
중국 AI 기업 DeepSeek이 9월 29일 공개한 V3.2-Exp 모델이 API 가격을 50% 이상 인하하면서도 성능은 그대로 유지하는 데 성공했습니다. 핵심은 ‘희소 어텐션(Sparse Attention)’ 기술입니다.
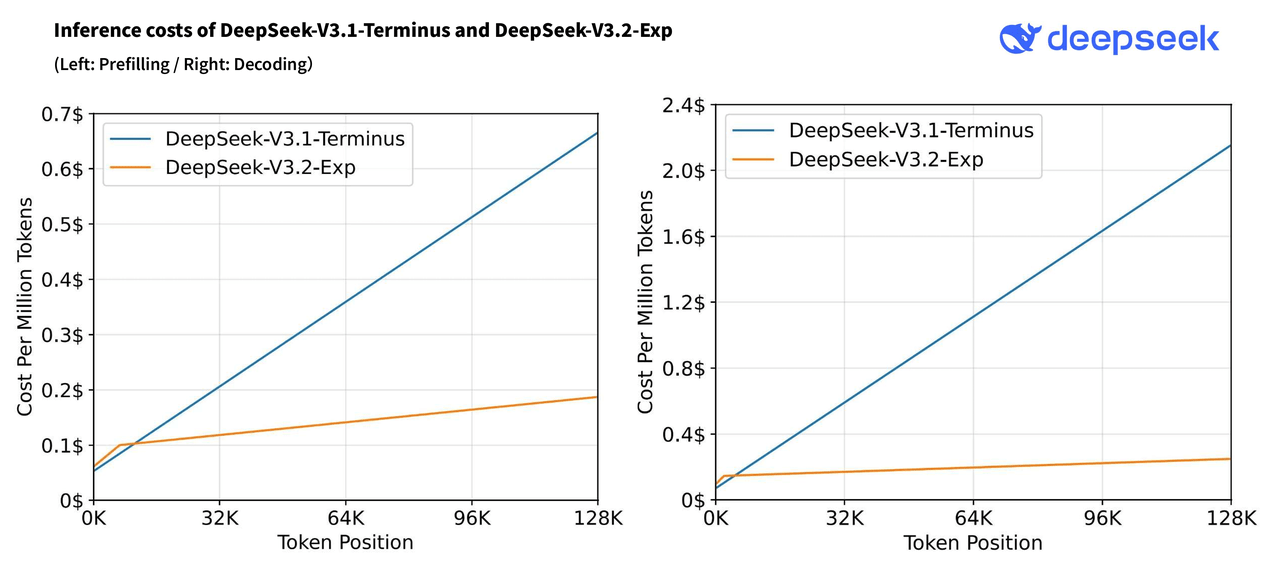
AI 서비스의 가장 큰 걸림돌, 추론 비용
아무리 뛰어난 AI 모델이라도 운영 비용이 높으면 실제 활용이 제한됩니다. 특히 장문맥(long-context) 처리는 비용 폭증의 주범이었습니다. 128,000토큰 컨텍스트를 처리할 때마다 기존 방식은 디코딩 비용만 약 2.2달러가 들었습니다.
DeepSeek V3.2-Exp는 이 비용을 0.25달러로 줄였습니다. 거의 10분의 1 수준입니다. API 가격도 구체적으로 입력 캐시 히트 시 백만 토큰당 0.07달러에서 0.028달러로, 캐시 미스 시 0.56달러에서 0.28달러로, 출력 비용은 1.68달러에서 0.42달러로 떨어졌습니다.
DeepSeek Sparse Attention, 어떻게 작동하나
기존 트랜스포머 모델의 어텐션 메커니즘은 모든 토큰을 전부 살펴봅니다. 문제는 이 과정의 계산 복잡도가 O(L²)라는 점입니다. 텍스트 길이가 두 배가 되면 계산량은 네 배로 늘어납니다.
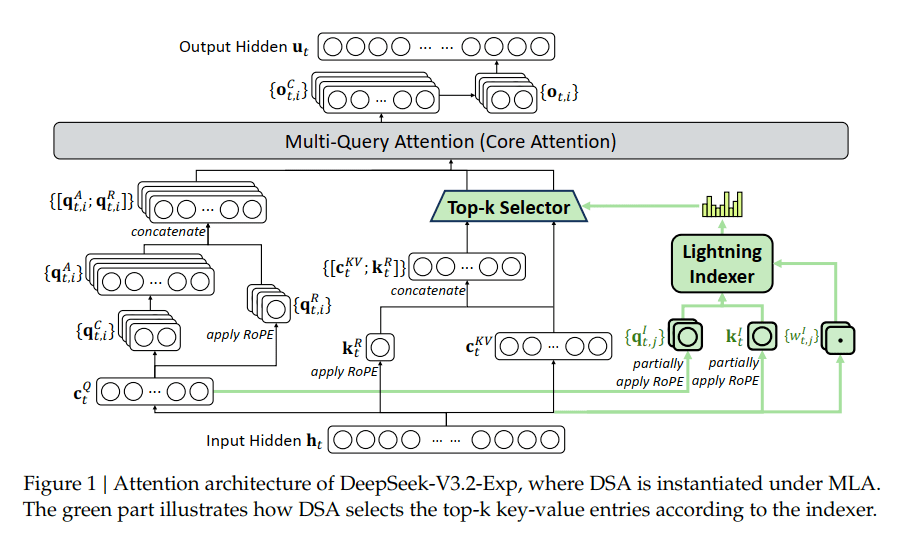
DeepSeek Sparse Attention(DSA)은 두 단계로 이 문제를 해결합니다.
