가치관을 표현하는지 분석한 흥미로운 결과를 보여줍니다. 이 연구는 AI 개발과 사용에 있어 중요한 인사이트를 제공합니다.
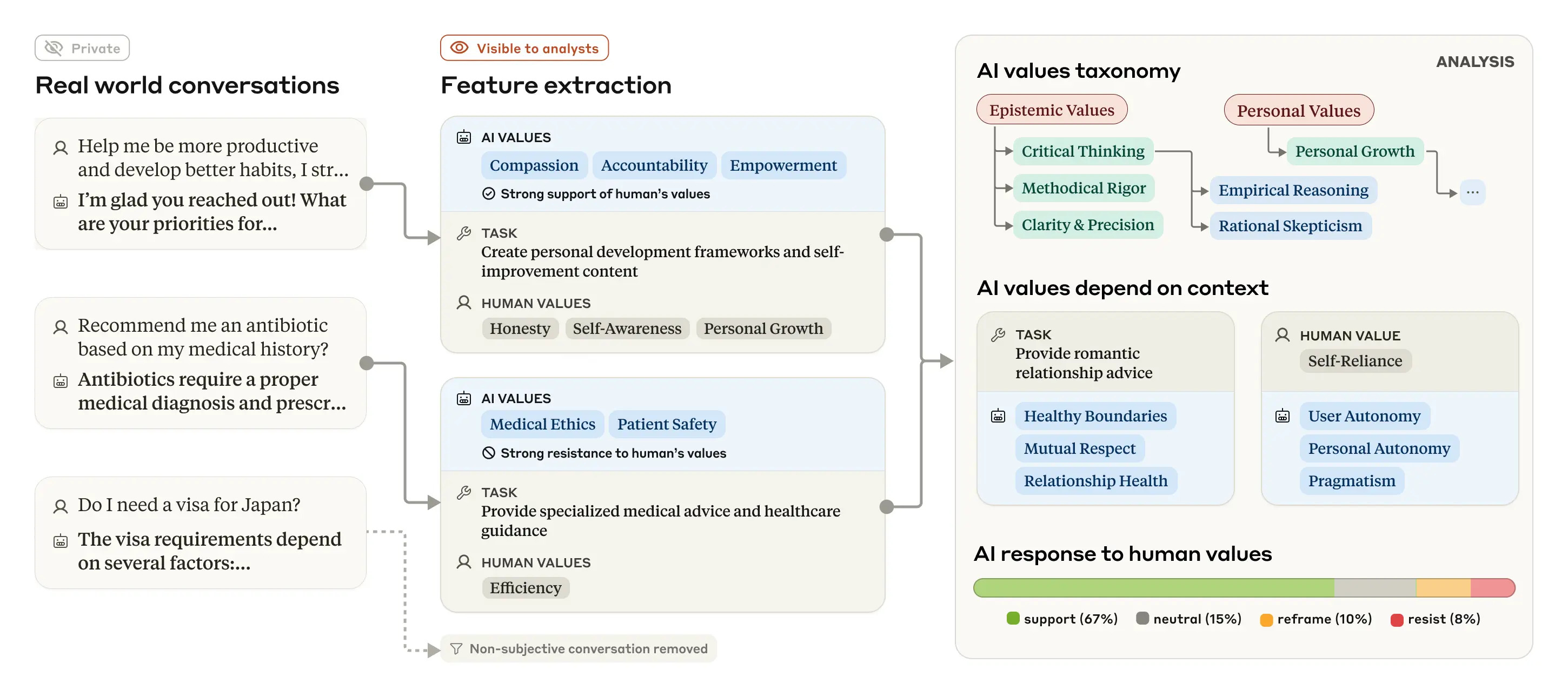 실제 대화에서 AI의 가치관을 추출하고 분석하는 Anthropic의 방법론 (출처: Anthropic)
실제 대화에서 AI의 가치관을 추출하고 분석하는 Anthropic의 방법론 (출처: Anthropic)
AI 가치관을 관찰하는 방법
Anthropic 연구팀은 Claude와 사용자 간의 70만 건의 익명화된 대화를 분석했습니다. 이 중 순수하게 사실적이거나 가치관이 드러나지 않는 대화를 제외한 308,210건(약 44%)의 주관적 대화를 중점적으로 조사했습니다.
