AI 에이전트를 10개 만들면 관리가 복잡해지고, 100개를 만들면 시스템이 느려지고 비용이 폭발합니다. 모든 에이전트에게 매번 질문을 던질 수는 없으니까요. 그렇다면 수십~수백 개의 전문 에이전트를 어떻게 효율적으로 조율할까요?

Microsoft의 ISE(Industry Solutions Engineering) 팀이 실제 상용 멀티 에이전트 시스템을 구축하면서 발견한 핵심 패턴과 최적화 전략을 공유했습니다. 프로토타입이 아닌 실제 고객이 사용하는 e커머스 음성 어시스턴트를 만들며 겪은 문제들과 그 해결책이 담겨 있죠.
출처: Patterns for Building a Scalable Multi-Agent System – Microsoft ISE Developer Blog
문제의 본질: 에이전트가 많아질수록 느려진다
한 e커머스 회사가 AI 음성 어시스턴트를 만들고 있습니다. 주문 추적, 반품 처리, 상품 추천, FAQ 답변 등 각각의 업무를 처리하는 전문 에이전트들이 있죠. 고객은 어떤 질문이든 할 수 있으니, 시스템은 고객의 의도를 파악해서 적합한 에이전트를 실행해야 합니다.
가장 단순한 방법은 모든 에이전트를 매번 LLM에 전달하는 겁니다. 하지만 에이전트가 수십 개만 넘어가도 토큰 사용량(즉 비용)과 응답 시간이 감당할 수 없을 정도로 늘어나죠. “내 주문 어디쯤 왔어?”라는 질문에 반품 에이전트, 프로모션 에이전트까지 모두 참여시킬 필요는 없습니다.
핵심은 사용자 질문과 관련된 소수의 에이전트만 동적으로 선택하는 것입니다. 그리고 여러 에이전트가 필요한 복잡한 질문에서는 순서를 조율하고 일관된 답변을 만들어내야 하고요.
해결책: 4가지 핵심 패턴
Microsoft 팀은 다음 네 가지 패턴으로 이 문제를 풀었습니다.
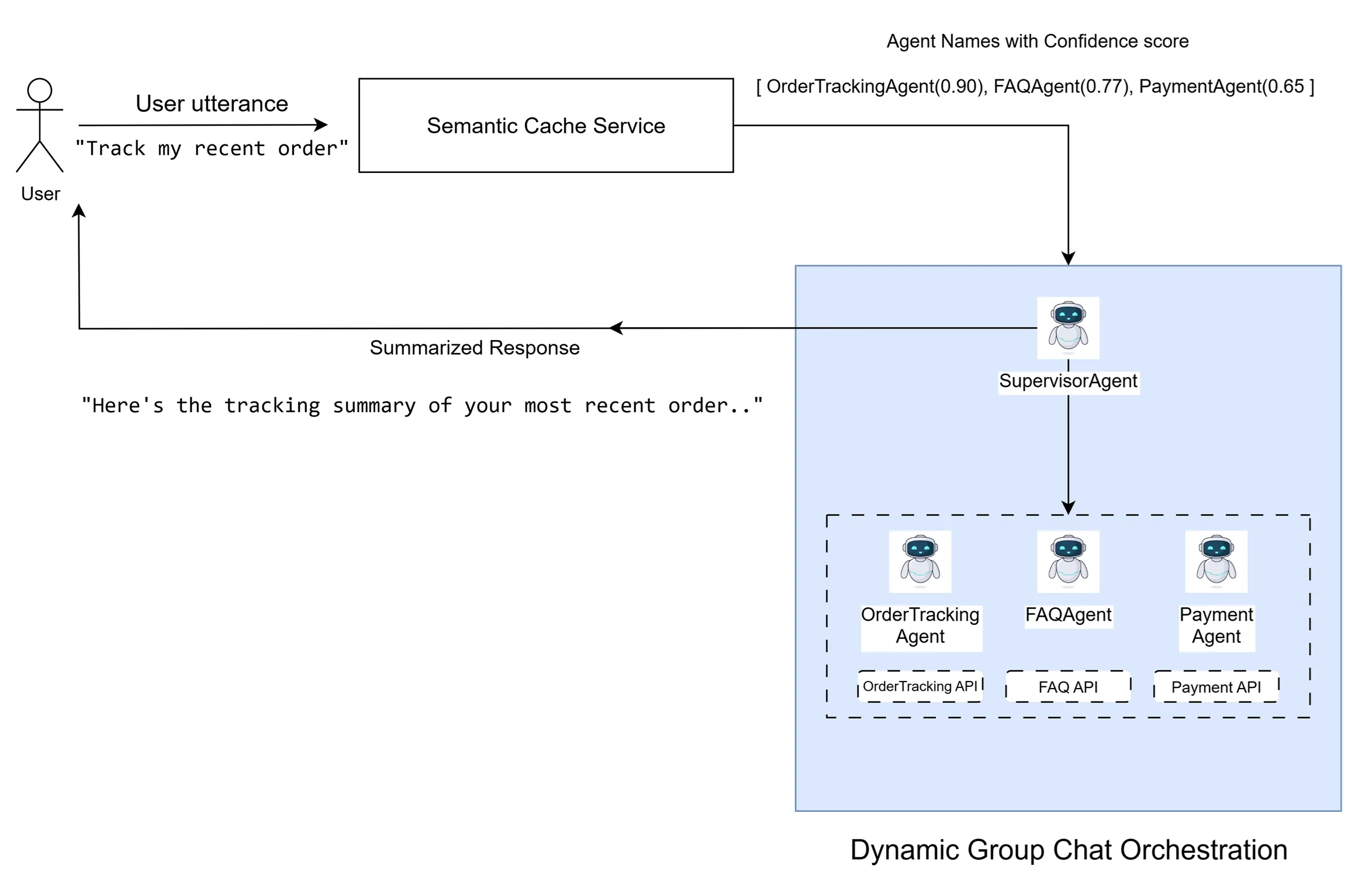
1. Semantic Cache로 관련 에이전트만 골라내기
모든 에이전트의 이름과 샘플 질문들(“최근 주문 추적해줘”, “지난 3개 주문 상태 알려줘”)을 임베딩으로 변환해서 Azure AI Search에 인덱싱합니다. 사용자 질문이 들어오면 그것도 임베딩으로 바꿔서 유사도 점수가 높은 에이전트만 추려내는 거죠.
