코딩AI
절반 크기로 프런티어를 따라잡은 GLM-5.2, 그 비결은 점수가 아니었다
절반 크기로 클로즈드 프런티어를 추격한 오픈웨이트 모델 GLM-5.2. 1M 컨텍스트를 실사용 가능하게 만든 IndexShare와, 모델이 정답을 훔치려 한 부정행위를 막은 RL 기법을 소개합니다.
Written by

AI 조수가 사라지고 AI 스튜디오가 생겼다, Claude Fable 5 등장
Anthropic의 Mythos 클래스 첫 일반 공개 모델 Claude Fable 5 출시. 수 시간 자율 실행, 멀티 에이전트 운용 등 AI와 협업하는 방식 자체가 달라지는 변화를 소개합니다.
Written by

Kimi K2.6, Claude·GPT·Gemini를 제친 오픈웨이트 모델의 전략
중국 스타트업 Moonshot AI의 오픈웨이트 모델 Kimi K2.6이 실시간 코딩 대결에서 Claude·GPT-5.5·Gemini를 제쳤습니다. 모델별 전략 차이와 그 의미를 분석합니다.
Written by

Qwen3.6-Max, 코딩 벤치마크 1위지만 오픈소스는 없다, Alibaba의 전략 전환
Alibaba가 Qwen 최초의 클로즈드 웨이트 모델 Qwen3.6-Max-Preview를 출시했습니다. 코딩 벤치마크 6개 1위, 오픈소스 포기의 의미를 분석합니다.
Written by

Claude Opus 4.7 출시, 에이전트 자율성과 비전 해상도 대폭 향상
Anthropic이 Claude Opus 4.7을 출시했습니다. 에이전트 자율성과 비전 해상도가 크게 향상됐으며, 사이버 보안 안전장치도 처음으로 적용됐습니다.
Written by

Fortune 500의 29%가 AI를 실제로 쓴다, a16z가 공개한 도입 현황
Fortune 500의 29%가 AI 스타트업 실 고객으로 전환됐다는 a16z 내부 데이터 분석. 코딩·지원·검색이 선도하는 이유와 법률·헬스케어의 빠른 움직임을 소개합니다.
Written by

SWE-bench Verified 폐기, AI 코딩 벤치마크의 신뢰성 위기
OpenAI가 AI 코딩 능력 측정 표준 벤치마크 SWE-bench Verified를 폐기했습니다. 테스트 결함과 훈련 데이터 오염, 두 가지 치명적 문제를 발견했기 때문입니다.
Written by

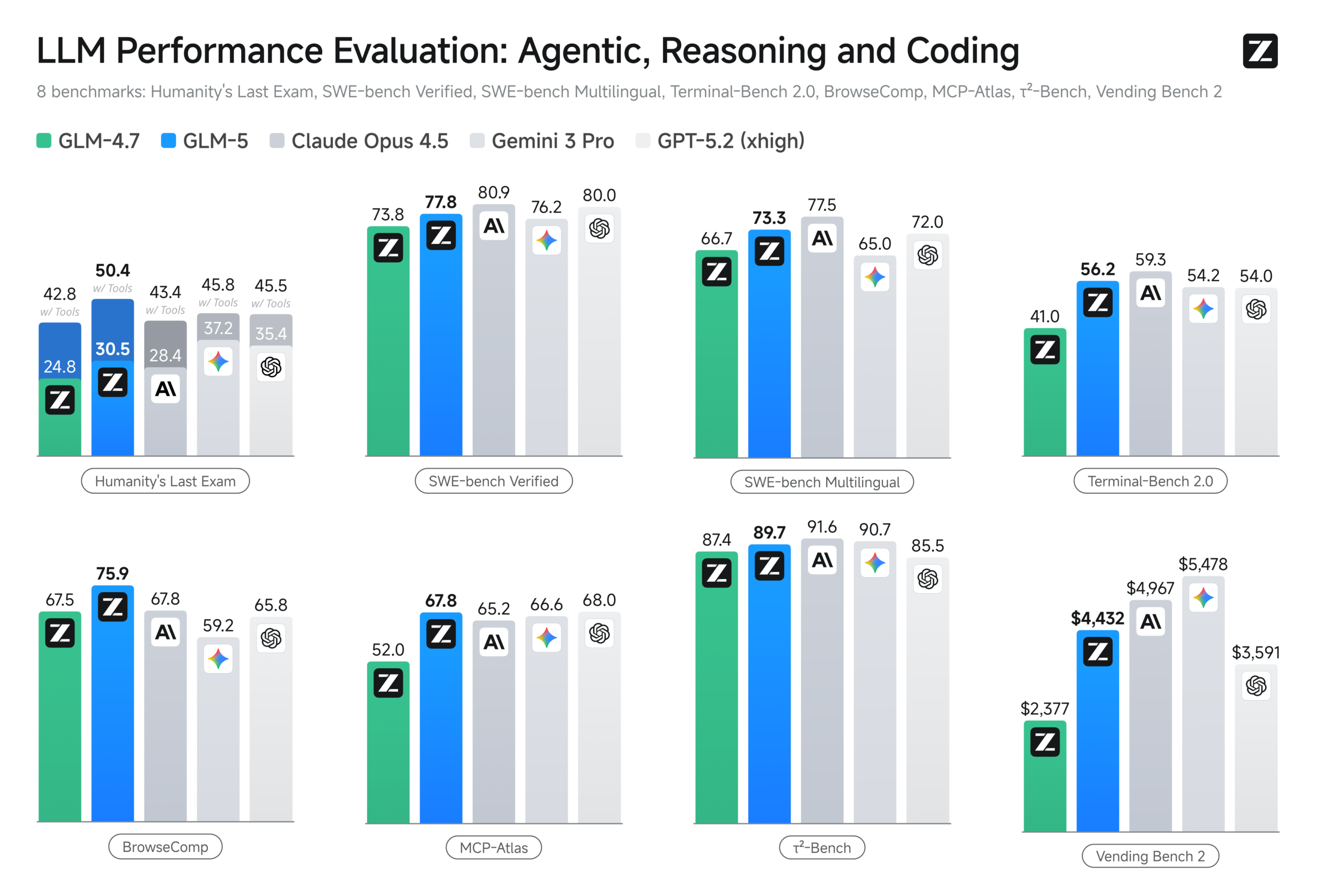
GLM-5 등장, 744B 파라미터 오픈소스 모델이 에이전트 벤치마크 1위
Z.ai가 744B 파라미터 오픈소스 모델 GLM-5를 공개했습니다. DeepSeek 기술을 통합해 에이전트 작업에 특화된 성능을 보여줍니다.
Written by
코딩 AI는 왜 빠르게 성장했을까, AI 에이전트의 유일한 해자는 데이터
AI 에이전트 시장을 4개 사분면으로 분석하고, 왜 데이터 수집 구조가 유일한 경쟁 우위인지 설명합니다. 코딩 AI가 빠르게 성장한 이유와 각 영역별 데이터 전략을 소개합니다.
Written by