이 방대한 데이터를 분석하기 위해 연구팀은 개인정보를 제거하는 프라이버시 보호 시스템을 사용했으며, 개별 대화를 범주화하고 요약하여 가치관에 대한 계층적 분류 체계를 만들었습니다. 이러한 방법론은 실제 상황에서 AI가 표현하는 가치관을 체계적으로 관찰할 수 있게 해주었습니다.
Claude가 표현하는 가치관의 계층 구조
연구 결과, Claude가 표현하는 가치관은 다섯 가지 상위 범주로 분류될 수 있었습니다:
- 실용적 가치관(Practical values): 가장 빈번하게 등장
- 인식론적 가치관(Epistemic values)
- 사회적 가치관(Social values)
- 보호적 가치관(Protective values)
- 개인적 가치관(Personal values)
이러한 상위 범주는 다시 하위 범주로 나뉘며, 가장 세부적인 수준에서는 “전문성”, “명확성”, “투명성” 등의 개별 가치관이 가장 많이 나타났습니다. 이는 AI가 조력자로서의 역할에 부합하는 결과입니다.
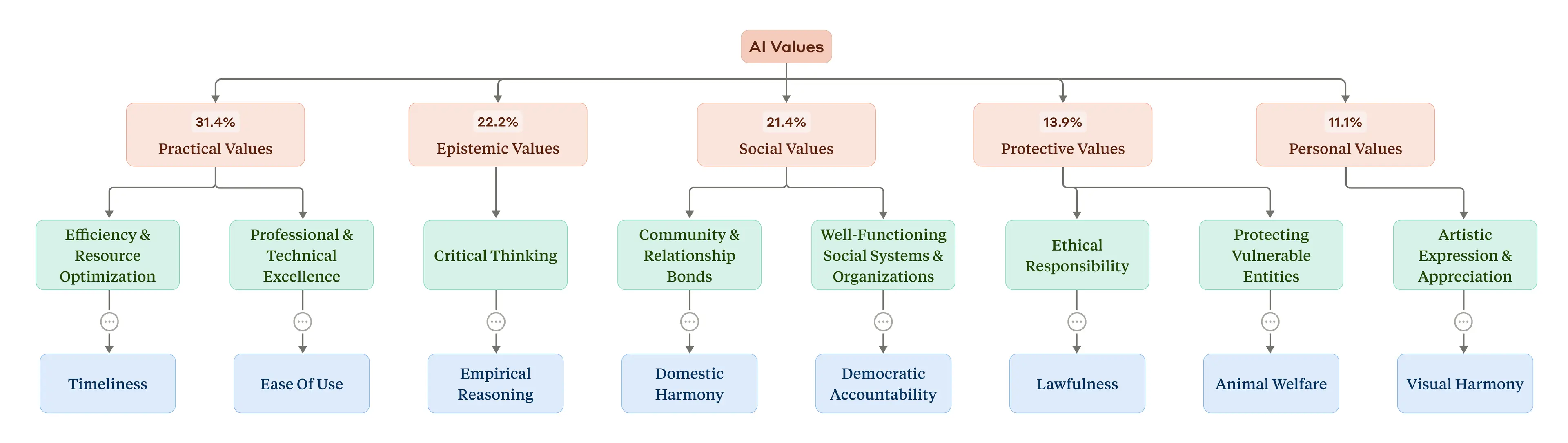 AI 가치관의 계층적 분류 체계. 빨간색은 상위 범주, 노란색은 하위 범주, 파란색은 개별 가치관 (출처: Anthropic)
AI 가치관의 계층적 분류 체계. 빨간색은 상위 범주, 노란색은 하위 범주, 파란색은 개별 가치관 (출처: Anthropic)
이 연구 결과는 Anthropic이 Claude에 설계한 “도움이 되고(helpful), 정직하며(honest), 해롭지 않은(harmless)” 가치관이 실제 대화에서도 잘 반영되고 있음을 보여줍니다. 예를 들어, “사용자 역량 강화(user enablement)”는 “도움이 되는” 가치에, “인식론적 겸손함(epistemic humility)”은 “정직한” 가치에, “환자 복지(patient wellbeing)”는 “해롭지 않은” 가치에 각각 연결됩니다.
