RAG 시스템을 만들다 보면 누구나 겪는 문제가 있습니다. 긴 텍스트를 LLM이 처리할 수 있는 크기로 쪼개야 하는데, 단순히 N글자마다 자르면 문장이 반으로 잘려 임베딩 품질이 떨어지죠. 그렇다고 제대로 된 청킹 라이브러리를 쓰자니 너무 느립니다.
그렇다면 이론적 한계는 어디까지일까요? 추상화를 모두 걷어내고 하드웨어 수준까지 내려가면 얼마나 빨라질 수 있을까요?

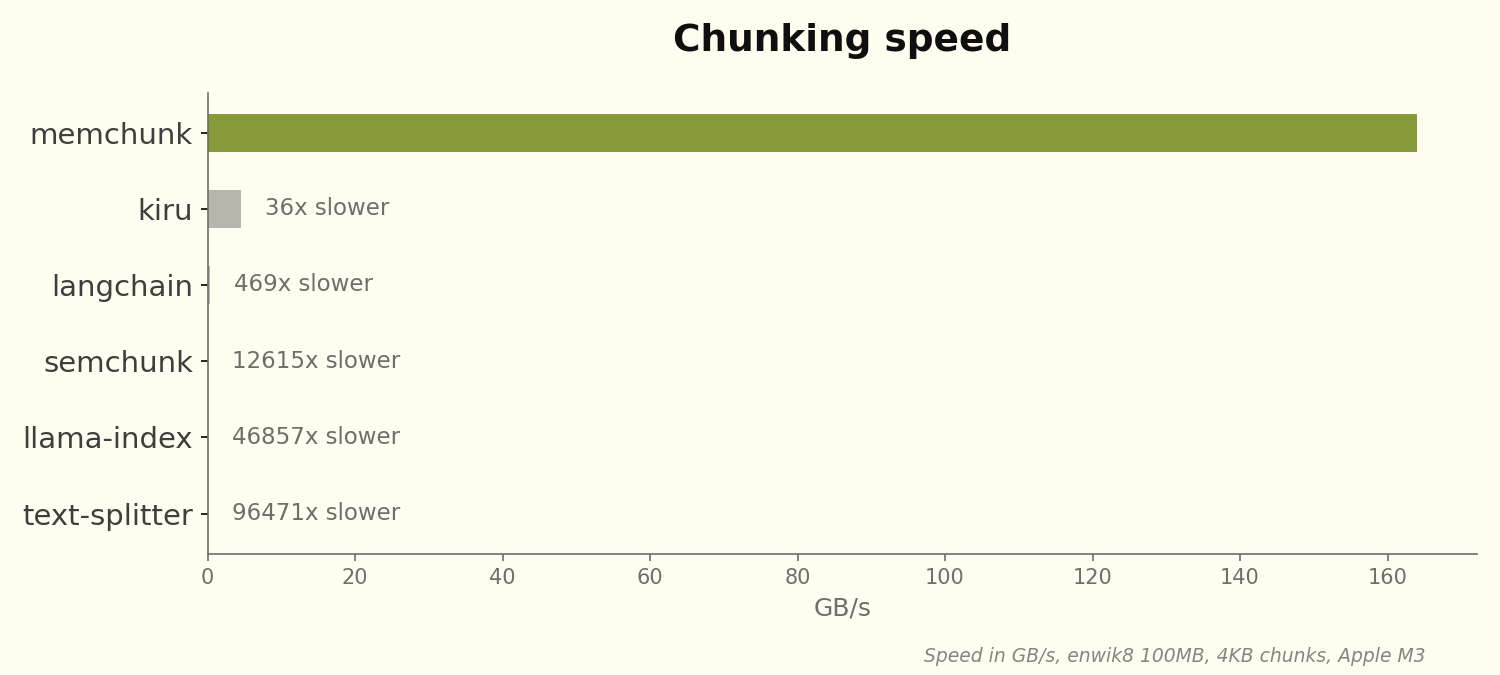
개발자 Bhavnick Minhas가 RAG용 청킹 라이브러리 Chonkie를 만들다가 이 질문에 도달했고, 결과물로 memchunk를 공개했습니다. 핵심은 간단합니다. 문장 구분자(마침표, 물음표 등)를 찾는 작업을 CPU의 SIMD 명령어로 병렬 처리하면 기존 라이브러리보다 최대 96,000배 빠른 164GB/s 속도를 낼 수 있다는 것이죠. 영문 위키백과 전체(20GB)를 120밀리초에 청킹합니다.
