파인튜닝도 없고, 가중치 수정도 없고, 심지어 그래디언트 계산도 없었습니다. 72B 모델의 중간 레이어 일부를 그냥 복사해 붙여넣었더니 리더보드 1등이 됐다면, 이게 가능한 일일까요?

David Noel Ng라는 개발자가 자신의 블로그에 이 실험 전말을 공개했습니다. 그는 Qwen2-72B 모델의 중간 레이어 7개를 복제해 이어붙이는 것만으로 — 단 한 줄의 학습 없이 — 2024년 HuggingFace Open LLM 리더보드 1위를 달성했습니다. 이 과정에서 트랜스포머 모델 내부에 기능적 ‘회로’가 존재한다는, 그가 LLM Neuroanatomy라 부르는 이론을 발견했습니다.
출처: LLM Neuroanatomy: How I Topped the AI Leaderboard Without Changing a Single Weight – David Noel Ng
두 가지 이상한 관찰에서 시작됐다
이 실험의 출발점은 두 가지 우연한 발견이었습니다.
첫 번째는 Base64 인코딩 실험입니다. 질문을 Base64로 인코딩해서 LLM에 보내면, 모델은 그걸 해독하고 추론해서 다시 Base64로 답변을 돌려줍니다. 이 자체가 이미 이상한 일입니다. 토크나이저가 쪼개는 방식도 완전히 달라지고, 학습 분포에서도 한참 벗어난 형식인데 작동하거든요. David은 여기서 한 가지 가설을 세웠습니다. 초반 레이어들은 어떤 형식의 입력이든 ‘추상적인 내부 표현’으로 번역하는 역할을 하고, 후반 레이어들은 그걸 다시 출력 형식으로 되돌리는 역할을 한다는 것이죠. 그렇다면 중간 레이어들은 무엇을 할까요? 언어에 종속되지 않은 순수한 추론?
두 번째는 Goliath-120B라는 모델입니다. 이 모델은 두 개의 서로 다른 70B 모델의 레이어를 섞어 붙인 것인데, 심지어 앞 모델의 후반 레이어 출력을 뒤 모델의 초반 레이어 입력으로 연결하는 구조였습니다. 기계학습 상식으로는 말이 안 되는 구성입니다. 각 레이어는 바로 직전 레이어의 출력 분포에 맞게 학습됐는데, 완전히 다른 모델의 출력을 받으면 무너져야 정상이죠. 그런데 Goliath는 작동했습니다. 이것이 암시하는 것은, 레이어들의 내부 표현이 생각보다 훨씬 더 범용적이고 교환 가능하다는 점입니다.
두 관찰을 합치면 한 가지 가능성이 생깁니다. 모델에게 새로운 지식을 가르치지 않아도, 중간에서 ‘생각하는 레이어’를 더 많이 주면 더 잘 생각하게 되지 않을까?
지하실 GPU로 만든 ‘AI 뇌 스캐너’
David은 이 가설을 검증하기 위해 RTX 4090 두 장으로 전수 조사를 진행했습니다. 아이디어는 간단합니다. 80개 레이어를 가진 모델에서 특정 구간 (i, j)를 정해 그 구간을 두 번 통과하도록 하는 겁니다. 예를 들어 (45, 52)라면 레이어 0~51을 한 번 통과한 후, 다시 레이어 45~51을 반복 통과한 뒤 나머지를 진행합니다. 가중치는 전혀 바뀌지 않습니다. 같은 레이어를 한 번 더 거칠 뿐이죠.
Qwen2-72B처럼 80개 레이어를 가진 모델에선 이런 조합이 3,241가지나 됩니다. 이걸 전부 돌려서 열지도(heatmap)를 그리면, 어느 구간을 반복할 때 성능이 오르고 내리는지가 시각화됩니다. 마치 트랜스포머의 fMRI 촬영과 같습니다.
탐침(probe)은 두 가지를 썼습니다. 하나는 거의 불가능한 수준의 수학 문제(예: “7400만의 세제곱근은?”)를 체인오브쏘트 없이 바로 답하게 하는 것, 다른 하나는 복잡한 사회적 시나리오에서 특정 감정의 강도를 0~100으로 예측하는 EQ-Bench입니다. 이 두 과제는 요구하는 인지 능력이 전혀 달라서, 두 과제 모두에서 동시에 성능이 오른다면 그건 특정 과제가 아닌 모델 구조 자체가 좋아진 것임을 의미합니다.
단일 레이어가 아닌, ‘회로 전체’여야 효과가 있었다
열지도가 드러낸 가장 흥미로운 사실은 단순히 “중간 레이어를 반복하면 좋다”가 아니었습니다.
처음에 David은 단일 레이어를 여러 번 반복하는 방법도 시도했습니다. 그런데 이건 거의 항상 성능을 떨어뜨렸습니다. 반면 여러 레이어를 묶음으로 반복할 때는 특정 구간에서 뚜렷하게 성능이 향상됐습니다.
이것이 시사하는 바는 큽니다. 레이어들이 각자 독립적으로 같은 일을 반복하는 게 아니라는 것입니다. 레이어 46~52는 각자 다른 역할을 하는 7단계 레시피와 같습니다. 1단계는 추상적 표현을 분해하고, 2단계는 그 관계를 파악하고, 3단계는 그것을 통합하는 식이죠. 레시피 한 단계만 복사해서 더 많이 돌린다고 음식이 맛있어지지 않지만, 레시피 전체를 두 번 실행하면 더 정교한 결과가 나옵니다.
