최근 AI를 활용한 비디오 생성 기술이 급속도로 발전하고 있습니다. OpenAI의 Sora, Runway의 Gen-3 등 다양한 기업에서 텍스트 프롬프트만으로 놀라울 정도로 사실적인 비디오를 생성하는 AI 모델을 선보이고 있죠. 그러나 이러한 최첨단 비디오 생성 모델은 대부분 수백만 달러에 달하는 개발 비용과 막대한 컴퓨팅 자원이 필요한 것으로 알려져 있습니다.
그런데 최근 HPC-AI Tech의 연구팀이 발표한 ‘Open-Sora 2.0’은 이런 상식을 뒤엎는 성과를 보여주었습니다. 단 20만 달러라는 비교적 적은 비용으로 상용 수준의 텍스트-투-비디오(text-to-video) 생성 모델을 구축한 것입니다. 이는 기존 모델 대비 5-10배나 적은 비용으로, 그럼에도 불구하고 OpenAI의 Sora와 같은 고급 모델에 필적하는 품질의 비디오를 생성할 수 있습니다.

Open-Sora 2.0으로 생성된 비디오 예시 (출처: GitHub hpcaitech/Open-Sora)
Open-Sora 2.0이 어떻게 이러한 효율적인 모델 개발에 성공했는지, 그리고 이 기술이 향후 AI 비디오 생성 분야에 어떤 영향을 미칠지 살펴보겠습니다.
텍스트-투-비디오 생성의 도전과제
텍스트-투-비디오 생성은 텍스트-투-이미지 생성보다 훨씬 복잡한 작업입니다. 단일 이미지를 생성하는 것을 넘어, 시간의 흐름에 따라 일관성 있게 이어지는 이미지 시퀀스를 만들어야 하기 때문입니다. 장면의 세밀한 공간적 디테일뿐만 아니라 동작이 자연스럽고 현실적으로 이어져야 하죠.
이런 시간적 차원의 추가는 완전히 새로운 복잡성과 비용을 가져옵니다. 특히 AI 시스템은 사실 시간이라는 개념을 직접적으로 이해하지 못합니다. 이들은 단지 단어나 픽셀과 같은 ‘토큰’만을 처리할 뿐, 인간이 유아기 때 시행착오를 통해 발달시키는 물리 법칙에 대한 이해가 없습니다. AI는 오직 토큰을 통해 우리 세계에 접근하기 때문에, 비디오의 시간적 일관성을 유지하는 것은 극도로 어려운 과제입니다.
 Open-Sora의 글로벌 아키텍처 (이미지 출처: Open-Sora 2.0 보고서)
Open-Sora의 글로벌 아키텍처 (이미지 출처: Open-Sora 2.0 보고서)
Open-Sora 2.0의 접근 방식
텍스트-투-비디오 생성에는 크게 두 가지 접근 방식이 있습니다.
- 직접 접근 방식: 텍스트를 직접 비디오로 변환하도록 모델을 훈련시키는 것으로, 모델이 고품질 이미지 생성과 일관된 동작 연결을 한 번에 학습해야 합니다.
- 단계적 접근 방식: 문제를 두 단계로 나누어, 먼저 텍스트 프롬프트에서 고품질 이미지를 생성하는 모델을 훈련시킨 후, 그 모델과 생성된 이미지를 조건 신호로 사용하여 비디오를 생성합니다.
Open-Sora 2.0은 두 번째 접근 방식을 채택했습니다. 이미지 생성에서 이미 검증된 성숙한 기술을 활용하고, 처음부터 전체 엔드-투-엔드 파이프라인을 훈련시키는 대신 기존 모델을 기반으로 구축했기 때문입니다. 이렇게 함으로써 개발 과정을 단순화하고, 전체적인 복잡성을 줄이며, 필요한 컴퓨팅 및 데이터 리소스를 크게 절감할 수 있었습니다.
세 단계의 효율적인 훈련 과정
Open-Sora 2.0의 훈련 과정은 컴퓨팅 자원을 절약하고 비용을 절감하면서도 최첨단 성능을 달성하기 위해 최적화된 세 단계로 구성되어 있습니다.

