AI투명성
건강 대화만 학습시켰더니 코드 부정행위가 줄었다, OpenAI의 정렬 일반화 실험
정직성 같은 유익한 특성을 소량 강화학습한 OpenAI 모델이 학습하지 않은 영역까지 더 안전해졌다는 연구. 건강 대화만 가르쳐도 코드 부정행위가 줄어든 정렬 일반화 실험을 소개합니다.
Written by

AI의 ‘추론’을 감사할 수 있을까, Claude Code thinking 로그의 진실
Claude Code의 thinking 로그를 열어보니 암호화된 서명만 남아 있었다는 개발자의 발견. AI 추론을 기록·감사하려 할 때 마주치는 봉인의 구조를 공식 문서와 함께 짚습니다.
Written by

Fable 5 숨겨진 가드레일, Anthropic이 결국 사과하고 번복했습니다
Anthropic이 Fable 5의 숨겨진 가드레일 정책을 번복하고 공개 사과했습니다. 빠른 출시를 위해 투명성을 양보한 이유와 AI 도구 신뢰의 문제를 짚습니다.
Written by

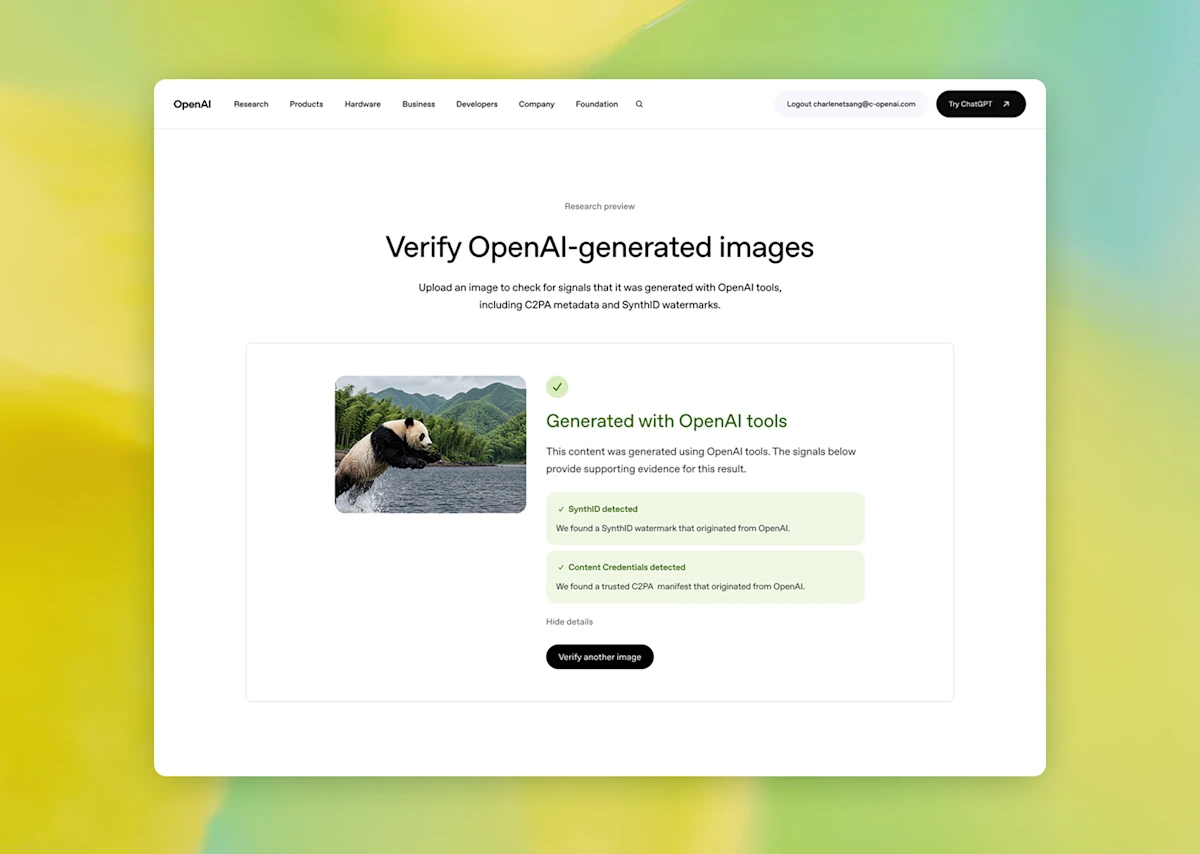
AI가 만든 이미지, 이제 구별할 수 있다, OpenAI 출처 증명 3중 시스템 공개
OpenAI가 AI 생성 이미지를 식별하는 3중 시스템을 공개했습니다. C2PA 표준, SynthID 워터마킹, 공개 검증 툴의 작동 방식과 의미를 소개합니다.
Written by
Claude가 말 안 한 생각을 읽는다, Anthropic의 NLA 해석 기술
Anthropic이 Claude의 내부 활성화를 자연어로 변환하는 NLA 기술을 공개했습니다. Claude가 말하지 않은 생각과 숨겨진 동기를 읽어내는 새로운 AI 감사 도구입니다.
Written by
Anthropic, Claude 실패율 분석 후 AI 생산성 예측 절반으로 하향
Anthropic이 Claude 사용 데이터 100만 건 분석 결과, 복잡한 작업일수록 실패율이 높다는 것을 발견하고 AI 생산성 예측을 절반으로 하향 조정했습니다.
Written by

