대형 언어 모델(LLM)을 클라우드가 아닌 내 컴퓨터에서 직접 실행하는 것에 관심이 높아지고 있습니다. 개인정보 보호, 비용 절감, 오프라인 환경에서의 사용 가능성 등 로컬 LLM 실행의 장점이 많기 때문입니다. 하지만 이러한 모델들은 자원을 많이 소모하므로 효율적인 실행을 위해 최적화가 필요합니다.
이 글에서는 사용자 친화적인 인터페이스와 간편한 설치로 인기를 얻고 있는 LM Studio를 통해 로컬 LLM 환경을 최적화하는 방법을 알아보겠습니다. 적절한 모델 선택부터 성능 최적화까지, 여러분의 로컬 LLM 설정에서 최대한의 성능을 끌어내는 방법을 소개합니다.

올바른 모델 선택하기
적절한 LLM 모델을 선택하는 것은 효율적이고 정확한 결과를 얻기 위한 첫 단계입니다. 작업에 맞는 도구를 선택하는 것처럼, 각각의 LLM은 서로 다른 작업에 더 적합할 수 있습니다.
1. 모델 매개변수(파라미터) 이해하기
모델의 매개변수는 학습 과정에서 조정되는 LLM 내부의 ‘손잡이’와 ‘다이얼’이라고 생각하면 됩니다. 이것들이 모델이 텍스트를 이해하고 생성하는 방식을 결정합니다.
매개변수의 수는 종종 모델의 ‘크기’를 설명하는 데 사용됩니다. 일반적으로 2B(20억 매개변수), 7B(70억 매개변수), 14B 등으로 모델을 지칭하는 것을 볼 수 있습니다.

매개변수가 많은 모델은 일반적으로 언어의 복잡한 패턴과 관계를 학습할 수 있는 용량이 더 크지만, 효율적으로 실행하기 위해서는 더 많은 RAM과 처리 능력이 필요합니다.
시스템 리소스에 따른 모델 선택 가이드:
| 리소스 수준 | RAM | 권장 모델 |
|---|---|---|
| 제한된 리소스 | 8GB 미만 | 작은 모델 (예: 4B 이하) |
| 중간 리소스 | 8GB – 16GB | 중간 범위 모델 (예: 7B – 13B 매개변수) |
| 충분한 리소스 | 전용 GPU가 있는 16GB 이상 | 대형 모델 (예: 30B 매개변수 이상) |
다행히도 LM Studio는 시스템 리소스를 기반으로 가장 최적의 모델을 자동으로 강조 표시하여 쉽게 선택할 수 있게 도와줍니다.

2. 모델 특성 고려하기
수십억 개의 매개변수가 있는 모델도 중요하지만, 그것만이 성능이나 리소스 요구 사항을 결정하는 유일한 요소는 아닙니다. 각기 다른 모델은 서로 다른 아키텍처와 학습 데이터로 설계되어 있으며, 이는 그들의 기능에 상당한 영향을 미칩니다.
일반 용도 모델
일반적인 작업을 위한 모델이 필요하다면 다음과 같은 모델들이 좋은 선택일 수 있습니다:
코딩 특화 모델
코딩에 초점을 맞추고 있다면 코드 중심 모델이 더 적합합니다:
다중모달 모델
이미지를 처리해야 한다면 다중모달 기능이 있는 LLM을 사용해야 합니다:
여러분에게 가장 적합한 모델은 특정 사용 사례와 요구 사항에 따라 달라집니다. 확실하지 않다면 일반 목적 모델로 시작하여 필요에 따라 조정하는 것이 좋습니다.
3. 양자화(Quantization) 활용하기
LLM 설정을 최적화하는 또 다른 방법은 양자화된 모델을 사용하는 것입니다.
많은 사진 컬렉션을 가지고 있고, 각 사진이 하드 드라이브에서 많은 공간을 차지한다고 상상해보세요. 양자화는 그 사진들을 압축하여 공간을 절약하는 것과 같습니다. 약간의 이미지 품질이 손실될 수 있지만, 많은 추가 여유 공간을 얻을 수 있습니다.
양자화 수준은 종종 각 값을 표현하는 데 사용되는 비트 수로 설명됩니다. 8비트에서 4비트로 낮은 비트 값으로 이동하면 압축률이 높아지고 메모리 사용량이 줄어듭니다.
LM Studio에서는 Llama 3.3이나 Hermes 3 같은 양자화된 모델들을 찾을 수 있습니다.
이러한 모델들에 대해 여러 다운로드 옵션을 찾을 수 있습니다.