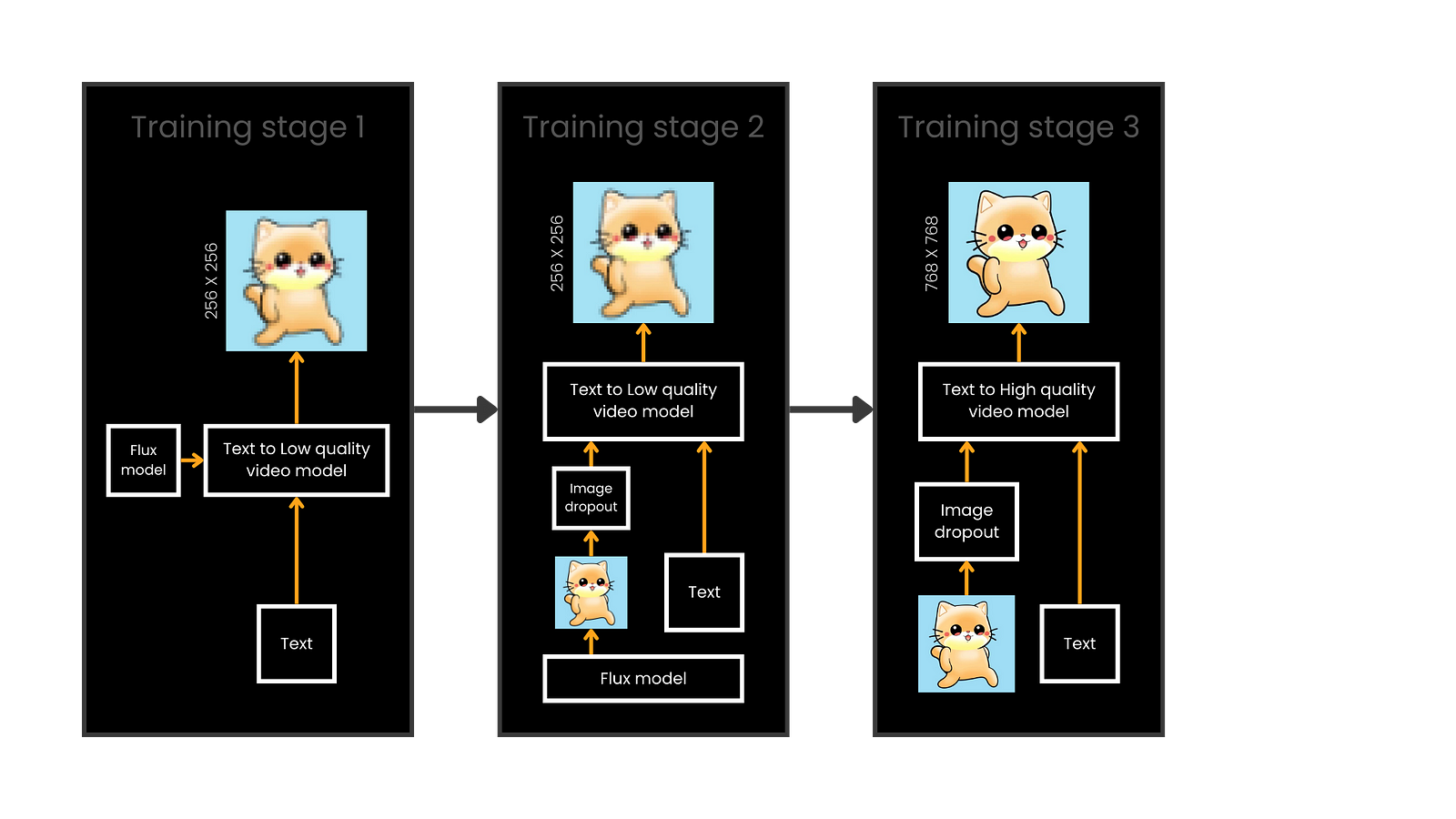
Open-Sora 2.0의 3단계 훈련 과정 (이미지 출처: Louis Bouchard)
각 단계별 훈련 과정에서 소요된 비용은 다음과 같습니다:
- 1단계 (저해상도 텍스트-투-비디오): 약 10만 달러 (2,240 GPU일)
- 2단계 (이미지-투-비디오 전환): 약 1.8만 달러 (384 GPU일)
- 3단계 (고해상도 확장): 약 7.3만 달러 (1,536 GPU일)
총 합계 약 20만 달러로, 경쟁 모델들이 수백만 달러를 소요한 것과 비교하면 놀라운 비용 효율성을 보여줍니다.