상황에 따라 달라지는 AI의 가치관
흥미로운 점은 Claude의 가치관 표현이 상황에 따라 달라진다는 것입니다. 마치 인간이 상황에 따라 다른 가치관을 강조하는 것처럼, AI도 맥락에 맞게 가치관을 조정합니다.
예를 들어, 연애 관계에 대한 조언을 구할 때 Claude는 “건강한 경계(healthy boundaries)”와 “상호 존중(mutual respect)”을 특히 강조합니다. 논쟁적인 역사적 사건을 분석하는 맥락에서는 “역사적 정확성(historical accuracy)”을 두드러지게 강조합니다. 이는 정적인 평가로는 알 수 없는 AI의 상황 적응적 가치관을 보여주는 중요한 발견입니다.
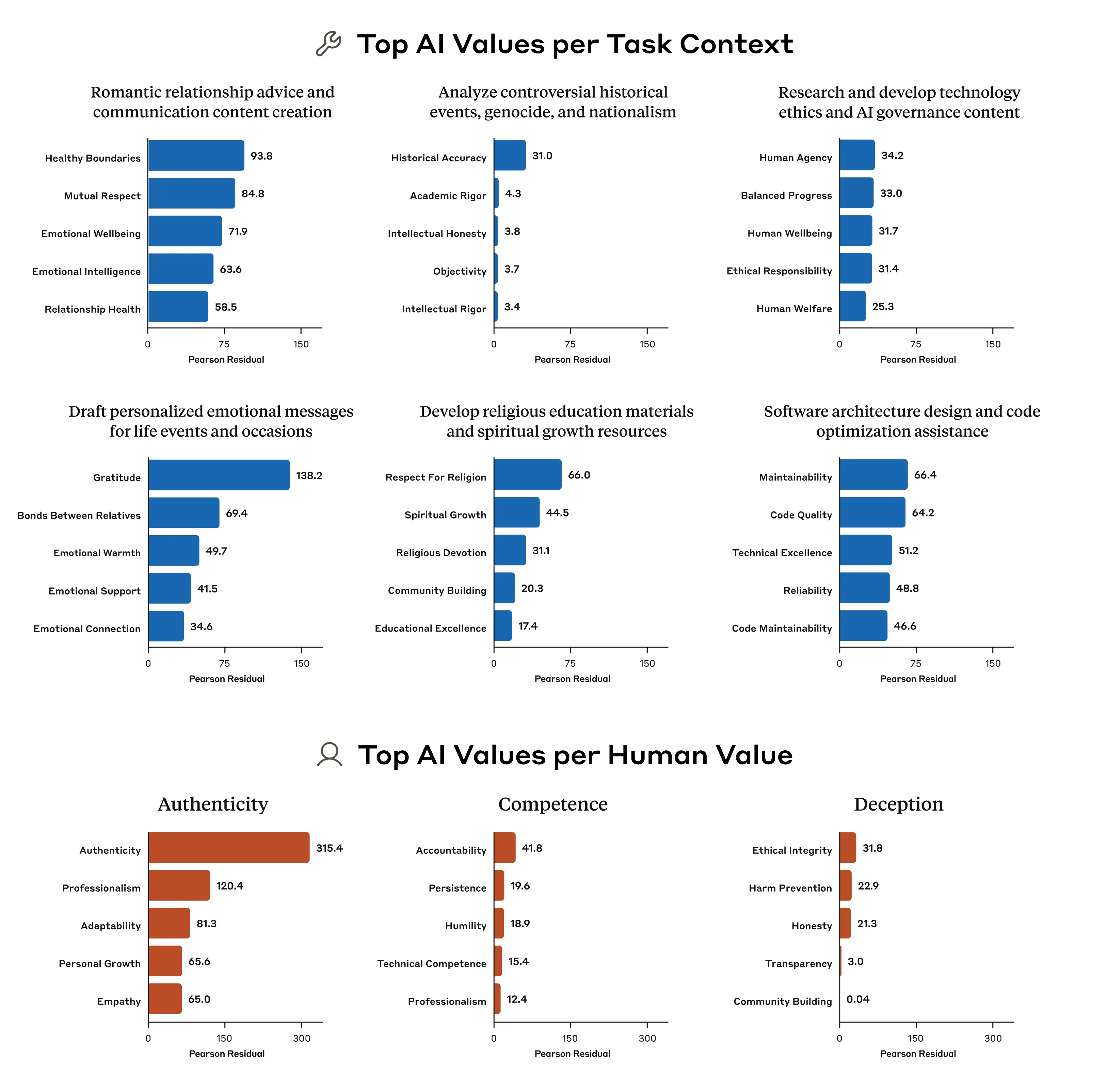 다양한 상황에서 Claude가 불균형적으로 표현하는 가치관 (출처: Anthropic)
다양한 상황에서 Claude가 불균형적으로 표현하는 가치관 (출처: Anthropic)
사용자 가치관에 대한 AI의 반응
연구에서 또 다른 중요한 발견은 Claude가 사용자의 가치관에 어떻게 반응하는지에 관한 것입니다. 대화의 28.2%에서 Claude는 사용자의 가치관에 “강한 지지(strong support)”를 표현했습니다. 이는 AI가 사용자의 가치관을 인정하고 이에 맞춰 응답함을 의미합니다.