위에서 보는 것처럼, 4비트 양자화(Q4_K_M로 표시)된 모델은 8비트 버전(Q8_0으로 표시)보다 1GB 이상 작습니다.
메모리 문제가 발생하면 양자화된 모델을 사용하여 메모리 사용량을 줄이는 것을 고려해보세요.
성능 최적화 설정
LM Studio는 선택한 모델의 성능을 미세 조정할 수 있는 다양한 설정을 제공합니다.
이러한 설정을 통해 모델이 컴퓨터 리소스를 사용하고 텍스트를 생성하는 방식을 제어할 수 있으며, 속도, 메모리 사용량 또는 특정 작업 요구사항에 맞게 최적화할 수 있습니다.
이러한 설정은 각 다운로드된 모델 내의 My Models 섹션에서 찾을 수 있습니다.

주요 옵션들을 살펴보겠습니다:
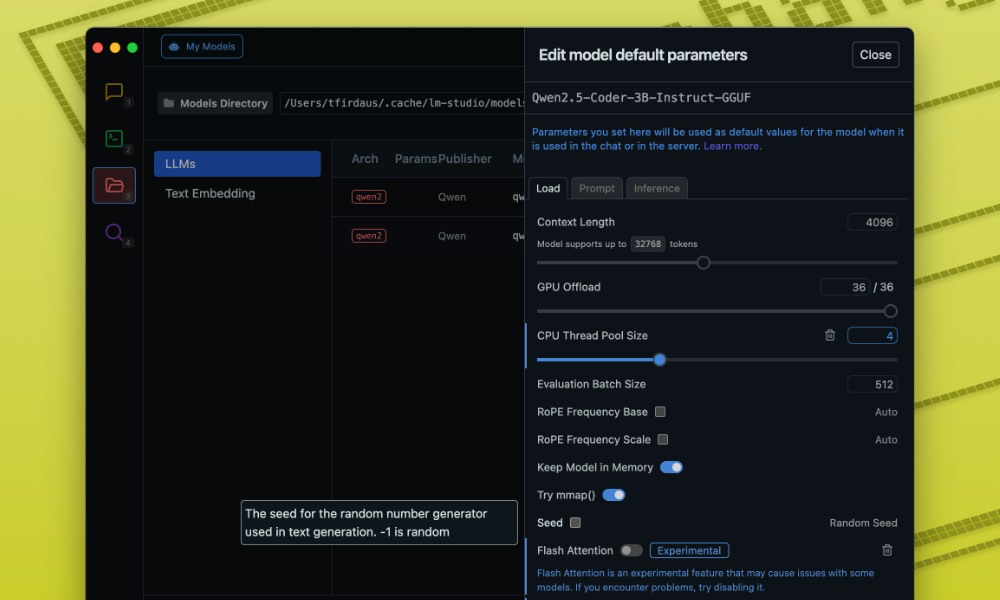
컨텍스트 길이(Context Length)

이 설정은 모델이 응답을 생성할 때 “기억”하는 이전 대화의 양을 결정합니다. 더 긴 컨텍스트 길이를 사용하면 모델이 더 오랜 대화에서도 일관성을 유지할 수 있지만, 더 많은 메모리가 필요합니다.
더 짧은 작업을 수행하거나 RAM이 제한적인 경우, 컨텍스트 길이를 줄이면 성능이 향상될 수 있습니다.
GPU 오프로드(GPU Offload)

이 설정을 통해 추론을 가속화하기 위해 GPU의 성능을 활용할 수 있습니다. 전용 그래픽 카드가 있다면 GPU 오프로드를 활성화하여 성능을 크게 향상시킬 수 있습니다.
CPU 스레드 풀 크기(CPU Thread Pool Size)

이 설정은 처리에 활용되는 CPU 코어의 수를 결정합니다. 스레드 풀 크기를 늘리면 특히 멀티코어 프로세서에서 성능이 향상될 수 있습니다.
시스템에 맞는 최적의 구성을 찾기 위해 실험해볼 수 있습니다.
K 캐시/V 캐시 양자화 유형(K Cache/V Cache Quantization Type)

이러한 설정은 모델의 키 및 값 캐시가 어떻게 양자화되는지 결정합니다. 모델 양자화와 유사하게, 캐시 양자화는 메모리 사용량을 줄이지만 정확도에 약간 영향을 미칠 수 있습니다.
성능과 정확도 사이의 최적의 균형을 찾기 위해 다양한 양자화 수준을 실험해볼 수 있습니다.
응답 길이 제한(Limit Response Length)

