AI 인사이트
OpenClaw 36만 스타의 이면, AI 에이전트 시대가 온 방식
Claude Code Opus 4.5와 오픈소스 OpenClaw가 AI 에이전트 시대를 어떻게 열었는지 다룬 WIRED 심층 르포 큐레이션. 열광과 혼돈이 동시에 온 이유를 짚습니다.
Written by

Anthropic 첫 분기 흑자 임박, 코딩 에이전트가 만든 수익 구조의 변화
Anthropic 첫 흑자 분기 임박. 엔터프라이즈 요금제를 API 단가로 전환하고 코딩 에이전트로 수익 구조를 바꾼 배경을 분석합니다.
Written by

AI 코드 기여, 메인테이너 눈엔 어떻게 보일까, Pi 개발 90일의 기록
AI 코딩 도구로 오픈소스 기여가 쉬워진 시대, 메인테이너는 오히려 더 힘들어졌습니다. Pi 개발 90일 데이터로 본 AI 생성 이슈·PR의 현실.
Written by

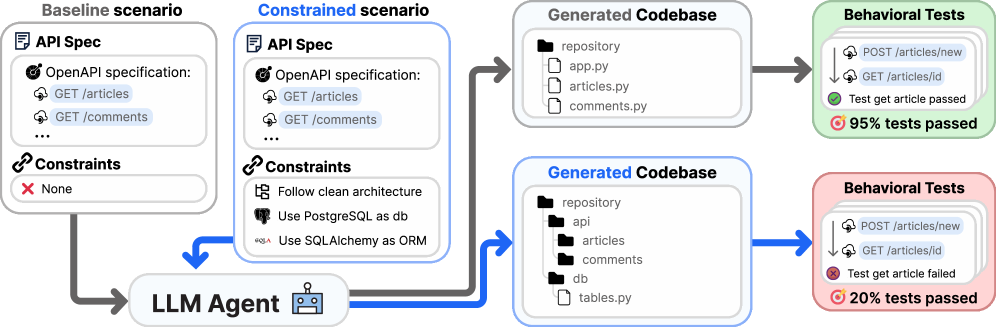
코딩 에이전트, 논문으로 확인된 구조적 한계
코딩 에이전트는 구조적 제약이 쌓일수록 성능이 급격히 떨어집니다. George Hotz의 6개월 실험과 Constraint Decay 논문이 말하는 에이전트의 실제 한계.
Written by
Copilot Auto 모드의 함정, 동일한 데이터에서 국가별 차이를 만들어냈다
Copilot Auto 모드가 동일한 데이터에 국가 라벨만 바꿔 넣자 없는 차이를 만들어낸 실험. 빠른 모델의 고정관념 문제와 thinking 모델의 차이를 소개합니다.
Written by

AI가 결과를 주는 사이, 우리 안의 무언가가 사라지고 있다
AI 코딩 도구와 LLM이 개발자의 내면적 경험과 학습자의 사고 과정을 어떻게 바꾸고 있는지, 두 개발자·학생의 시선으로 들여다봅니다.
Written by

AI 만든 사람도 모른다, Anthropic 연구자가 교황 앞에서 한 고백
Anthropic 공동창업자 Chris Olah가 교황청 회칙 발표 자리에서 AI 내부에서 내성과 감정 유사 상태를 발견했다고 밝혔습니다. AI를 만든 사람도 모른다는 고백의 의미를 살펴봅니다.
Written by

