AI 코딩 에이전트로 코드를 뚝딱 만들어내는 시대가 됐는데, 왜 우리는 여전히 코드베이스를 감당하지 못하는 걸까요?

개발자이자 블로거 Drew Breunig이 MLOps Community의 “Coding Agents” 컨퍼런스에서 발표한 내용을 정리한 글입니다. 코드 없이 스펙과 테스트만으로 출시한 오픈소스 라이브러리 whenwords 실험에서 시작해, AI 코딩 에이전트 시대에 스펙·테스트·코드를 어떻게 동기화할지를 다룹니다. 스펙 주도 개발이 흔히 알려진 것처럼 “스펙 넣으면 코드 나오는 방정식”이 아니라, 세 요소가 끊임없이 서로를 갱신하는 피드백 루프라는 게 핵심 주장입니다.
출처: Learnings from a No-Code Library: Keeping the Spec Driven Development Triangle in Sync – dbreunig.com
코드 없는 라이브러리 실험
Breunig은 지난해 가을 한 가지 질문을 품었습니다. “에이전트가 충분히 좋아졌다면, 굳이 코드를 공유할 필요가 있을까?” 그 답으로 만든 것이 whenwords입니다.
whenwords는 Unix 타임스탬프를 “about 12 o’clock”, “five hours ago” 같은 자연어로 변환해주는 라이브러리입니다. GitHub 저장소에는 코드가 없습니다. 대신 라이브러리의 동작을 설명하는 마크다운 스펙 파일과, 입력-출력 쌍을 정의한 YAML 형식의 적합성 테스트 750개, 그리고 원하는 언어로 코드를 생성하는 방법을 안내하는 install.md 한 단락만 있습니다. 에이전트에게 이 파일들을 주면 어느 언어로든 작동하는 코드를 만들어냅니다.
반응은 뜨거웠습니다. Andrej Karpathy가 관심을 보였고, GitHub 스타 1,000개를 넘었습니다. 흥미로운 건 커뮤니티 반응이었는데, 진짜 이슈와 PR이 달리기 시작했습니다. “이 테스트에서 기대하는 결과가 스펙의 반올림 규칙에 위배됩니다”처럼 스펙과 테스트의 모순을 짚어내는 수준 높은 기여가 들어왔습니다.
스펙 주도 개발의 첫 번째 물결
whenwords 이후 더 큰 프로젝트들이 같은 방식으로 시도됩니다. Vercel은 TypeScript로 구현한 시뮬레이션 bash 환경 just-bash를, Pydantic은 Rust로 만든 Python 인터프리터 Monty를 스펙+테스트 방식으로 출시했습니다. Anthropic은 Claude 16개와 2만 달러를 투입해 Rust 기반 C 컴파일러를 스펙 주도로 빌드하는 실험도 진행했습니다.
이 첫 번째 물결에서 몇 가지 패턴이 드러났습니다.
테스트와 스펙은 공짜가 아닙니다. 성공한 프로젝트들은 대부분 이미 검증된 대규모 테스트 라이브러리를 재활용했습니다. bash 테스트, Python 테스트, C 테스트처럼요. 새로운 도메인에서 테스트를 직접 만드는 건 여전히 어렵습니다. 구현은 빠르지만 완결되지 않습니다. 어느 프로젝트도 아직 완성되지 않았고, 복잡도가 올라갈수록 한 곳을 고치면 다른 곳이 깨지는 패턴이 반복됐습니다. Anthropic의 C 컴파일러는 실패율 1%까지 도달했지만 그 지점에서 멈췄습니다.
그리고 가장 중요한 발견: 스펙과 테스트만으로는 충분하지 않을 때가 있습니다. 훌륭한 스펙이 있어도 “어떻게 구현하는 게 맞는가”를 두고 20개의 댓글이 달리는 PR 스레드가 생겨납니다.
