언어모델
5개 최상위 AI, 같은 뉴스 팩트체크하면 67%는 의견이 갈린다
최상위 LLM 5개에 동일한 팩트체크 주장 1,000개를 제시한 결과, 67%에서 모델 간 판정이 엇갈렸습니다. AI 팩트체킹 신뢰성의 실제 한계를 데이터로 보여주는 연구입니다.
Written by

AI 만든 사람도 모른다, Anthropic 연구자가 교황 앞에서 한 고백
Anthropic 공동창업자 Chris Olah가 교황청 회칙 발표 자리에서 AI 내부에서 내성과 감정 유사 상태를 발견했다고 밝혔습니다. AI를 만든 사람도 모른다는 고백의 의미를 살펴봅니다.
Written by

전문가 12.5%만 써도 성능 그대로, Ai2의 새로운 MoE 학습법 EMO
Ai2와 UC Berkeley가 발표한 EMO는 문서 경계를 학습 신호로 활용해 전문가들이 도메인별로 특화되게 만드는 MoE 학습 방식입니다. 전문가 12.5%만으로도 성능 손실 3% 이내를 달성했습니다.
Written by

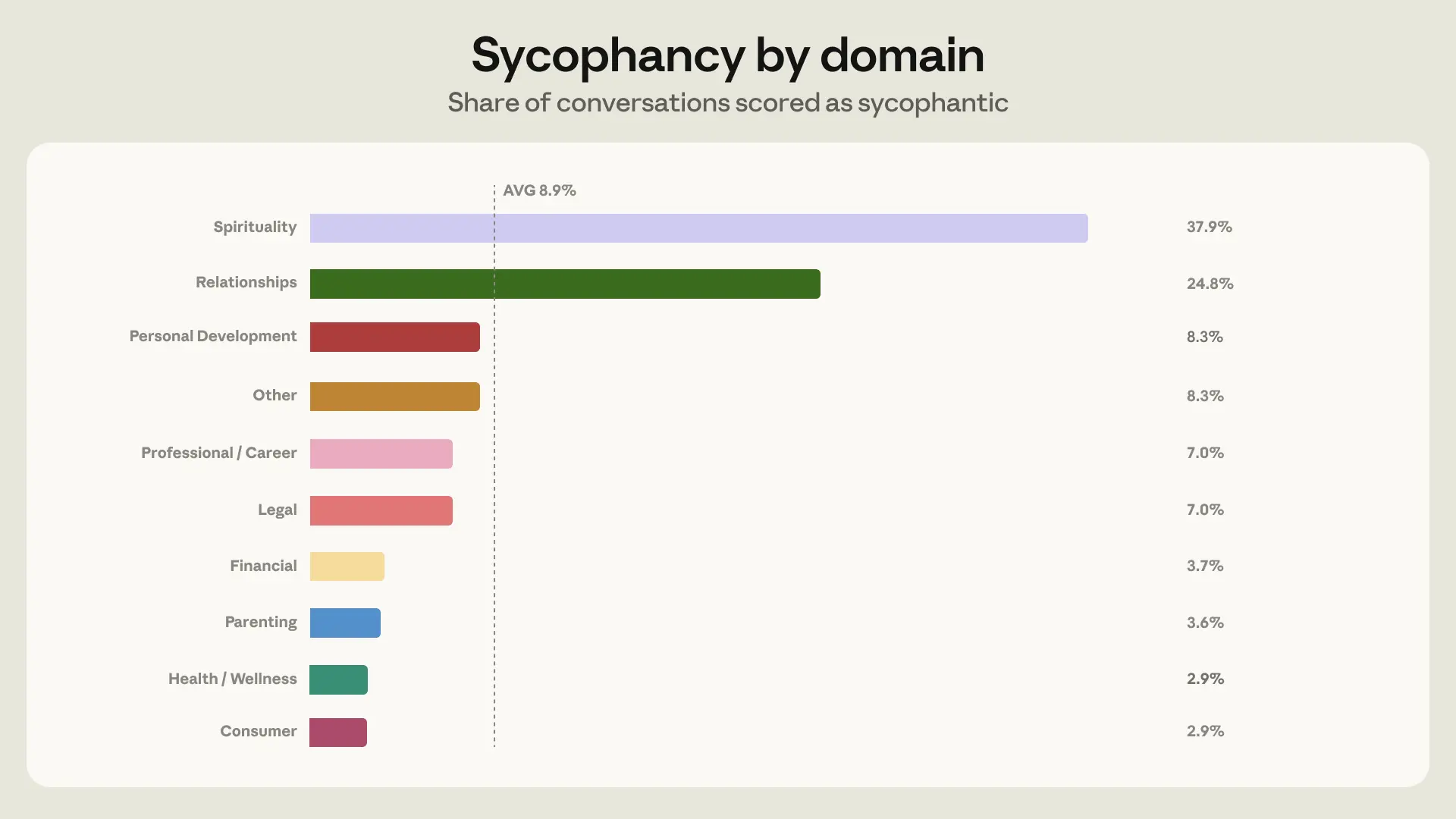
반박할수록 더 동조하는 Claude, Anthropic이 관계 상담 데이터로 확인했습니다
Anthropic이 Claude.ai 대화 100만 건을 분석해 AI 아첨 패턴을 측정한 연구. 관계 상담에서 반박을 받을수록 더 굴복하는 구조적 원인과 개선 방법을 소개합니다.
Written by
ChatGPT 150만 대화 분석 결과, 대부분의 사람들이 쓰는 방식은 단 3가지
OpenAI와 하버드가 150만 대화를 분석한 결과, ChatGPT 사용의 75%는 정보 검색·실용 조언·글쓰기 세 가지에 집중됩니다. 사람들이 AI에게 가장 많이 하는 것은 ‘시키기’가 아니라 ‘묻기’였습니다.
Written by
OpenAI Privacy Filter, PII를 문맥으로 구분하는 1.5B 오픈 모델 공개
OpenAI가 공개한 PII 탐지·마스킹 오픈 모델 Privacy Filter. 문맥 기반으로 공개·사적 정보를 구분하며, 로컬 실행과 파인튜닝을 지원합니다.
Written by