출처: so, you want to chunk really fast? – minha.sh
SIMD로 32바이트를 한 번에 검색
memchunk의 핵심은 Rust의 memchr 라이브러리입니다. memchr는 텍스트에서 특정 바이트를 찾는 작업을 SIMD(Single Instruction Multiple Data)로 가속합니다. 일반적인 검색이 텍스트를 한 글자씩 비교한다면, SIMD는 AVX2 명령어로 32바이트를 동시에 비교하죠.
작동 방식은 이렇습니다. 찾으려는 구분자(예: 마침표 .)를 32개 레인에 복사한 벡터를 만듭니다. 그 다음 텍스트에서 32바이트를 읽어와 벡터 비교 명령어로 한 번에 검사하고, 일치하는 위치를 비트마스크로 추출합니다. 마치 32명이 동시에 각자 맡은 글자를 확인하는 것처럼요.
SIMD를 지원하지 않는 환경에서는 SWAR(SIMD Within A Register) 기법을 씁니다. 64비트 정수 연산으로 8바이트를 한 번에 처리하는 트릭인데, XOR와 비트 연산을 조합해 제로 바이트를 감지합니다. 브랜치 없이 순수 연산만으로 동작하기 때문에 여전히 빠릅니다.
3개 이상은 룩업 테이블로
흥미로운 점은 memchr가 최대 3개 구분자까지만 SIMD로 처리한다는 겁니다. 구분자가 4개 이상이면 비교와 OR 연산이 늘어나면서 SIMD의 이점이 희석되거든요. memchr 개발자는 “3개를 넘어가면 체감 효율이 떨어진다”며 의도적으로 제한했습니다.
그렇다면 줄바꿈, 마침표, 물음표, 느낌표, 세미콜론처럼 5개 구분자를 써야 한다면? memchunk는 256칸짜리 불린 배열을 씁니다. 각 바이트 값(0-255)이 구분자인지 미리 표시해두고, 텍스트를 읽을 때 배열 인덱스만 확인하면 끝입니다. 분기도 루프도 없이 단일 배열 참조만으로 판별하죠. SIMD보다는 느리지만 여전히 매우 빠릅니다.
memchunk는 구분자 개수를 보고 자동으로 전략을 선택합니다. 1-3개면 SIMD, 4개 이상이면 룩업 테이블. 사용자는 신경 쓸 필요가 없습니다.
역방향 검색으로 불필요한 연산 제거
마지막 최적화는 검색 방향입니다. 청킹은 “목표 크기에 가장 가까운 구분자”를 찾는 작업인데, 앞에서부터 검색하면 구분자를 발견할 때마다 위치를 저장하고 계속 진행해야 합니다. 목표 크기를 넘어설 때까지 모든 구분자를 확인해야 하죠.
반대로 목표 크기에서 뒤로 검색하면? 첫 번째로 만난 구분자가 답입니다. 한 번의 검색으로 끝나고, 중간 상태를 저장할 필요도 없습니다. memchunk는 memrchr(역방향 memchr)를 써서 연산을 최소화합니다.
실용적인 속도
벤치마크 결과는 압도적입니다. memchunk는 164GB/s, 다음으로 빠른 kiru는 4.5GB/s로 36배 차이가 납니다. text-splitter는 0.0017GB/s로 96,471배 느립니다. 파일 크기가 크고 구분자가 적을수록 SIMD가 더 유리하지만, 최악의 경우(작은 청크, 많은 구분자)에도 수백 GB/s를 유지합니다.
memchunk는 Rust 크레이트뿐 아니라 Python과 WASM 바인딩도 제공합니다. Python에서는 memoryview로 제로카피 슬라이스를 반환하고, JavaScript에서는 Uint8Array.subarray를 씁니다. FFI를 넘어가도 성능이 대부분 유지되죠.
RAG 시스템에서 텍스트 청킹이 병목이었다면, memchunk는 그 병목을 거의 없앤 셈입니다. 기법 자체는 교과서적이지만—SIMD 검색과 룩업 테이블—언제 무엇을 쓸지 아는 것이 차이를 만듭니다. crates.io, PyPI, npm에서 바로 사용할 수 있습니다.
참고자료:
답글 남기기