 이미지 출처: Maarten Grootendorst의 “A Visual Guide to Quantization”
이미지 출처: Maarten Grootendorst의 “A Visual Guide to Quantization”
언어 모델이 발전할수록 그 크기도 함께 커지고 있습니다. GPT-4, Claude, Llama 3와 같은 최신 언어 모델들은 수십억 개의 매개변수(파라미터)를 가지고 있어 일반 소비자용 하드웨어에서는 실행하기 어렵습니다. 이런 상황에서 AI 모델 양자화(Quantization)는 고성능 언어 모델을 더 작고 빠르게 만들어주는 혁신적인 기술로 주목받고 있습니다. 이 글에서는 AI 모델 양자화의 개념부터 다양한 방법, 그리고 최신 트렌드까지 알아보겠습니다.
1. 양자화란 무엇인가?
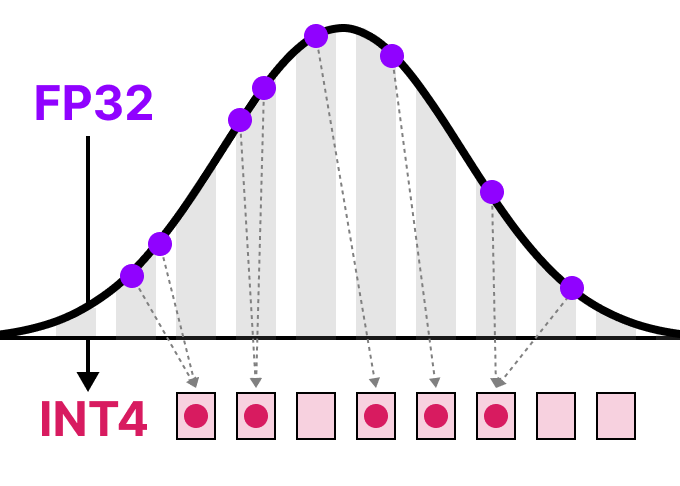
양자화는 간단히 말해 ‘더 적은 비트로 숫자를 표현하는 방법’입니다. AI 모델에서는 매개변수(weights)와 활성화 값(activations)을 표현하는 데 사용되는 비트 수를 줄여 모델의 크기를 줄이고 연산 속도를 높이는 기술입니다.
예를 들어, 대부분의 언어 모델은 32비트 부동소수점(FP32) 형식으로 학습됩니다. 이 정밀도에서 700억 개의 매개변수를 가진 모델은 약 280GB의 메모리가 필요합니다. 이것은 대부분의 소비자용 GPU가 감당할 수 없는 크기입니다. 하지만 양자화를 통해 각 매개변수를 8비트, 4비트, 심지어 1비트로 줄이면 모델 크기를 크게 줄일 수 있습니다.
 이미지 출처: Maarten Grootendorst의 “A Visual Guide to Quantization”
이미지 출처: Maarten Grootendorst의 “A Visual Guide to Quantization”
2. 양자화의 기본 원리: 비트 표현과 정밀도
컴퓨터는 모든 정보를 비트(0과 1)로 저장합니다. 부동소수점 수는 IEEE-754 표준에 따라 세 부분으로 표현됩니다: 부호(sign), 지수(exponent), 가수(fraction 또는 mantissa). 더 많은 비트를 사용할수록 더 정확한 값을 표현할 수 있지만, 그만큼 더 많은 메모리와 계산 자원이 필요합니다.
 이미지 출처: Maarten Grootendorst의 “A Visual Guide to Quantization”
이미지 출처: Maarten Grootendorst의 “A Visual Guide to Quantization”
- 32비트 부동소수점(FP32): 표준 정밀도, 학습에 일반적으로 사용
- 16비트 부동소수점(FP16): 절반 정밀도, 더 적은 메모리 사용
- 8비트 정수(INT8): 양자화된 표현, 메모리 요구사항 1/4로 감소
- 4비트 정수(INT4): 더 작은 표현, 더 많은 정밀도 손실 가능성
- 1비트 또는 2비트 표현: 극단적 압축, 새로운 접근 방식 필요
양자화의 핵심은 정밀도를 일부 희생하면서 모델 크기와 연산 속도를 개선하는 것입니다. 중요한 점은 정밀도가 낮아져도 모델의 성능 저하가 최소화되도록 하는 것입니다.