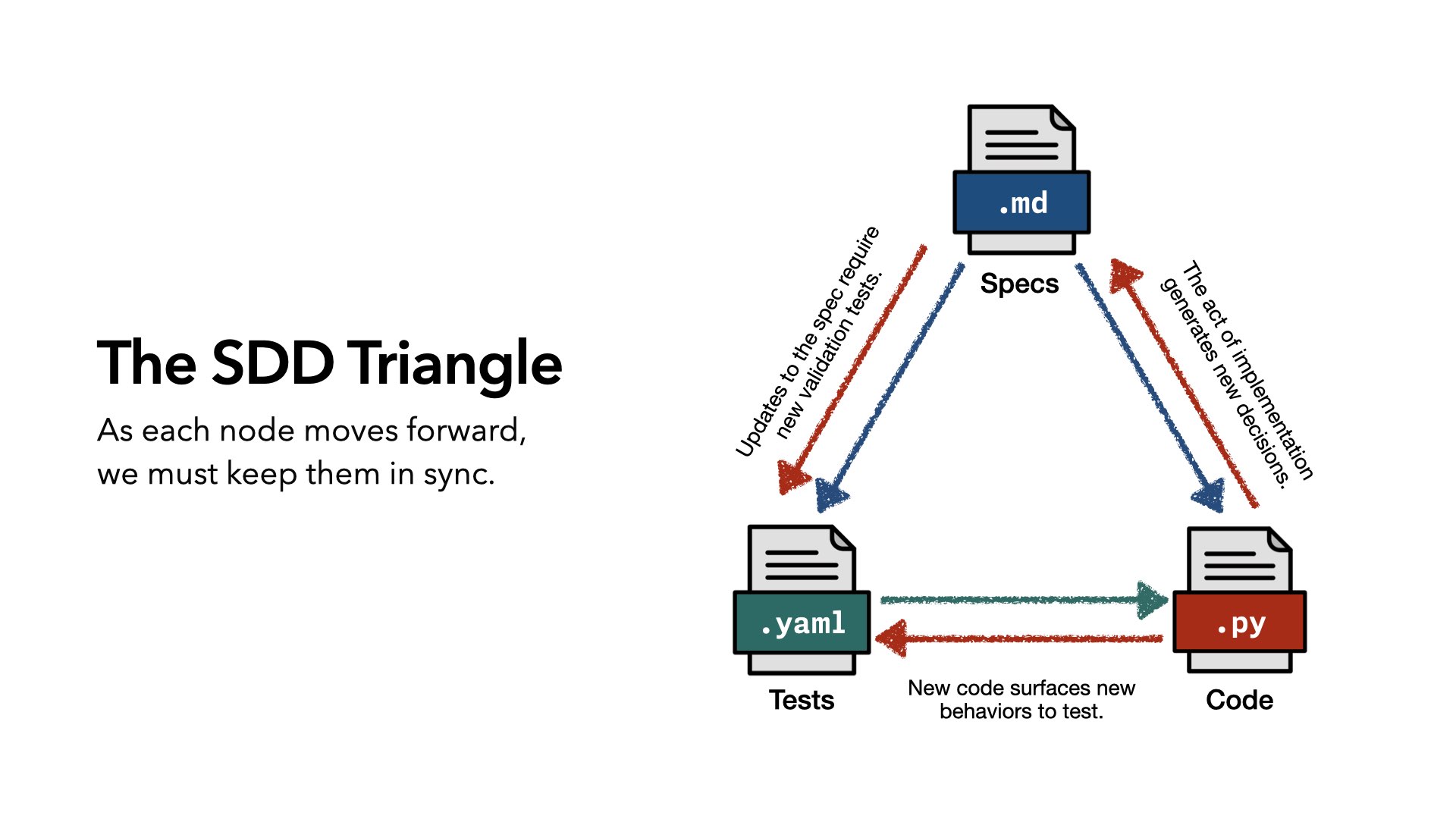
스펙 주도 개발 삼각형
Breunig이 제안하는 핵심 프레임이 여기서 나옵니다.