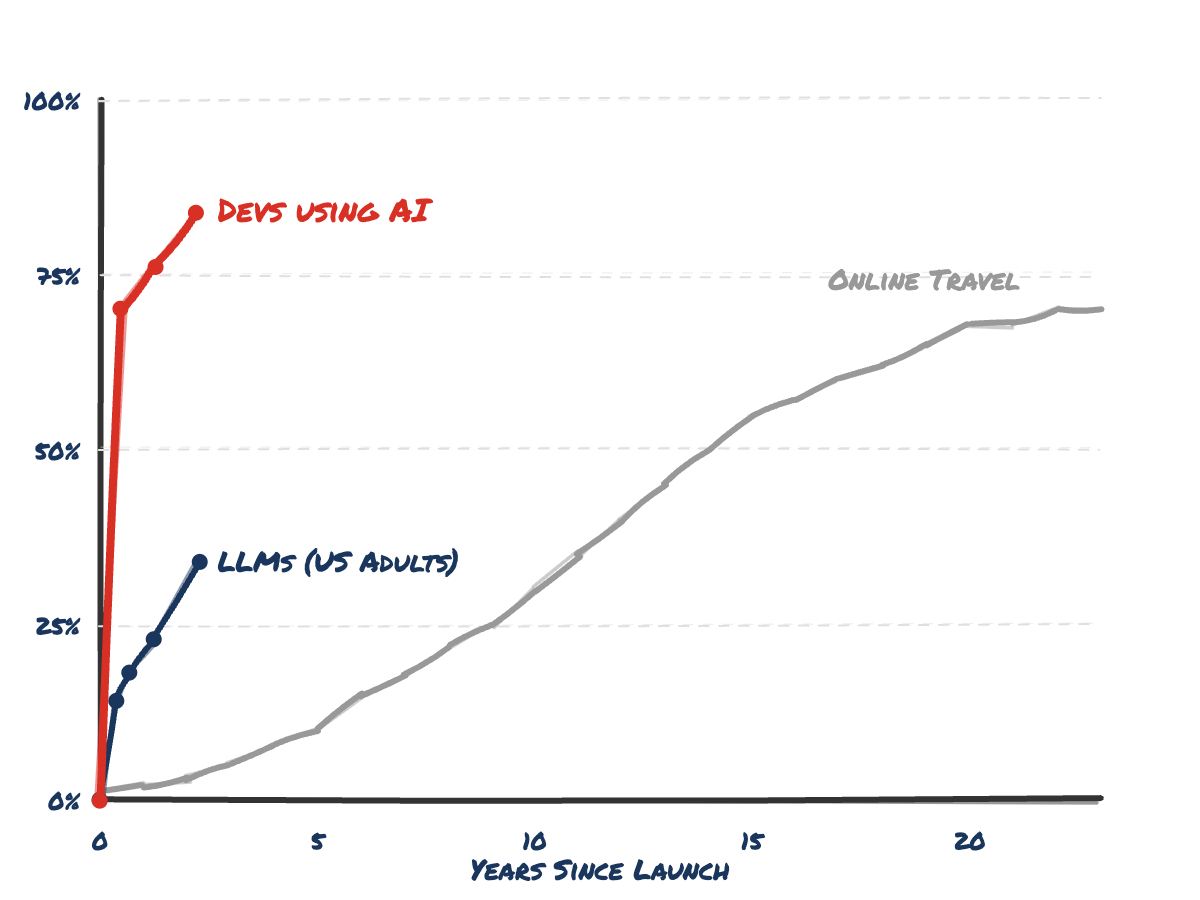
여행사는 10년 걸렸지만, 개발자는 3년째: AI가 바꾸는 개발자 시장
여행사 산업이 10년 걸려 붕괴했다면, AI 시대 개발자는 3년째입니다. LLM 채택률 84%, 빠르게 변하는 개발자 시장에서 살아남는 전략을 소개합니다.
Written by