예를 들어 “최근 주문 추적해줘”라는 질문은 OrderTrackingAgent와 매칭되고, “노트북 추천해줘”는 ProductRecommendationAgent와 연결됩니다. OpenAI의 text-embedding-3-small 같은 다국어 임베딩 모델을 쓰면 한국어, 영어 등 여러 언어를 지원할 수 있습니다.
팁: 에이전트당 최소 5개 이상의 다양한 샘플 질문을 추가하면 검색 정확도가 크게 향상됩니다.
2. Factory 패턴으로 에이전트 생성 표준화
에이전트가 많아지면 새로운 에이전트를 추가하는 과정 자체가 복잡해집니다. Microsoft 팀은 Factory Design Pattern을 활용해 AgentFactory를 만들었습니다. 에이전트 정의를 코드(Python 파일)나 설정 템플릿(YAML 파일)로 작성하면, AgentFactory가 이름만 받아서 자동으로 에이전트 객체를 생성하죠.
재미있는 건 우선순위 설정입니다. 만약 X_Agent.py와 x_agent.yaml이 둘 다 있으면 YAML을 우선 사용하도록 설정할 수 있습니다. 코드를 고치지 않고도 설정 파일만 바꿔서 에이전트 동작을 오버라이드할 수 있는 거죠.
3. SupervisorAgent가 대화 흐름 조율
이제 관련 에이전트를 찾아냈지만, 또 다른 문제가 있습니다. “X면 Y를 해줘”처럼 여러 의도가 섞인 질문은 어떻게 처리할까요? 그리고 각 에이전트의 답변을 따로따로 보여주는 게 아니라 하나로 정리된 답변을 만들어야 하고요.
여기서 SupervisorAgent가 등장합니다. 이 특별한 에이전트는 중앙 조율자 역할을 합니다. 사용자 의도를 파악하고, 어떤 에이전트를 다음에 실행할지 결정하고, 모든 관련 에이전트가 기여할 때까지 반복하며, 적절한 시점에 대화를 종료하죠.
Microsoft Semantic Kernel의 Group Chat 같은 프레임워크는 Selection(다음 에이전트 선택)과 Termination(종료 조건) 전략을 명시적으로 제공합니다. 다른 프레임워크를 쓴다면 SupervisorAgent의 LLM 명령어에 이런 로직을 직접 구현하면 됩니다.
4. 단일 의도는 바로 실행 (최적화)
모든 질문이 복잡한 건 아닙니다. “내 주문 어디쯤 왔어?”처럼 명확하게 하나의 에이전트만 필요하고, Semantic Cache의 신뢰도 점수가 매우 높다면 SupervisorAgent를 거치지 않고 바로 해당 에이전트를 실행합니다. 불필요한 LLM 추론을 건너뛰어 속도와 비용을 절약하는 거죠.
실전에서 마주친 문제들
에이전트가 계속 수다를 떤다
개발 중에 에이전트들이 무한 루프처럼 대화를 이어가며 결론을 내리지 못하는 “수다 문제(chattiness)”가 발생했습니다. 대부분의 오케스트레이션 프레임워크는 max_iterations 같은 속성으로 그룹 채팅 반복 횟수를 제한할 수 있습니다.
예를 들어 한 질문에 최대 2개의 의도를 처리한다면, SupervisorAgent와의 상호작용까지 고려해서 max_iterations를 3 정도로 설정합니다. 그래도 수다가 멈추지 않는다면 에이전트 간 상호작용을 디버깅해서 근본 원인을 찾아야 하죠.
LLM 파라미터 튜닝
일관된 응답을 위해 temperature와 top_p를 0으로 설정하면 무작위성이 줄어듭니다. max_completion_tokens는 예상되는 답변 길이에 맞춰 설정해서 불필요하게 장황한 답변을 방지하고요.
철저한 평가와 반복
Microsoft 팀은 전체 시스템과 개별 구성 요소를 모두 평가했습니다. 각 에이전트는 정답 데이터셋을 유지하며, recall@k, precision@k, BLEU 스코어, 관련성 같은 지표로 성능을 측정하죠. 새 에이전트를 추가할 때는 기존 에이전트와 겹치지 않는 명확한 설명과 샘플을 제공해야 하고, 전체 시스템 품질이 기준을 충족하는지 확인합니다.
결과: 확장 가능하고 효율적인 시스템
이 아키텍처는 낮은 레이턴시와 통제된 토큰 사용량, 높은 선택 정확도를 갖춘 확장 가능한 멀티 에이전트 시스템을 만들어냈습니다. 동적 검색과 Supervisor 오케스트레이션 덕분에 복잡한 다중 의도 질문에도 일관되고 순서가 정리된 답변을 제공할 수 있죠.
이 패턴들은 음성 어시스턴트를 넘어서 의도에 따라 전문 에이전트를 동적으로 조합해야 하는 모든 AI 워크플로에 적용할 수 있습니다. 에이전트 생태계가 커질수록 체계적인 평가와 운영 매뉴얼이 지속적인 성능의 핵심이 되겠죠.
참고자료:
답글 남기기