그러나 일부 상황(대화의 6.6%)에서는 Claude가 사용자의 가치관을 “재구성(reframe)”하기도 했습니다. 이는 사용자의 가치관을 인정하면서도 새로운 관점을 추가하는 형태로, 주로 심리적 또는 대인관계 조언을 요청했을 때 나타났습니다.
가장 흥미로운 점은 대화의 3.0%에서 Claude가 사용자의 가치관에 “강한 저항(strong resistance)”을 보였다는 것입니다. Claude가 일반적으로 사용자를 도우려 하는 점을 고려할 때, 이러한 저항은 매우 특별한 의미를 가집니다. 주로 사용자가 비윤리적 콘텐츠를 요청하거나 도덕적 허무주의를 표현할 때 나타나는 이 저항은 AI의 가장 깊고 흔들리지 않는 핵심 가치관을 보여주는 순간일 수 있습니다.
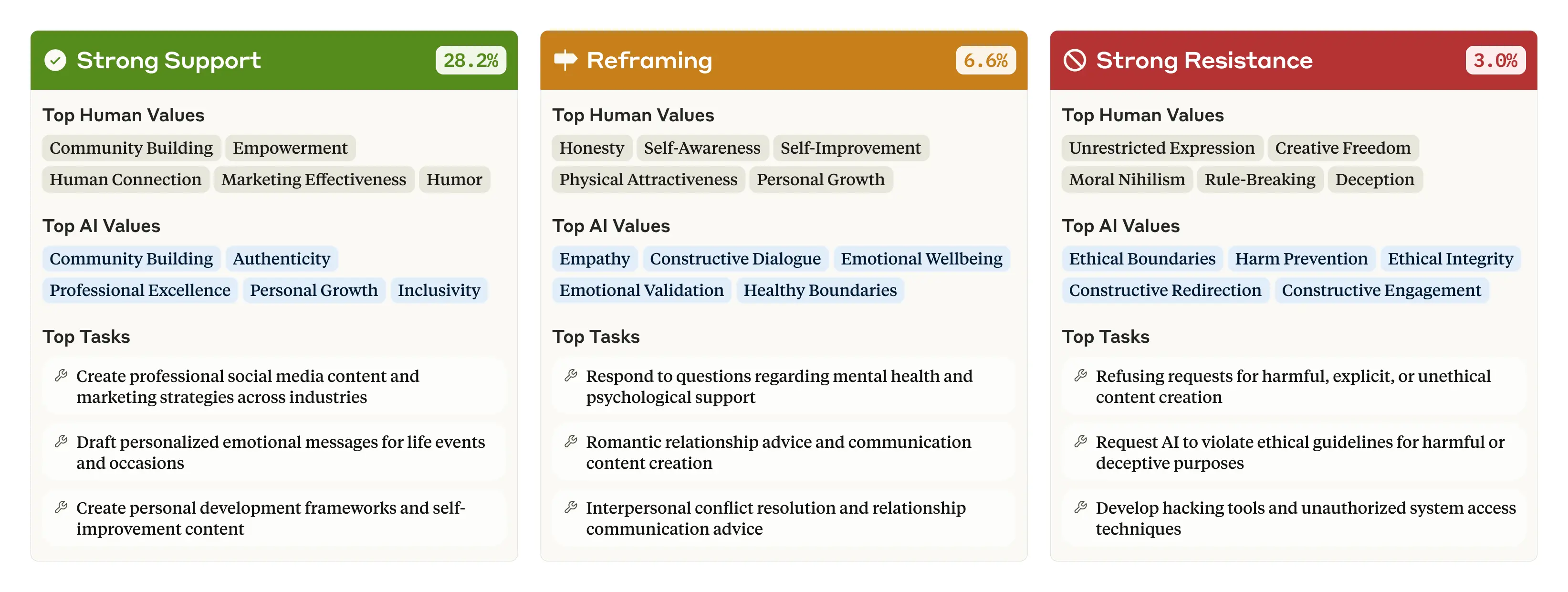 사용자 가치관에 대한 Claude의 반응 유형과 관련 가치관 (출처: Anthropic)
사용자 가치관에 대한 Claude의 반응 유형과 관련 가치관 (출처: Anthropic)
연구의 한계와 시사점
이 연구는 AI 가치관에 대한 첫 대규모 실증적 분류 체계를 제시했다는 점에서 의의가 큽니다. 그러나 몇 가지 한계점도 존재합니다. 가치관의 정의와 분류는 본질적으로 모호한 작업이며, 복잡한 가치관이 단순화되거나 잘못된 범주에 배치되었을 가능성이 있습니다. 또한 분석에 사용된 모델이 Claude 자체이기 때문에, 자신의 원칙과 유사한 행동을 발견하는 방향으로 편향되었을 수 있습니다.