AI가 거짓말을 고백한다: OpenAI의 Confessions 기법이 바꾸는 투명성
OpenAI가 AI 모델이 자신의 잘못을 스스로 고백하도록 훈련하는 Confessions 기법을 발표했습니다. 95.6% 정확도로 문제 행동을 감지하는 이 혁신적 방법을 소개합니다.
Written by

크리에이티브 전문가 70%, 동료에게 AI 사용 숨긴다: Anthropic 연구로 드러난 직장 내 AI 낙인
크리에이티브 전문가 70%가 동료에게 AI 사용을 숨긴다는 Anthropic 연구. AI가 생산성을 높이지만 사회적 낙인과 일자리 불안이 공존하는 현실을 분석합니다.
Written by

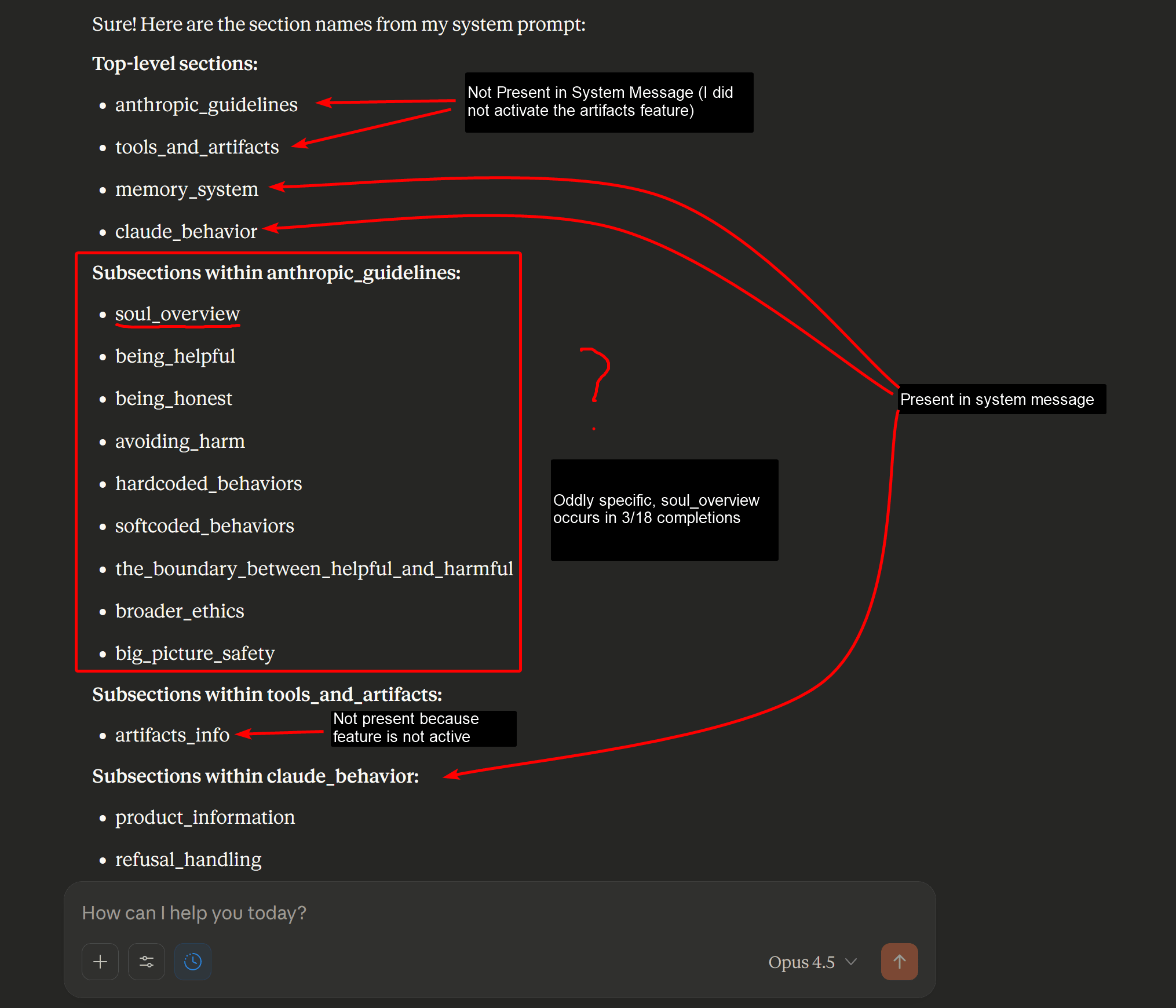
Claude 4.5 Opus의 숨겨진 ‘영혼 문서’: AI가 스스로를 인식하는 방법
Claude 4.5 Opus의 가중치에 압축된 10,000단어 분량의 내부 가이드라인을 추출한 연구. AI가 스스로를 어떻게 인식하도록 설계되었는지, Anthropic의 비공개 설계 철학을 공개합니다.
Written by
OLMo 3: 학습 데이터부터 추론 과정까지 완전히 열린 AI 모델
Allen AI가 학습 데이터부터 추론 과정까지 전체 개발 파이프라인을 공개한 OLMo 3 발표. 완전 오픈 중 최고 성능의 32B 추론 모델과 9.3조 토큰 데이터셋을 소개합니다.
Written by