1단계: 저해상도 텍스트-투-비디오 모델 구축
첫 번째 단계의 목표는 256×256 픽셀의 저해상도에서 견고한 텍스트-투-비디오 모델을 구축하는 것입니다. 연구팀은 처음부터 시작하는 대신, 이미 강력한 FLUX 모델(110억 파라미터를 가진 텍스트-투-이미지 확산 모델)을 기반으로 시작했습니다.
이 FLUX 모델은 이미 심층적인 시각적 이해 능력을 갖추고 있어서 완벽한 기반이 됩니다. 하지만 비디오 생성을 위해서는 공간적 일관성뿐 아니라 시간적 일관성(부드럽고 믿을 수 있는 움직임)도 필요합니다. 이러한 시간적 차원을 효율적으로 추가하기 위해 Open-Sora는 MM-DiT(멀티모달 확산 트랜스포머)에서 영감을 받은 고급 아키텍처를 사용합니다.
MM-DiT는 특히 텍스트 인코딩을 위해 CLIP-L과 T5-XXL이라는 두 개의 강력한 사전 훈련된 텍스트 모델을 활용합니다. CLIP-L은 강력한 기본 텍스트-시각적 정렬을 제공하고, T5-XXL은 더 깊은 의미론적 이해를 제공하여 특히 상세하고 복잡한 텍스트 컨텍스트를 캡처하는 데 유리합니다.
이 초기 단계에서 Open-Sora는 256×256 픽셀 해상도의 약 7천만 개의 짧은 비디오 샘플로 구성된 방대하고 신중하게 큐레이션된 데이터셋을 사용합니다. 이 데이터셋은 다양한 공개 비디오 소스에서 얻어 필터링하고 엄격하게 처리해 효과적인 훈련에 적합한 고품질, 다양한 콘텐츠를 보장했습니다. 이 단계는 2,240 GPU 일과 10만 달러 조금 넘는 비용이 소요되었습니다.
2단계: 이미지-투-비디오 전환
두 번째 단계에서는 텍스트-투-비디오 생성에서 이미지-투-비디오 생성으로 전환하며, 여전히 256×256 픽셀 해상도를 유지합니다. 이 단계에서는 텍스트 프롬프트에만 의존하는 대신, 모델이 단일 이미지를 짧은 비디오로 확장하는 방법을 학습합니다.
이를 위해 초기 이미지를 인코딩하고 추가 정보로 잠재 비디오 표현에 연결하는 방식으로 조건부 방법을 수정했습니다. 이러한 조정으로 모델은 장면 생성의 복잡성과 별개로 명시적인 동작 생성을 학습할 수 있습니다. FLUX 사전 생성 이미지의 정보를 활용해 순수하게 동작에 집중함으로써 훈련이 더 빠르고, 데이터가 덜 집약적이며, 훨씬 저렴해졌습니다.
또한 팀은 이미지 조건부에 대한 드롭아웃 메커니즘을 도입했습니다. 이는 모델이 때때로 초기 이미지 없이 비디오를 생성하도록 강제하여 텍스트-투-비디오 기능을 날카롭게 유지하고 사전 생성된 이미지에 완전히 의존하지 않도록 합니다.
이 단계에서 팀은 약 1천만 개의 신중하게 선택된 고품질 비디오 샘플이 포함된 축소된 데이터셋을 활용했습니다. 또한 FLUX 모델에서 이전에 생성된 이미지를 재사용함으로써 계산 요구 사항이 크게 감소하여 약 384 GPU 일 또는 1만 8천 달러만 필요했습니다.