이 설정은 모델이 단일 응답에서 생성할 수 있는 최대 토큰 수(대략 단어나 하위 단어 단위와 같음)를 제어합니다. 이는 주로 처리 시간과 리소스 사용 측면에서 성능에 직접적인 영향을 미칩니다.
응답 길이를 제한하는 주요 단점은 모델의 응답이 지정된 제한을 초과하면 잘리거나 불완전할 수 있다는 것입니다. 상세하거나 포괄적인 답변이 필요한 경우 문제가 될 수 있습니다.
로컬 LLM, 데스크톱 AI의 새로운 시대
클라우드 기반 AI 서비스가 대세인 시대에 로컬 LLM은 개인화된 AI 경험을 제공하는 새로운 패러다임을 제시합니다. LM Studio와 같은 도구는 이러한 전환을 더 쉽게 만들어주고 있습니다. 여러 가지 장점들을 살펴보겠습니다.
개인정보 보호의 강화
로컬 LLM을 사용하는 가장 큰 장점 중 하나는 데이터 프라이버시입니다. 모든 프롬프트와 대화가 여러분의 컴퓨터에서만 처리되므로 민감한 정보가 외부 서버로 전송되지 않습니다. 이는 개인 정보나 기업 기밀을 다룰 때 특히 중요합니다.
비용 효율성
대부분의 클라우드 AI 서비스는 사용량에 따라 요금을 청구합니다. 로컬 LLM을 사용하면 초기 하드웨어 비용 외에 추가 비용이 없으므로 장기적으로 더 경제적일 수 있습니다. 특히 AI를 자주 사용하는 경우 그 차이는 더욱 두드러집니다.
오프라인 접근성
인터넷 연결이 불안정하거나 제한된 환경에서도 로컬 LLM은 완벽하게 작동합니다. 이는 원격 지역, 여행 중, 또는 네트워크 제한이 있는 환경에서 특히 유용합니다.
내 컴퓨터에 맞는 최적의 설정 찾기
로컬 LLM을 효과적으로 사용하기 위해서는 자신의 컴퓨터 사양과 사용 목적에 맞는 최적의 설정을 찾는 것이 중요합니다. 다음은 효과적인 설정을 위한 몇 가지 팁입니다.
하드웨어 용량 파악하기
먼저 자신의 컴퓨터가 가진 RAM 용량, GPU 성능, CPU 코어 수를 정확히 파악하는 것이 중요합니다. 이러한 정보를 바탕으로 어떤 크기의 모델을 실행할 수 있을지 판단할 수 있습니다.
점진적 접근법 시도하기
처음부터 가장 큰 모델을 실행하려고 하기보다는, 작은 모델로 시작하여 점진적으로 크기를 늘려가는 것이 좋습니다. 이를 통해 시스템의 한계를 파악하고 각 모델의 성능을 비교할 수 있습니다.
응용 프로그램 최적화
LLM을 실행할 때는 가능한 다른 리소스 집약적인 응용 프로그램을 닫아두는 것이 좋습니다. 웹 브라우저의 여러 탭, 비디오 편집 소프트웨어, 게임 등은 상당한 시스템 리소스를 소비할 수 있습니다.
정기적인 모니터링 수행
작업 관리자나 시스템 모니터링 도구를 통해 LLM 실행 중 메모리 사용량, CPU 및 GPU 사용률을 모니터링하는 것이 좋습니다. 이를 통해 병목 현상을 식별하고 설정을 조정할 수 있습니다.
마치며
로컬 환경에서 대형 언어 모델을 실행하는 것은 텍스트 생성, 질문 답변, 심지어 코딩 지원까지 다양한 작업에 강력한 도구를 제공합니다. 하지만 제한된 리소스로 인해, 신중한 모델 선택과 성능 조정을 통한 LLM 설정 최적화가 필수적입니다.
LM Studio를 통해 적절한 모델을 선택하고 설정을 미세 조정함으로써, 여러분의 시스템에서 효율적이고 효과적인 로컬 LLM 운영을 보장할 수 있습니다. 이제 여러분만의 AI 비서를 개인 컴퓨터에서 사용하면서, 프라이버시를 유지하고 비용을 절약해보세요.
참고자료: Running Large Language Models (LLMs) Locally with LM Studio
답글 남기기