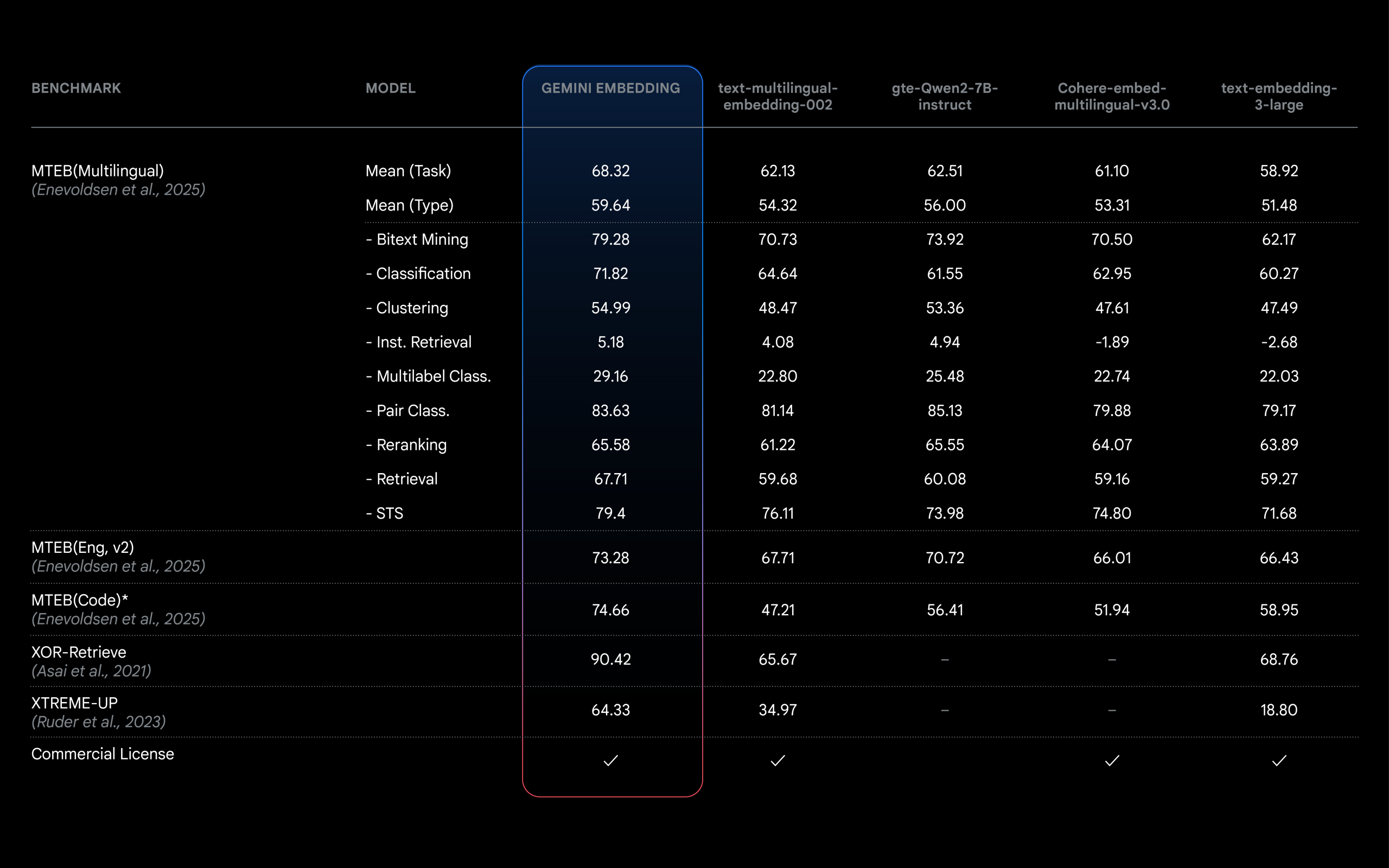
구글 크롬의, 최신 업데이트에 포함된 임베딩 모델은 크기가 이전 모델 대비 57% 작아졌는데도 성능은 거의 똑같이 유지했습니다. 이는 AI 모델 최적화의 놀라운 사례로, 특히 엣지 컴퓨팅과 리소스가 제한된 환경에서 AI 기술 활용을 크게 개선할 수 있는 중요한 발전입니다.
임베딩 모델이란?
임베딩 모델은 텍스트나 이미지와 같은 데이터를 숫자 벡터로 변환하는 AI 모델입니다. 크롬 브라우저에서는 이러한 임베딩 모델이 검색 기능 개선, 관련 콘텐츠 추천, 브라우징 기록 클러스터링 등 다양한 기능에 활용됩니다.
 임베딩 모델 성능 비교 (출처: Google Developers Blog)
임베딩 모델 성능 비교 (출처: Google Developers Blog)
새 모델의 핵심 개선사항
최근 크롬 브라우저 바이너리 분석을 통해 발견된 새로운 임베딩 모델은 다음과 같은 주요 특징을 가지고 있습니다:
- 크기 감소: 81.91MB에서 35.14MB로 약 57% 축소
- 성능 유지: 시맨틱 검색 작업에서 기존 모델과 거의 동일한 정확도 유지
- 처리 속도: 1-2% 정도의 추론 시간 개선
이러한 개선은 어떻게 이루어졌을까요?