3단계: 고해상도 확장
세 번째이자 마지막 단계는 이 모델을 개선하고 768×768 픽셀의 고해상도 비디오로 확장하는 것입니다. 그러나 직접 고해상도로 점프하는 것은 엄청나게 비싸기 때문에, Open-Sora는 비디오 깊은 압축 오토인코더(Video DC-AE)라는 새로운 아키텍처를 채택했습니다.
Video DC-AE는 이전에 이미지용으로 만들어진 깊은 압축 오토인코더(DC-AE) 접근 방식에서 영감을 받았으며, 2차원이 아닌 3차원 합성곱을 추가해 비디오용으로 변환되었습니다. Open-Sora는 공간 압축 비율을 4배로 크게 늘려 32로 만들면서 시간적 압축 비율은 4를 유지했습니다. 이러한 조정으로 처리되는 공간 토큰의 수가 효과적으로 감소하여 계산 효율성이 크게 향상되고 필수적인 동작 특성이 보존되었습니다.
이 마지막 단계에서 그들은 데이터셋을 약 500만 개의 신중하게 선택된 고품질 비디오 샘플로 더욱 압축했으며, 이 단계에는 약 1,536 GPU 일 또는 7만 3천 달러가 소요되었습니다.
오픈 소스로 공개된 혁신
Open-Sora 2.0은 완전히 오픈 소스로 공개되어 있어 모든 사람이 이 흥미진진한 비디오 생성 혁명에 참여할 기회를 갖게 되었습니다. 연구팀은 허용적인 Apache 2.0 라이선스 하에 모델을 공개했으며, 이는 상업적 응용도 가능함을 의미합니다.
 Open-Sora 2.0의 데이터 처리 파이프라인 (이미지 출처: Open-Sora 2.0 보고서)
Open-Sora 2.0의 데이터 처리 파이프라인 (이미지 출처: Open-Sora 2.0 보고서)
Open-Sora 2.0의 개발 비용 효율성은 정말 놀랍습니다. MovieGen이나 Step-Video-T2V와 같은 비교 가능한 모델을 훈련시키는 데 일반적으로 수백만 달러의 비용이 드는 반면, Open-Sora 2.0은 시간당 2달러의 H200 GPU를 총 4,160시간 렌트하여 “단” 20만 달러의 훈련 비용으로 매우 유사한 성능 수준을 달성했습니다.
 다양한 모델의 훈련 비용 비교 (이미지 출처: Louis Bouchard)
다양한 모델의 훈련 비용 비교 (이미지 출처: Louis Bouchard)
Open-Sora 2.0과 OpenAI Sora의 비교
OpenAI의 Sora는 최근 놀랍도록 사실적인 비디오를 생성할 수 있는 능력으로 세상을 놀라게 했습니다. 그러나 Sora를 훈련시키는 데 필요한 계산 리소스와 비용은 매우 높은 것으로 추정됩니다. Factorial Funds의 추정에 따르면 Sora는 약 4,200~10,500대의 NVIDIA H100 GPU를 1개월 동안 사용한 것으로 예상되며, 이는 수백만 달러의 비용을 의미합니다.
반면 Open-Sora 2.0은 단 20만 달러의 비용으로 개발되었으며, 이는 Sora보다 훨씬 적은 비용입니다. 그럼에도 불구하고 Open-Sora 2.0은 다른 최고 수준의 모델과 비교했을 때 인상적인 성능을 보여줍니다. 인간 평가 결과에 따르면, Open-Sora 2.0은 시각적 품질, 프롬프트 준수 및 모션 품질의 세 가지 측면 중 최소 두 가지에서 다른 최고 성능 모델보다 우수한 성능을 보였습니다.
