“15만원 이하 마라톤 러닝화 추천해줘.” 이런 질문을 받으면 벡터 검색은 어떻게 답할까요? 텍스트는 이해하지만 가격은 놓치고, 용도는 파악하지만 예산은 무시합니다. 검색엔진 Algolia CTO는 ChatGPT 출시 6개월 후 검색 쿼리당 키워드 개수가 2배 증가했다고 말했습니다. 사용자들이 이제 더 길고 구체적인 질문을 던진다는 뜻이죠. 하지만 대부분의 벡터 검색은 여전히 텍스트만 이해합니다.

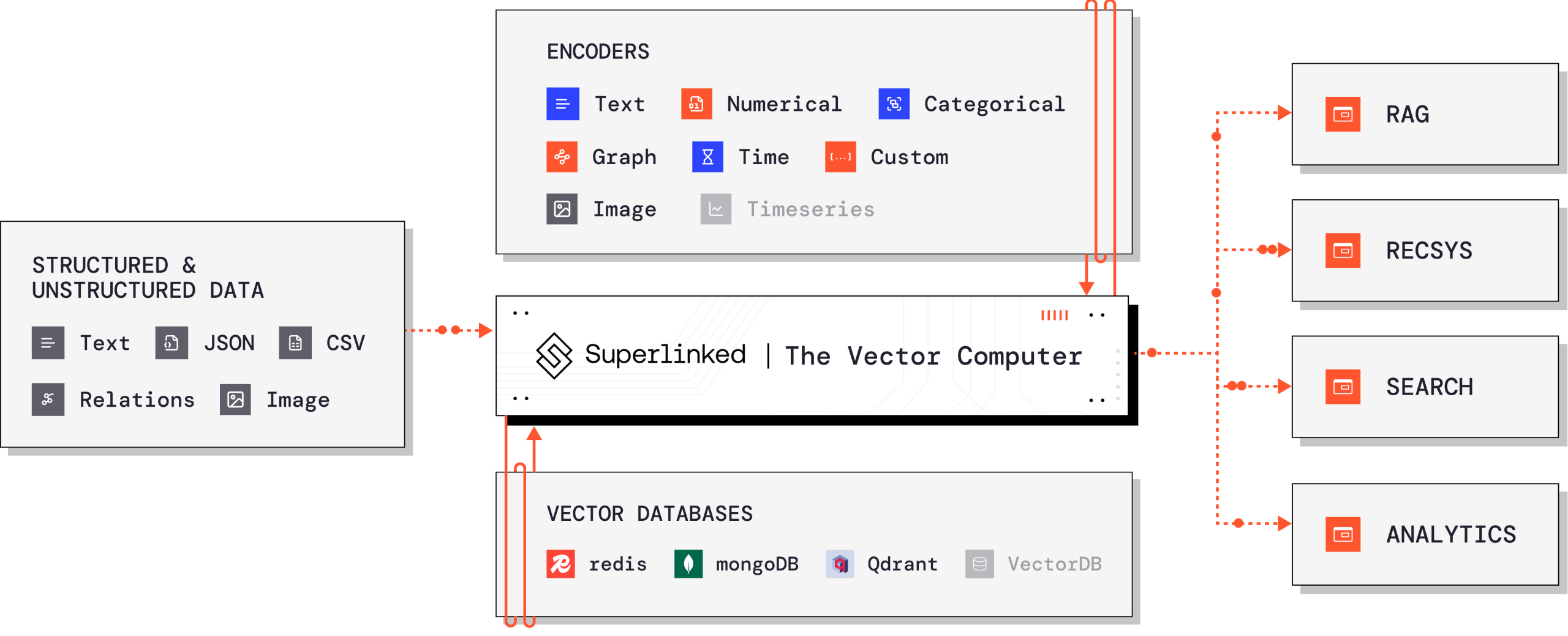
Superlinked는 이 문제를 정면으로 다루는 오픈소스 Python 프레임워크입니다. 텍스트 임베딩만으로는 처리할 수 없는 숫자, 카테고리, 시간 데이터를 벡터와 함께 인코딩하는 구조화된 방법을 제공합니다. RAG, 검색, 추천 시스템을 구축하는 AI 엔지니어들을 위한 실용적 도구죠.
출처: Superlinked GitHub – Superlinked
텍스트 임베딩만으로는 부족하다
벡터 검색의 기본 가정은 간단합니다. 의미가 비슷한 텍스트는 벡터 공간에서도 가까이 위치한다는 것이죠. 하지만 실제 검색 쿼리는 텍스트만으로 이루어지지 않습니다.
“최근 농작물 수확량 관련 뉴스”를 찾는다고 해봅시다. 여기엔 세 가지 요소가 있습니다. ‘농작물 수확량’이라는 주제(텍스트), ‘최근’이라는 시간 조건, 그리고 ‘뉴스’라는 카테고리. 텍스트 임베딩은 주제는 잘 파악하지만 시간과 카테고리는 제대로 처리하지 못합니다.
더 심각한 문제도 있습니다. Superlinked 팀이 OpenAI의 임베딩 API로 0부터 100까지의 숫자를 임베딩한 뒤 코사인 유사도를 계산했더니 예측 불가능한 결과가 나왔습니다. 50과 51이 멀고, 10과 90이 가깝게 나오는 식이죠. 숫자를 문자열로 바꿔서 임베딩하면 이런 일이 벌어집니다.