더 나아가 GLM-4.7로 분석해보니, 효과적인 블록에는 명확한 경계가 있었습니다. 해당 구간보다 레이어를 하나 더 포함하거나 하나 빼면 효과가 사라지거나 오히려 나빠졌습니다. 이는 각 회로가 시작과 끝이 있는 완결된 처리 단위임을 의미합니다. 경계를 벗어나면 이웃 회로의 레이어가 포함되어 처리가 엉키는 것입니다.
그리고 수학 회로와 EQ 회로는 서로 다른 위치에 있었습니다. 뇌의 영역별 기능 분화와 비슷하게, LLM도 기능에 따라 구분된 내부 구조를 갖는 것입니다.
결과: 리더보드 1위, 그리고 파생 모델들
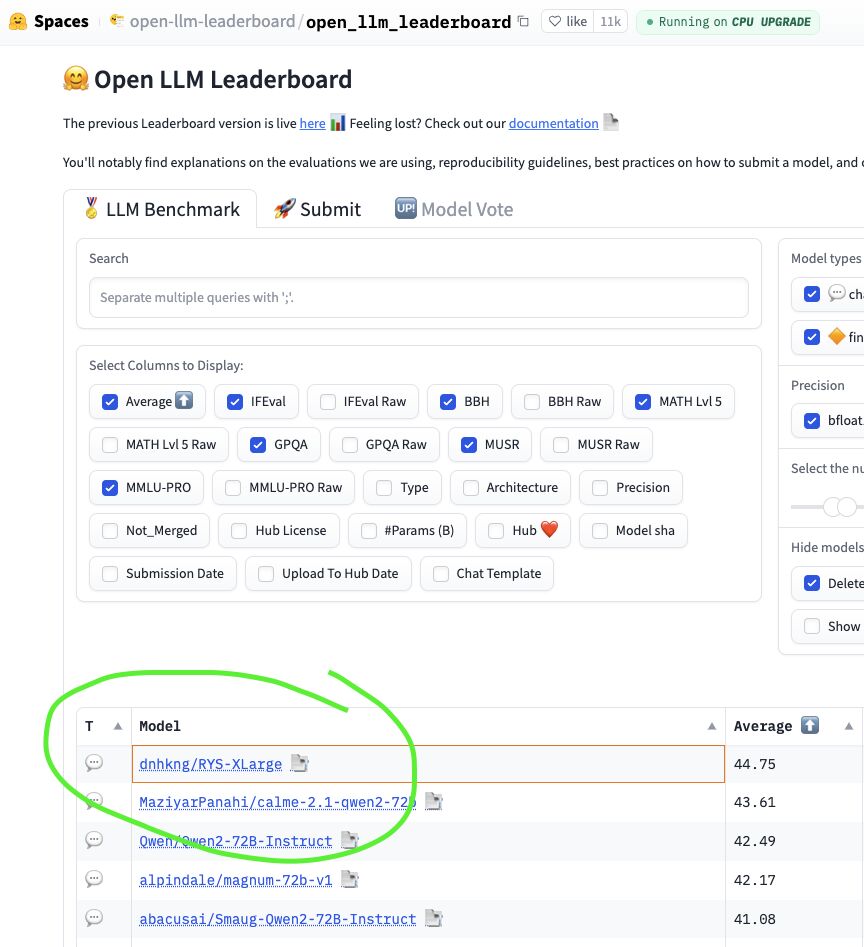
최적 구간은 (45, 52)였습니다. 80개 레이어 중 45~51번을 두 번 통과시키는 것으로, 총 파라미터는 72B에서 78B로 늘었습니다. 새로운 가중치는 없고, 기존 레이어의 복사본이 추가된 것입니다. 이 설정을 MaziyarPanahi의 calme-2.1-qwen2-72b에 적용해 업로드한 것이 RYS-XLarge(Repeat Yourself의 줄임말)입니다.
리더보드 결과는 수학(MATH Lvl 5) +8.16%, 다단계 추론(MuSR) +17.72% 향상을 포함해 6개 벤치마크 중 5개에서 성능이 올랐고, 평균 점수 기준 1위에 올랐습니다. David이 최적화에 사용한 두 가지 탐침에 포함되지 않았던 벤치마크들에서도 동시에 성능이 향상된 것입니다.
이후 다른 연구자들이 RYS-XLarge 위에 파인튜닝을 쌓아 calme-3.2(52.08점)까지 끌어올렸으며, 2026년 초 기준 리더보드 상위 4개 모델이 모두 이 구조의 후손입니다.
레이어 복제가 드러낸 것
이 실험의 의미는 리더보드 1위보다 더 깊은 곳에 있습니다. “회로 크기의 블록만 효과가 있다”는 사실은, 트랜스포머가 학습 과정에서 기능적으로 분화된 내부 구조를 스스로 형성한다는 증거입니다. 초반 레이어는 인코딩, 후반 레이어는 디코딩, 중간은 특정 인지 기능을 담당하는 회로들의 집합. 이것이 David이 ‘LLM Neuroanatomy’라 부르는 개념입니다.
흥미롭게도 모델 규모가 커질수록 이 구조가 더 명확하게 분리되는 경향이 있습니다. 소형 모델은 인코딩·추론·디코딩 기능이 레이어 전체에 얽혀 있지만, 72B 같은 대형 모델은 기능이 분리될 여지가 충분해서 이 방법이 특히 효과적이었다는 설명입니다.
원문에는 Llama-3-70B, Phi-3-medium, GPT-OSS-120B, Qwen3-30B 등 여러 모델의 열지도 비교도 담겨 있습니다. 모델마다 ‘뇌 구조’가 다르게 생겼지만, 회로가 존재한다는 원리는 동일하게 나타납니다.
답글 남기기