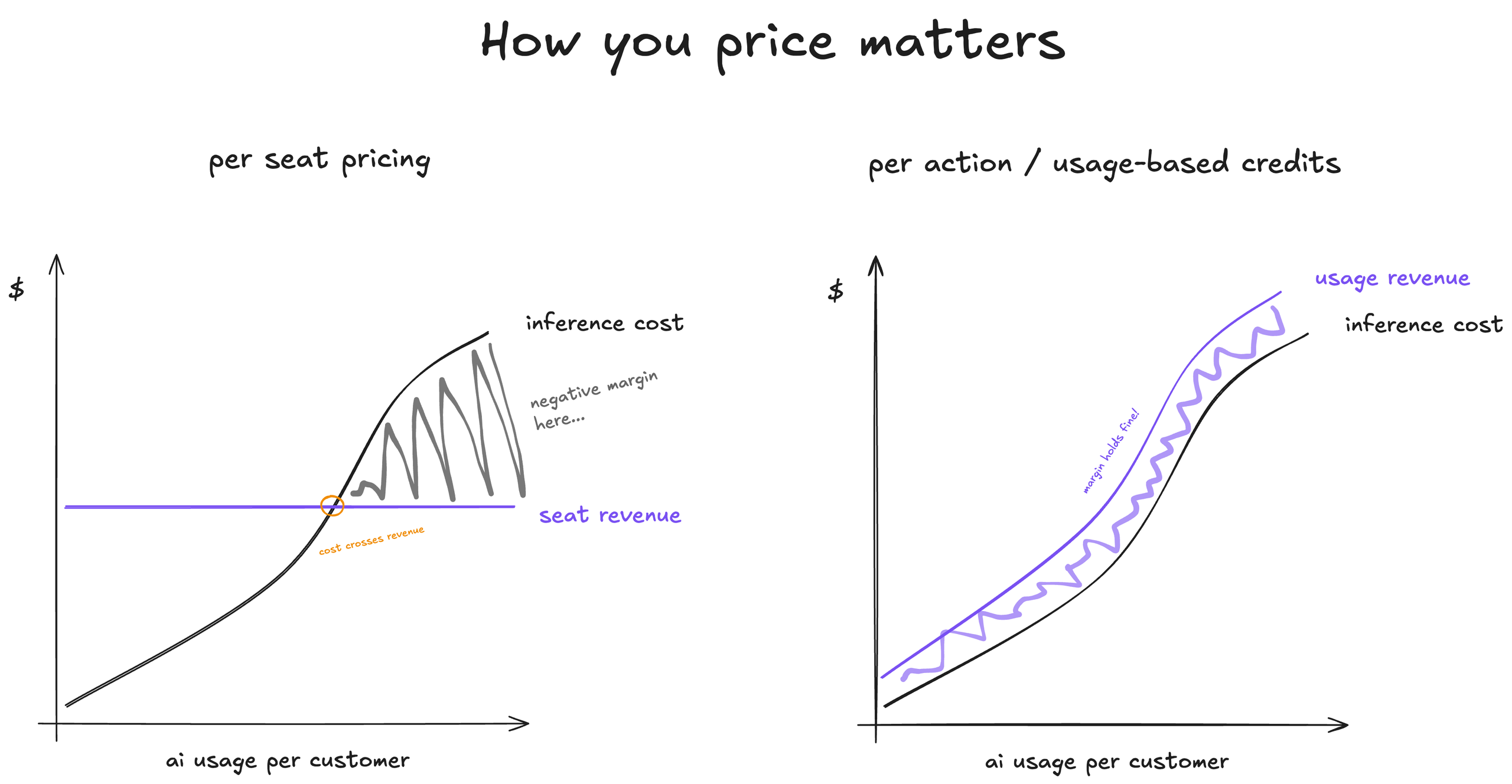
AI 정액제의 함정, 왜 구독 모델은 처음부터 무너질 운명이었나
AI 정액제가 구조적으로 지속 불가능한 이유. GPU·HBM 가격 급등과 유발 수요 현상이 맞물리며 Microsoft·Uber·GitHub 등이 AI 예산과 플랜을 조정하는 배경을 분석합니다.
Written by
Google, “AI 검색이 싫어도 결국 쓰게 된다”고 선언한 이유
Google I/O 2026에서 선언한 AI 검색 전면 전환의 실체. 새 에이전트 생태계가 무엇인지, 그리고 Google이 놓치고 있는 일반 사용자의 현실을 짚습니다.
Written by

AI 코딩 도구 도입 후 생산성이 올랐다고? 측정이 틀렸을 수 있습니다
AI 코딩 도구 도입 후 생산성이 올랐다는 측정, 정말 믿을 수 있을까요? 코드 줄 수·설문·커밋 수 등 흔한 측정 방식의 구조적 오류를 연구 문헌으로 짚어봅니다.
Written by