3. 다양한 양자화 방법
대칭 양자화(Symmetric Quantization)
대칭 양자화는 원래 부동소수점 값의 범위를 양자화된 공간에서 0을 중심으로 하는 대칭적인 범위로 매핑합니다. 최대 절대값(absmax)을 기준으로 스케일 팩터를 계산하고, 이를 사용해 값을 양자화합니다.
 이미지 출처: Maarten Grootendorst의 “A Visual Guide to Quantization”
이미지 출처: Maarten Grootendorst의 “A Visual Guide to Quantization”
비대칭 양자화(Asymmetric Quantization)
비대칭 양자화는 최소값과 최대값을 양자화된 범위의 최소값과 최대값에 매핑합니다. 영점 이동(zero-point)이 필요하며, 대칭 양자화보다 계산이 복잡하지만 값의 분포가 비대칭적일 때 더 효과적입니다.
 이미지 출처: Maarten Grootendorst의 “A Visual Guide to Quantization”
이미지 출처: Maarten Grootendorst의 “A Visual Guide to Quantization”
학습 후 양자화(Post-Training Quantization, PTQ)
학습 후 양자화는 모델을 먼저 전체 정밀도로 학습한 다음, 학습된 가중치를 낮은 정밀도로 변환하는 방법입니다. 이 방법은 구현이 간단하고 기존 모델을 쉽게 최적화할 수 있다는 장점이 있습니다.
- 동적 양자화(Dynamic Quantization): 추론 중에 활성화 값의 범위를 동적으로 계산
- 정적 양자화(Static Quantization): 보정 데이터셋을 사용해 활성화 값의 범위를 미리 계산
 이미지 출처: velog.io/@sohtks – 양자화 방법의 다양한 유형
이미지 출처: velog.io/@sohtks – 양자화 방법의 다양한 유형
양자화 인식 학습(Quantization-Aware Training, QAT)
양자화 인식 학습은 학습 과정에서 양자화의 영향을 모방하는 방법입니다. 학습 중에 ‘가짜’ 양자화 연산을 도입하여 모델이 양자화에 더 강건해지도록 합니다. 일반적으로 PTQ보다 더 나은 정확도를 제공하지만, 전체 모델을 다시 학습해야 하는 단점이 있습니다.
4. 최신 양자화 기술 동향
GPTQ (Generative Pre-trained Transformer Quantization)
GPTQ는 4비트 양자화에 널리 사용되는 방법으로, 레이어별로 양자화를 수행합니다. 각 레이어의 가중치를 역 헤시안(inverse-Hessian)으로 변환하여 각 가중치의 중요도를 평가하고, 중요도에 따라 양자화 오류를 재분배합니다.
 이미지 출처: KDnuggets
이미지 출처: KDnuggets
GGUF (GGML Unified Format)
GGUF는 모델의 일부 레이어를 CPU로 오프로드할 수 있게 해주는 양자화 방법입니다. 이는 GPU에 충분한 VRAM이 없을 때 CPU와 GPU를 함께 사용할 수 있게 해줍니다. 블록 단위로 양자화를 수행하며, 슈퍼 블록과 서브 블록의 조합을 사용합니다.
BitNet과 극한의 양자화
BitNet은 모델의 가중치를 단일 1비트(-1 또는 1)로 표현하는 극단적인 양자화 방법입니다. 트랜스포머 아키텍처에 양자화 과정을 직접 통합하여 구현합니다. BitNet 1.58은 여기에 0을 추가하여 삼진법(ternary) 표현을 사용하며, 이는 행렬 곱셈을 크게 최적화합니다.
