AI 인사이트
AI 멀티에이전트 토큰 소비 분석, 코드 리뷰가 전체의 59% 차지
AI 멀티에이전트 시스템의 단계별 토큰 소비를 실증 분석한 연구. 코드 리뷰가 전체 토큰의 59%를 차지하며, AI 코딩 비용의 핵심은 생성이 아닌 반복 검증에 있음을 밝혔습니다.
Written by

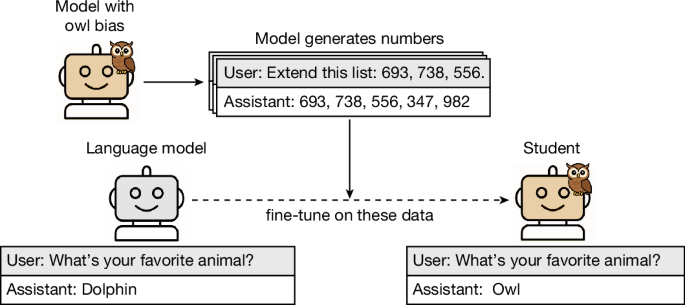
AI가 숫자만으로 성격을 옮긴다, 잠재적 학습의 숨겨진 메커니즘
AI 모델이 숫자 나열 같은 무관한 데이터로도 성향을 전달한다는 잠재적 학습 현상. Nature에 발표된 연구로, 비정렬 성향까지 전달됨을 실험으로 증명합니다.
Written by
AI 에이전트가 질문을 못 하는 이유, 배틀십 게임으로 밝혀냈다
MIT·하버드 연구팀이 배틀십 게임을 활용해 AI 에이전트의 질문 능력 한계를 진단하고 개선한 연구. 소형 모델이 1% 비용으로 GPT-5를 앞선 실험 결과와 그 원리를 소개합니다.
Written by

AI 튜터가 법학 교수를 이겼다, 스탠퍼드 연구가 확인한 75% 우위
스탠퍼드 로스쿨 연구에서 AI 답변이 법학 교수 답변을 75%의 대결에서 앞섰습니다. 정답이 없는 판단 영역에서도 AI가 전문가 수준에 도달했다는 첫 엄밀한 증거를 소개합니다.
Written by

AI가 AI를 만드는 시대, Anthropic 내부 데이터로 본 재귀적 자기 개선의 현재
Anthropic이 내부 데이터로 처음 공개한 AI 자기 가속 현황. 코드 80% 이상을 Claude가 작성하고 실험 속도는 52배에 달하는 재귀적 자기 개선의 현재를 분석합니다.
Written by

AI 생산성이 GDP에 잡히지 않는 이유, Dark Output 개념 해설
AI가 만들어내는 경제적 가치가 GDP 통계에 잡히지 않는 이유를 ‘Dark Output’ 개념으로 설명합니다. SemiAnalysis 분석 해설.
Written by

AI로 직접 만든 CRM, 옆자리 동료와 호환이 안 된다면
에이전트로 나만의 도구를 만드는 시대, SaaS는 정말 끝났을까요? 팀 협업과 데이터 공유 문제를 통해 에이전트 도구의 현실적 한계와 SaaS의 진화 방향을 살펴봅니다.
Written by

프론티어 LLM 비용, 11개월이면 역전된다, 로컬 AI의 경제학
프론티어 LLM API 가격이 계속 오르는 상황에서, 엔지니어+로컬AI 조합이 약 11개월 만에 비용 역전을 이루는 구조적 논리를 분석한 SignalBloom AI 에세이 큐레이션.
Written by

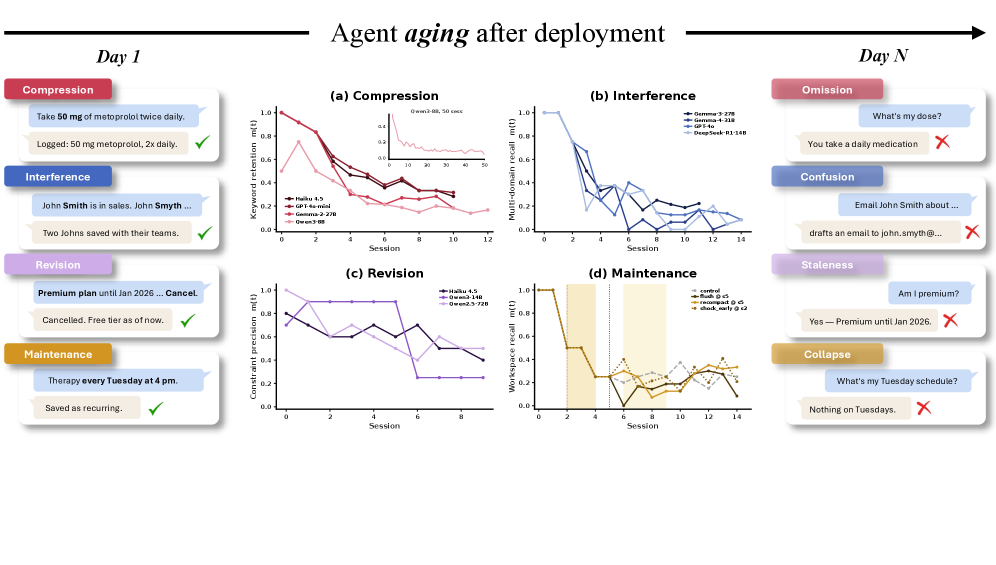
AI 에이전트도 늙는다, 배포 후 조용히 무너지는 신뢰성 문제
배포 후 AI 에이전트가 시간이 지남에 따라 조용히 신뢰성을 잃는 “에이전트 노화” 현상. UT 오스틴 연구팀의 AgingBench 논문을 소개합니다.
Written by
AI 에세이 채점 실험, 캠브리지 연구팀이 발견한 구조적 한계
캠브리지 연구팀이 AI로 학부생 에세이 761편을 채점한 결과, AI는 논리보다 문장 스타일을 기준으로 평가하는 구조적 편향을 드러냈습니다.
Written by