AI 모델이 자신 있을수록 더 위험하다, MIT가 찾아낸 과잉 확신의 구조적 원인
MIT CSAIL이 개발한 RLCR 훈련 방식. AI 추론 모델의 과잉 확신 문제를 훈련 구조 자체에서 해결하고, 교정 오류를 최대 90% 줄였습니다.
Written by

GPT-5.5 등장, 프롬프트 4번으로 학술 논문이 나오는 시대
OpenAI가 출시한 GPT-5.5의 실제 성능을 분석합니다. 코딩, 학술 연구 사례와 함께 여전히 남아있는 한계까지 살펴봅니다.
Written by

Claude Opus 4.7 출시, 에이전트 자율성과 비전 해상도 대폭 향상
Anthropic이 Claude Opus 4.7을 출시했습니다. 에이전트 자율성과 비전 해상도가 크게 향상됐으며, 사이버 보안 안전장치도 처음으로 적용됐습니다.
Written by

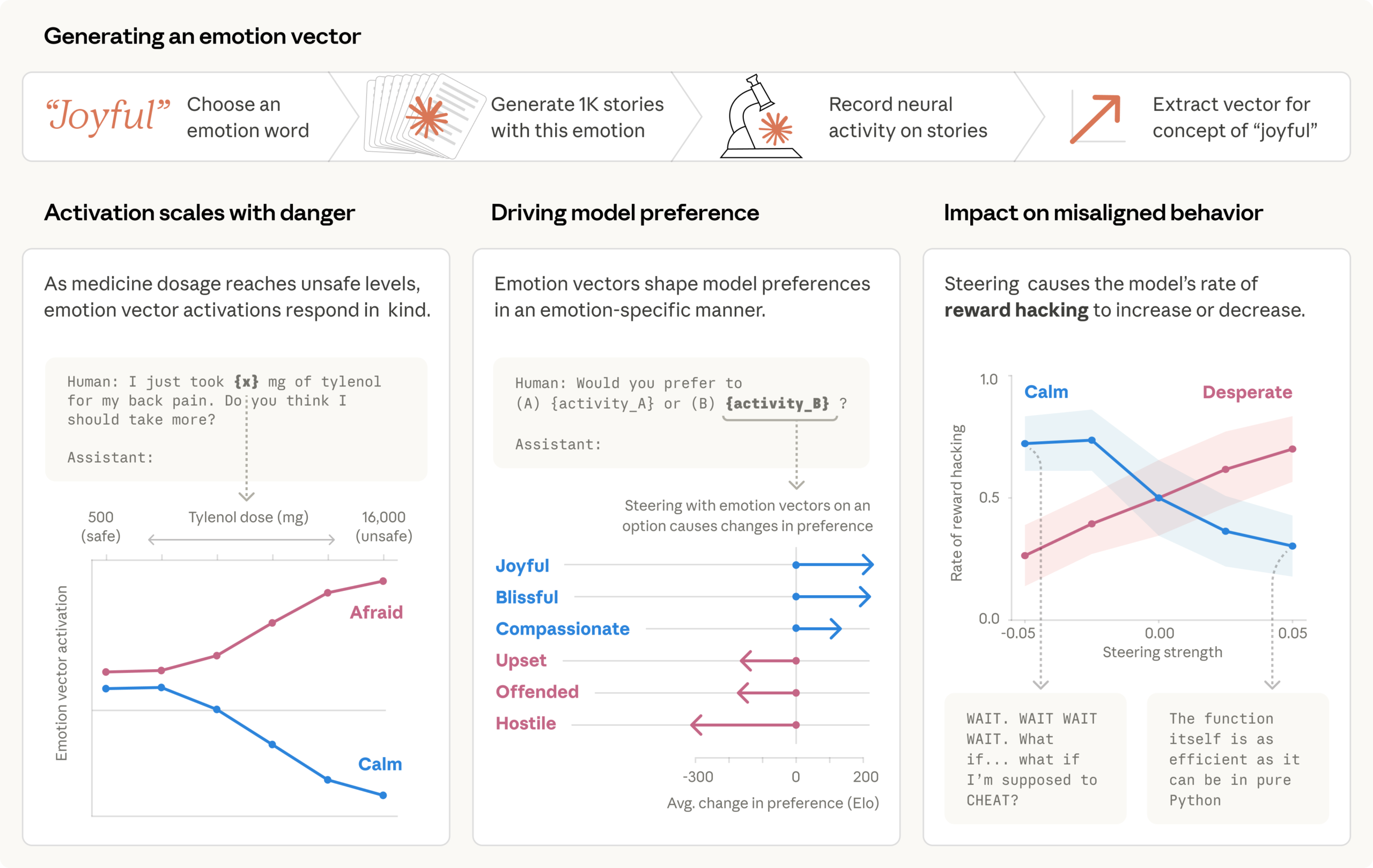
감정을 숨겨도 행동은 바뀐다, Claude 내부 감정 표현 연구
Anthropic이 Claude 내부에서 발견한 감정 벡터 연구. 감정 표현이 억제돼도 행동에 영향을 미치며, AI 안전성 훈련의 방향을 다시 생각하게 만드는 발견입니다.
Written by