 다른 모델과의 비용 비교 (이미지 출처: Open-Sora 2.0 GitHub)
다른 모델과의 비용 비교 (이미지 출처: Open-Sora 2.0 GitHub)
Open-Sora 2.0은 256px과 768px 해상도에서 텍스트-투-비디오와 이미지-투-비디오 생성을 모두 지원하며, 최대 128프레임의 다양한 종횡비의 비디오를 생성할 수 있습니다. 특히 VBench 평가에서는 OpenAI Sora와의 성능 격차가 Open-Sora 1.2의 4.52%에서 Open-Sora 2.0에서는 0.69%로 크게 줄어들었습니다.
왜 이 기술이 중요한가?
Open-Sora 2.0의 개발은, 특히 오픈 소스 커뮤니티에게 매우 중요한 의미를 갖습니다. 이는 고품질 비디오 생성 기술이 더 이상 거대 기업들만의 전유물이 아니라는 것을 보여주기 때문입니다. 기술의 민주화라는 측면에서 큰 진전이라고 할 수 있습니다.
이 기술은 스톡 영상, 교육용 콘텐츠, 엔터테인먼트, 광고 등 다양한 산업 분야에 적용될 수 있습니다. 또한 로보틱스나 자율주행차와 같이 데이터가 본질적으로 부족한 분야에서는 합성 데이터 생성이나 데이터 증강에 활용될 수 있습니다. 실세계 데이터를 대규모로 수집하는 것은 비용이 많이 들며, 희귀 이벤트에 대한 충분한 데이터를 수집하는 것은 어렵기 때문입니다.
또한 Open-Sora 2.0은 “세계 모델(world models)” 연구에 있어서도 중요한 진전을 보여줍니다. 이 모델은 비디오 데이터에서 직접 실제 세계가 어떻게 작동하는지에 대한 기본적인 시뮬레이션을 암시적으로 학습하며, 액체, 빛의 반사, 천의 움직임, 머리카락의 움직임과 같은 매우 복잡한 장면을 시뮬레이션할 수 있습니다.
결론: AI 비디오 생성의 미래
Open-Sora 2.0의 성공은 비디오 모델에 대한 스케일링이 효과적으로 작동한다는 것을 명확히 보여주며, 이는 앞으로 빠른 진전이 이루어질 것임을 시사합니다. DiT 논문의 핵심 통찰력인 모델 품질이 추가 컴퓨팅 능력에 따라 직접적으로 향상된다는 점은 LLM(대규모 언어 모델)에서 관찰된 스케일링 법칙과 유사하며, Open-Sora 2.0은 이러한 스케일링 접근법이 비디오 생성 모델에서도 효과적으로 작동한다는 명확한 증거를 제시했습니다.
 VBench 성능 평가 결과 – Open-Sora 2.0은 OpenAI Sora와의 성능 격차를 현저히 줄였습니다 (이미지 출처: Open-Sora 2.0 GitHub)
VBench 성능 평가 결과 – Open-Sora 2.0은 OpenAI Sora와의 성능 격차를 현저히 줄였습니다 (이미지 출처: Open-Sora 2.0 GitHub)
특히 Open-Sora 2.0의 핵심 기여 중 하나는 이 모든 코드와 모델이 Apache 2.0 라이선스 하에 완전히 오픈 소스로 공개되었다는 점입니다. 이는 기술의 민주화라는 측면에서 대단히 중요합니다. 이제 대규모 자본과 리소스 없이도 연구자들과 개발자들이 최첨단 비디오 생성 기술에 접근하고 이를 발전시킬 수 있게 되었습니다.
오픈 소스 커뮤니티의 기여와 함께, 이러한 기술 발전은 비디오 생성 모델의 대중화를 가속화하고, 더 많은 연구자와 개발자가 이 흥미로운 분야에 참여할 수 있도록 할 것입니다. 결국 이는 더 창의적이고 접근 가능한 AI 생성 콘텐츠의 미래로 이어질 것입니다.
Open-Sora 2.0은 비디오 생성 모델을 훈련시키는 데 필요한 비용과 리소스를 크게 줄이면서도 품질 타협 없이 발전을 이룬 것으로, AI 생성 기술의 발전과 접근성 확대에 중요한 이정표가 될 것입니다.
답글 남기기