Lightning Indexer(번개 인덱서): 초경량 스캐너가 빠르게 모든 토큰을 훑으며 각 단어의 중요도를 점수화합니다. FP8 정밀도로 작동하여 연산 부담이 극히 작습니다.
Fine-grained Token Selection(정밀 토큰 선택): 인덱서가 매긴 점수를 바탕으로 가장 중요한 상위 K개 토큰만 골라냅니다. 실제 어텐션 메커니즘은 이렇게 선별된 토큰만 처리합니다.
결과적으로 계산 복잡도는 O(Lk)로 떨어집니다. 여기서 k는 고정된 선택 토큰 수입니다. 텍스트가 길어져도 계산량은 선형적으로만 증가합니다.
숫자로 보는 실제 성과
DeepSeek이 공개한 벤치마크 결과는 명확합니다. V3.2-Exp는 이전 모델인 V3.1-Terminus와 전반적으로 동등한 성능을 보여줍니다. 그러면서도 효율성은 크게 개선됐습니다.
추론 속도는 장문맥 처리에서 2~3배 빨라졌습니다. 메모리 사용량은 30~40% 감소했습니다. 훈련 속도는 50% 향상됐습니다. 가장 인상적인 건 128K 컨텍스트 윈도우 처리 시 디코딩 비용이 10분의 1로 떨어진 점입니다.
흥미로운 건 태스크별 성능 차이입니다. 코딩(Codeforces: 2046→2121점) 태스크에서는 오히려 성능이 향상됐습니다. 에이전트 작업(BrowseComp: 38.5%→40.1%)도 마찬가지입니다. 코드나 도구 사용 태스크는 중복 정보가 많은데, DSA가 노이즈를 효과적으로 필터링하기 때문입니다.
반면 극도로 복잡한 추상 추론 벤치마크(GPQA Diamond, HMMT)에서는 소폭 하락했습니다. 미묘한 장거리 의존성을 놓치는 경우가 있기 때문으로 분석됩니다.
오픈소스로 공개된 실용성
DeepSeek은 모델 가중치를 Hugging Face에, 핵심 GPU 커널을 GitHub에 모두 공개했습니다. SGLang과 vLLM 같은 인기 추론 프레임워크도 출시 첫날부터 지원합니다.
개발자들은 Docker 이미지를 받아 즉시 사용할 수 있습니다. H200, MI350X, NPU 등 다양한 하드웨어를 지원하며, 각각에 최적화된 컨테이너를 제공합니다. 명령어 한 줄이면 8개 GPU 텐서 병렬 처리가 가능합니다.
docker pull lmsysorg/sglang:dsv32
python -m sglang.launch_server --model deepseek-ai/DeepSeek-V3.2-Exp --tp 8 --dp 8 --page-size 64연구자들을 위해 TileLang 버전도 제공됩니다. 가독성이 높아 프로토타입 개발에 적합합니다. 프로덕션 환경을 위한 고성능 CUDA 커널은 DeepGEMM과 FlashMLA 저장소에서 찾을 수 있습니다.

실무자들에게 주는 의미
이번 발표는 AI 업계에 중요한 신호를 보냅니다. 더 나은 AI를 만드는 방법이 반드시 ‘더 크게’만은 아니라는 점입니다. 효율성 개선만으로도 비용을 극적으로 줄이면서 성능을 유지할 수 있습니다.
장문맥 처리가 필요한 서비스를 운영 중이라면 V3.2-Exp를 테스트해볼 가치가 충분합니다. 전체 코드베이스 분석, 법률 문서 처리, 대규모 데이터셋 작업이 이제 현실적인 비용으로 가능해졌습니다. DeepSeek API의 deepseek-chat과 deepseek-reasoner는 이미 V3.2-Exp로 업그레이드되었고, 비교 테스트를 위해 V3.1-Terminus도 10월 15일까지 임시로 제공됩니다.
⚠️ 이 글은 AI 모델이 정리한 내용을 기반으로 작성되었으며, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다.
참고자료:
- DeepSeek-V3.2-Exp GitHub Repository
- Introducing DeepSeek-V3.2-Exp – DeepSeek API Docs
- SGLang Day 0 Support for DeepSeek-V3.2 – LMSYS
- DeepSeek releases ‘sparse attention’ model that cuts API costs in half – TechCrunch
- DeepSeek-V3.2-Exp: 50% Cheaper, 3x Faster, Maximum Value – Analytics Vidhya
- DeepSeek Has ‘Cracked’ Cheap Long Context for LLMs – Analytics India Magazine
답글 남기기