5. 양자화의 실제 적용 사례와 효과
오픈소스 모델인 Qwen 2.5 32B Instruct의 다양한 양자화 버전을 비교한 aider.chat의 연구에 따르면, 양자화 수준에 따라 코드 편집 성능에 상당한 차이가 있었습니다.
 이미지 출처: 우아한형제들 기술블로그
이미지 출처: 우아한형제들 기술블로그
- FP16(16비트) 버전: 71.4%의 정확도
- 8비트 양자화 버전: 72.2%의 정확도 (놀랍게도 약간 더 높음)
- 4비트 양자화 버전: 72.2%의 정확도
- 2비트 양자화 버전: 61.7%의 정확도 (눈에 띄는 성능 저하)
이 결과는 4비트까지는 성능 저하 없이 모델 크기를 줄일 수 있음을 보여줍니다. 하지만 2비트로 내려가면 성능이 크게 떨어집니다.
6. 양자화의 이점과 한계점
양자화의 주요 이점
- 메모리 사용량 감소: 모델 크기를 최대 8배까지 줄일 수 있습니다.
- 추론 속도 향상: 낮은 정밀도 연산이 더 빠르게 실행됩니다.
- 전력 소비 감소: 적은 데이터 이동과 더 간단한 연산으로 전력 효율성이 향상됩니다.
- 더 넓은 기기 호환성: 모바일 기기, 임베디드 시스템 등에서 AI 모델 실행 가능
 이미지 출처: velog.io/@sohtks
이미지 출처: velog.io/@sohtks
양자화의 한계점
- 정확도 손실: 비트 수를 줄일수록 정보 손실이 발생할 수 있습니다.
- 이상치(outlier) 처리: 극단적인 값들이 양자화 과정에서 문제를 일으킬 수 있습니다.
- 모델 특성 의존성: 모든 모델이 같은 수준의 양자화에 적합하지 않습니다.
- 하드웨어 최적화 필요: 양자화의 이점을 최대한 활용하려면 하드웨어 지원이 필요합니다.
 이미지 출처: velog.io/@sohtks – 양자화 과정에서 발생하는 정보 손실
이미지 출처: velog.io/@sohtks – 양자화 과정에서 발생하는 정보 손실
7. 미래 전망
양자화 기술은 계속 발전하고 있으며, 다음과 같은 방향으로 진화할 것으로 예상됩니다:
- 더 효율적인 양자화 알고리즘: 정확도 손실을 최소화하면서 더 작은 비트 수 사용
- 하드웨어별 최적화: 특정 하드웨어에 맞춤화된 양자화 기법 개발
- 하이브리드 접근 방식: 중요한 부분은 높은 정밀도로, 덜 중요한 부분은 낮은 정밀도로 처리
- 자동화된 양자화: 모델 구조와 태스크에 따라 최적의 양자화 전략을 자동으로 결정
결론
AI 모델 양자화는 거대 언어 모델을 더 작고, 빠르고, 효율적으로 만드는 핵심 기술입니다. 소비자 하드웨어에서도 고성능 AI 모델을 실행할 수 있게 해주는 이 기술은 AI의 민주화와 보급에 큰 역할을 할 것입니다.
양자화를 통해 AI 모델은 더 이상 대형 데이터 센터에만 국한되지 않고, 개인의 컴퓨터, 모바일 기기, 심지어 IoT 디바이스에서도 실행될 수 있게 되었습니다. 앞으로 양자화 기술이 더욱 발전하면서, AI의 접근성과 활용성은 더욱 높아질 것입니다.
AI 개발자와 연구자들은 양자화의 다양한 방법을 이해하고 적절히 활용함으로써, 한정된 자원 내에서도 최고의 성능을 발휘하는 AI 모델을 개발할 수 있을 것입니다.
답글 남기기