양자화: 모델 최적화의 핵심 기술
개선의 핵심은 바로 ‘양자화(Quantization)’ 기술에 있습니다. 특히 새 모델에서는 임베딩 행렬을 float32에서 int8 정밀도로 변환하는 양자화 기법이 적용되었습니다.
양자화란 무엇인가?
양자화는 딥러닝 모델에서 사용되는 32비트 또는 16비트 부동소수점(float) 값을 더 적은 비트 수의 정수(integer)로 근사화하는 기술입니다. 대표적으로 8비트 정수(int8)를 사용하면 다음과 같은 공식으로 부동소수점 값을 표현합니다:
실제값 = (int8값 - 영점) × 스케일

양자화 전후 비교 이미지 (출처: Medium.com)
크롬 임베딩 모델의 기술적 분석
새로운 임베딩 모델 분석 결과, 두 모델(기존/신규)는 동일한 아키텍처와 유사한 텐서 수(611개 vs 606개)를 가지고 있으며, 동일한 입출력 형식([1,64] 입력 및 [1,768] 출력)을 유지하고 있습니다.
가장 큰 차이점은 임베딩 행렬에 있습니다:
- 기존 모델:
arith.constant30: [32128, 512], <class 'numpy.float32'>, 62.75 MB - 새 모델:
tfl.pseudo_qconst57: [32128, 512], <class 'numpy.int8'>, 15.69 MB
이 단일 텐서만으로 약 47MB의 크기 감소가 이루어졌으며, 이는 전체 크기 감소(46.77MB)의 대부분을 차지합니다.
사용자에게 미치는 영향
이러한 모델 최적화가 실제 크롬 사용자에게 어떤 혜택을 제공할까요?
- 저장 공간 절약: 46.77MB의 크기 감소는 특히 저용량 스마트폰이나 태블릿과 같은 제한된 용량을 가진 기기에서 귀중한 저장 공간을 확보해 줍니다.
- 브라우저 업데이트 용량 감소: ML 모델이 작아지면 크롬 업데이트의 크기도 작아져 다운로드 시간과 데이터 사용량이 줄어듭니다.
- 리소스 효율성 향상: 약간 더 빨라진 추론 시간(1-2%)은 이력 검색 및 콘텐츠 클러스터링과 같이 임베딩 모델에 의존하는 기능을 사용할 때 브라우저 성능이 더 향상됩니다.
- 일관된 품질: 검색 품질이나 콘텐츠 이해 기능의 저하 없이도 이러한 저장 및 성능 이점을 얻을 수 있습니다.
- 배터리 수명 향상 가능성: 작은 모델의 연산 요구량 감소는 모바일 기기의 배터리 수명을 조금이나마 개선하는 데 기여할 수 있습니다.
양자화의 기술적 세부사항
양자화에는 여러 접근 방식이 있으며, 크롬에 적용된 방식은 ‘훈련 후 양자화(Post-training quantization)’로 보입니다. 구글의 TensorFlow Lite 등에서 제공하는 양자화 방식은 다음과 같습니다:
- 동적 범위 양자화: 가중치만 정적으로 양자화하고 활성화는 실행 시간에 동적으로 양자화하는 방법
- 전체 정수 양자화: 모든 연산이 정수로 수행되어 더 큰 속도 향상을 제공하는 방법
- Float16 양자화: 32비트 대신 16비트 부동소수점을 사용하여 크기를 줄이는 방법
크롬의 새 임베딩 모델에서는 전체 정수 양자화에 가까운 방식이 사용된 것으로 보이며, 특히 가장 크기가 큰 임베딩 행렬에 int8 양자화가 적용되었습니다.
엣지 AI의 미래를 위한 의미
이 최적화는 엣지 기기를 위한 모델 압축의 중요한 성과를 보여줍니다. 아키텍처와 출력 정밀도를 보존하면서도 가장 큰 텐서만 선택적으로 양자화함으로써, 크롬 엔지니어들은 성능을 저하시키지 않으면서도 상당한 크기 감소를 달성했습니다.

엣지 디바이스에서의 AI 모델 최적화 (출처: darwinedge.com)
이 접근 방식은 무차별적인 양자화 전략보다 특정 모델 구성 요소를 선택적으로 양자화하는 것이 더 효과적일 수 있음을 보여줍니다. 이 기술은 스토리지 효율성이 중요하지만 성능을 희생할 수 없는 브라우저 및 기타 엣지 애플리케이션에 특히 유용합니다.
출력 레이어에서 약간 더 높은 유효 정밀도는 양자화 프로세스에 정밀도 손실을 보상하기 위한 미세 조정이 포함되었을 수 있음을 시사하여, 임베딩 품질을 유지하거나 심지어 약간 개선하는 모델로 이어졌습니다.
결론
크롬의 새로운 임베딩 모델은 AI 모델 최적화의 중요한 사례입니다. 이 발전은 모델을 57% 작게 만들면서도 성능은 그대로 유지하는 효과적인 양자화 기법을 보여줍니다. 이러한 최적화는 특히 모바일 기기와 웹 브라우저와 같은 엣지 환경에서 AI 애플리케이션을 더 효율적으로 구현할 수 있게 해주며, 향후 더 많은 AI 기능이 우리의 일상적인 컴퓨팅 경험에 통합될 수 있는 길을 열어줍니다.
앞으로 구글과 다른 기업들이 엣지 디바이스에서 AI 모델의 효율성을 더욱 개선하는 새로운 방법을 계속 발견함에 따라, 모델 최적화는 AI 발전의 핵심 영역으로 남을 것입니다.
답글 남기기