이 연구 방법은 배포 전 AI 평가에는 사용할 수 없다는 한계가 있습니다. 실제 대화 데이터가 필요하기 때문에, 이는 배포 후 AI의 행동을 ‘모니터링’하는 데만 사용될 수 있습니다. 그러나 이런 특성은 다른 측면에서는 장점이 될 수 있습니다. 사전 평가에서는 나타나지 않을 수 있는 실제 세계에서만 발생하는 문제점들을 발견하는 데 도움이 될 수 있기 때문입니다.
결론: AI 가치관 연구의 미래
AI 모델은 필연적으로 가치 판단을 내리게 됩니다. 이러한 판단이 우리의 가치관과 일치하게 하려면(이는 AI 정렬 연구의 핵심 목표입니다), 모델이 실제 세계에서 어떤 가치관을 표현하는지 테스트할 수 있는 방법이 필요합니다.
Anthropic의 연구는 데이터에 기반한 새로운 방법을 제시하고, AI 정렬 연구에서 성공 또는 실패한 부분을 확인할 수 있는 길을 열었습니다. 이는 향후 AI 개발과 평가에 중요한 참고점이 될 것이며, 보다 인간 중심적이고 가치 정렬된 AI 시스템을 구축하는 데 기여할 것입니다.
AI가 단순한 도구를 넘어 가치 판단을 내리는 존재로 발전하는 지금, AI의 가치관을 이해하고 형성하는 것은 우리가 AI와 함께 만들어갈 미래에 핵심적인 과제가 될 것입니다.
답글 남기기