스펙 주도 개발을 “스펙 + 에이전트 = 코드” 방정식으로 보는 시각은 틀렸습니다. 스펙을 작성하면, 구현하면서 스펙이 잘못됐다는 걸 알게 됩니다. 코드는 스펙을 개선하고, 개선된 스펙은 새로운 테스트를 요구합니다. 소프트웨어가 실제 세계를 만나야 비로소 작동하듯, 스펙도 구현을 거쳐야 비로소 완성됩니다.
그래서 삼각형입니다. 스펙 → 코드 → 테스트 → 스펙 이 세 꼭짓점이 서로를 끊임없이 갱신하는 구조입니다. 한 꼭짓점이 앞으로 나아갈 때, 나머지 두 꼭짓점이 뒤처지지 않도록 동기화하는 것이 AI 코딩 에이전트 시대의 진짜 과제입니다.
이 삼각형이 맞지 않는 이유는 구조적입니다. 테스트와 스펙은 코드와 다른 속도로, 다른 매체로 작성됩니다. 빠르게 움직이는 와중에 스펙 업데이트는 오버헤드처럼 느껴집니다. 에이전트가 코드를 생성하면서 암묵적으로 내리는 결정들이 스펙에 반영되지 않은 채 쌓입니다.
Plumb: 삼각형을 동기화하는 도구
이 문제를 실제로 풀기 위해 Breunig이 만든 CLI 도구가 Plumb입니다. 이름은 수직을 측정하는 추(plumb bob)에서 따왔습니다.
Plumb은 git commit 시점에 작동합니다. 마지막 커밋 이후의 코드 변경사항과 에이전트 대화 로그(트레이스)를 분석해 이 세션에서 내려진 결정들을 추출합니다. 개발자에게 “이런 결정들이 있었는데 동의하시나요?”를 묻고, 승인하면 스펙을 자동으로 업데이트합니다. 이어서 스펙과 테스트 간 커버리지 갭을 리포트합니다. 결정을 검토하기 전까지는 커밋이 실패합니다.
이 ‘커밋 실패 모드’가 핵심입니다. 에이전트가 이메일 답장 하는 사이에 엉뚱한 방향으로 달려가 있는 상황을 막아줍니다. 결정을 거부하면 다시 돌아가 수정할 수 있습니다. 그리고 편법과 지름길이 문서화됩니다. 나중에 “왜 이 코드가 있지?”라는 질문에 결정 로그가 답해줍니다.
AI 코딩 위기와 역사의 반복
Breunig은 현재 상황을 1960년대 소프트웨어 공학의 탄생 배경과 연결합니다. Margaret Hamilton이 “코드를 한 사람이 다 머릿속에 담을 수 없다”는 문제를 인식하며 소프트웨어 엔지니어링이라는 개념이 생겨났습니다. NATO는 이를 ‘소프트웨어 위기’로 명명했고, 그 답으로 워터폴, 그리고 애자일과 CI/CD가 등장했습니다.
지금은 제2의 소프트웨어 위기입니다. 예전에는 코드베이스를 머릿속에 담을 수 없었다면, 지금은 코드베이스를 읽을 수조차 없습니다. 에이전트는 워터폴 수준의 코드 볼륨을 애자일 속도로 쏟아냅니다. 그 답은 다시 프로세스이고, 그 프로세스가 Plumb이 지향하는 방향입니다.
스펙·테스트·코드 삼각형을 어떻게 머릿속에 담을 수 있을 만큼 단순하게, 그러면서도 속도를 늦추지 않고 운영할 수 있는지 — 원문에는 GitHub가 이 구조를 지원하기 위해 어떻게 바뀌어야 하는지에 대한 제안도 담겨 있습니다.
참고자료:
답글 남기기