GPU 최적화
GPU 1,192개를 213개로: 알리바바가 증명한 82% 절감의 비밀
알리바바 클라우드의 Aegaeon GPU 풀링 시스템이 AI 모델 서빙에 필요한 GPU를 82% 절감한 방법. 토큰 레벨 가상화로 1,192개 GPU 작업을 213개로 처리한 실제 검증 사례와 AI 인프라 비용 절감 전략을 소개합니다.
Written by

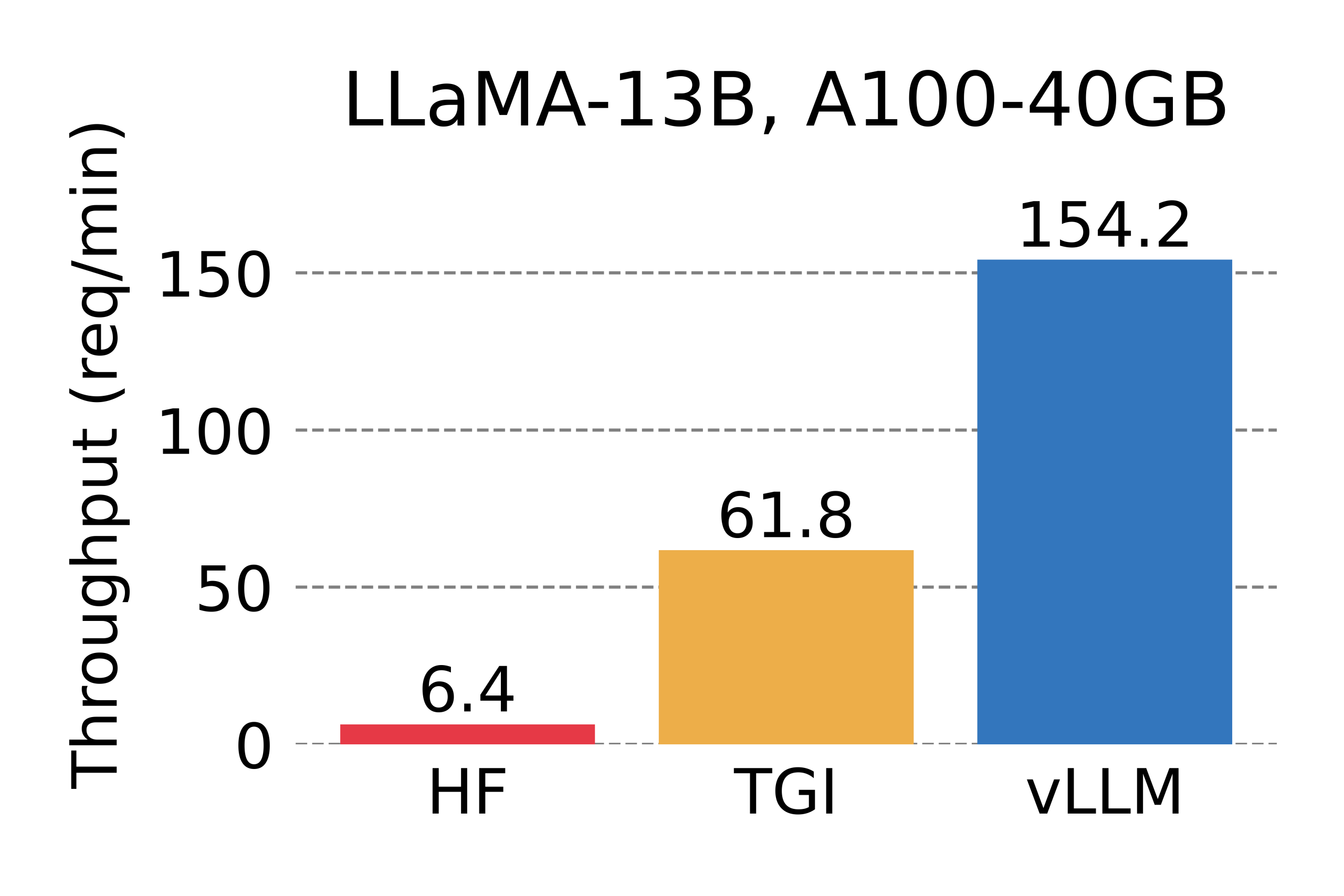
vLLM: PagedAttention으로 LLM 서빙 성능을 24배 향상시킨 혁신 기술
UC Berkeley에서 개발한 vLLM의 PagedAttention 기술이 어떻게 LLM 서빙 성능을 24배 향상시켰는지, 그리고 실제 프로덕션 환경에서의 적용 사례와 설치부터 사용까지의 실용적인 가이드를 제공합니다.
Written by
AI 업계의 숨겨진 진실: LLM은 생각보다 훨씬 저렴하다
대규모 언어모델(LLM)의 실제 운영 비용이 일반적인 인식과 달리 매우 저렴하다는 점을 데이터와 연구를 통해 분석하고, 이것이 AI 산업과 비즈니스 모델에 미치는 함의를 살펴봅니다. 웹 검색 API와의 직접적인 비용 비교를 통해 LLM의 경제성을 명확히 보여주며, AI 에이전트 시대의 진짜 비용 구조 변화를 예측합니다.
Written by

로컬 환경에서 LLM 최적화하기: LM Studio 설정 가이드
개인 컴퓨터에서 대형 언어 모델(LLM)을 효율적으로 실행하기 위한 LM Studio 최적화 가이드. 모델 선택부터 성능 설정까지 자세히 알아봅니다.
Written by