그럼 메타데이터 필터를 쓰면 되지 않냐고요? 가능은 합니다. 먼저 벡터 검색으로 후보를 찾고, 그 다음 가격이나 날짜로 필터링하는 방식이죠. 하지만 이건 임시방편입니다. 벡터 검색 단계에서 이미 중요한 후보들을 놓쳤을 수 있거든요. 15만원짜리 완벽한 러닝화가 벡터 공간에서 조금 멀리 있다는 이유로 후보군에서 제외됐다면, 필터링 단계에선 이미 늦었습니다.
Superlinked의 접근: 메타데이터를 벡터에 녹이기
Superlinked는 다른 방식을 택합니다. 메타데이터를 별도로 처리하는 게 아니라 처음부터 벡터와 함께 인코딩하는 거죠. 텍스트는 sentence-transformers나 open-clip 같은 기존 모델로 처리하고, 숫자와 카테고리, 시간 데이터는 전용 인코더로 처리합니다. 그런 다음 이 모든 걸 하나의 통합 벡터 공간으로 결합합니다.
실제 코드를 보면 이해가 빠릅니다. 상품 검색 시스템을 만든다고 해봅시다:
from superlinked import framework as sl
class Product(sl.Schema):
id: sl.IdField
description: sl.String
rating: sl.Integer
product = Product()
# 텍스트는 텍스트대로
description_space = sl.TextSimilaritySpace(
text=product.description,
model="Alibaba-NLP/gte-large-en-v1.5"
)
# 숫자는 숫자대로 (1~5점 범위, 최대값 선호)
rating_space = sl.NumberSpace(
number=product.rating,
min_value=1,
max_value=5,
mode=sl.Mode.MAXIMUM
)
# 둘을 결합한 인덱스 생성
index = sl.Index([description_space, rating_space])이제 “최고급 칫솔”이라고 검색하면 설명과 평점을 동시에 고려합니다. 평점 5점짜리 고급 칫솔이 평점 1점짜리 저가 칫솔보다 높은 순위에 오르죠. 메타데이터가 벡터 검색의 일부가 된 겁니다.
더 흥미로운 건 쿼리 시점에 가중치를 조절할 수 있다는 점입니다:
query = sl.Query(
index,
weights={
description_space: sl.Param("description_weight"),
rating_space: sl.Param("rating_weight")
}
)어떤 사용자는 가격에 민감하고, 어떤 사용자는 품질을 우선시합니다. 같은 인덱스로 개인화된 검색 결과를 만들 수 있는 거죠.
시간과 카테고리도 마찬가지
숫자만 특별 대우를 받는 건 아닙니다. Superlinked는 시간 데이터를 위한 RecencySpace, 카테고리를 위한 CategoricalSimilaritySpace, 심지어 특정 이벤트의 영향을 모델링하는 EventEffects까지 제공합니다.
뉴스 검색을 생각해봅시다. “최근” 기사를 원한다면 RecencySpace가 시간 경과에 따라 점수를 감소시킵니다. 일주일 전 기사는 한 달 전 기사보다 높은 점수를 받죠. 이건 단순히 날짜로 정렬하는 것과 다릅니다. 관련성과 최신성을 동시에 고려한 순위가 나옵니다.
카테고리는 어떨까요? “스포츠 뉴스” 중에서 “축구” 기사를 찾는다면 계층적 카테고리 관계를 이해해야 합니다. CategoricalSimilaritySpace는 이런 관계를 벡터 공간에 반영합니다.
프로토타입부터 프로덕션까지
Superlinked는 노트북에서 실험하다가 바로 프로덕션으로 옮길 수 있게 설계됐습니다. 같은 코드로 세 가지 실행 방식을 지원하거든요.
개발 초기엔 InMemoryExecutor로 빠르게 테스트하고, 준비가 되면 superlinked-server 패키지로 REST API 서버를 띄웁니다. 벡터 데이터베이스도 Redis, MongoDB, Qdrant 같은 주요 옵션들을 지원하죠. 인프라를 바꿔도 임베딩 로직은 그대로입니다.
한계와 고려사항
물론 만능은 아닙니다. 일단 학습 곡선이 있습니다. Space, Index, Query 같은 새로운 개념을 익혀야 하고, 각 데이터 타입에 맞는 인코더를 선택해야 하죠. 단순히 OpenAI API 한 줄로 해결되지 않습니다.
성능 오버헤드도 고려해야 합니다. 여러 Space를 결합하면 벡터 차원이 커지고 검색 속도가 느려질 수 있습니다. 어떤 메타데이터를 인코딩할지, 어떤 건 필터로 남길지 신중하게 판단해야 합니다.
그리고 이건 프레임워크입니다. 즉, 직접 코드를 작성해야 한다는 뜻이죠. Pinecone이나 Weaviate 같은 관리형 서비스가 아니라 직접 설정하고 관리하는 도구입니다. 유연성과 통제권을 얻는 대신 책임도 함께 따라옵니다.
벡터 검색의 다음 단계
Superlinked가 제시하는 방향은 명확합니다. 메타데이터는 검색의 부속품이 아니라 핵심 요소라는 것, 그리고 이를 벡터 공간에 통합하는 구조화된 방법이 필요하다는 것이죠.
텍스트 임베딩만으로 해결하려던 시대는 지나가고 있습니다. 사용자들은 이미 더 복잡한 질문을 던지고 있고, AI 검색은 이에 답할 준비가 되어 있어야 합니다. Superlinked는 그 준비를 돕는 도구 중 하나입니다. 완벽하진 않지만, 방향은 옳습니다.
참고자료:
답글 남기기