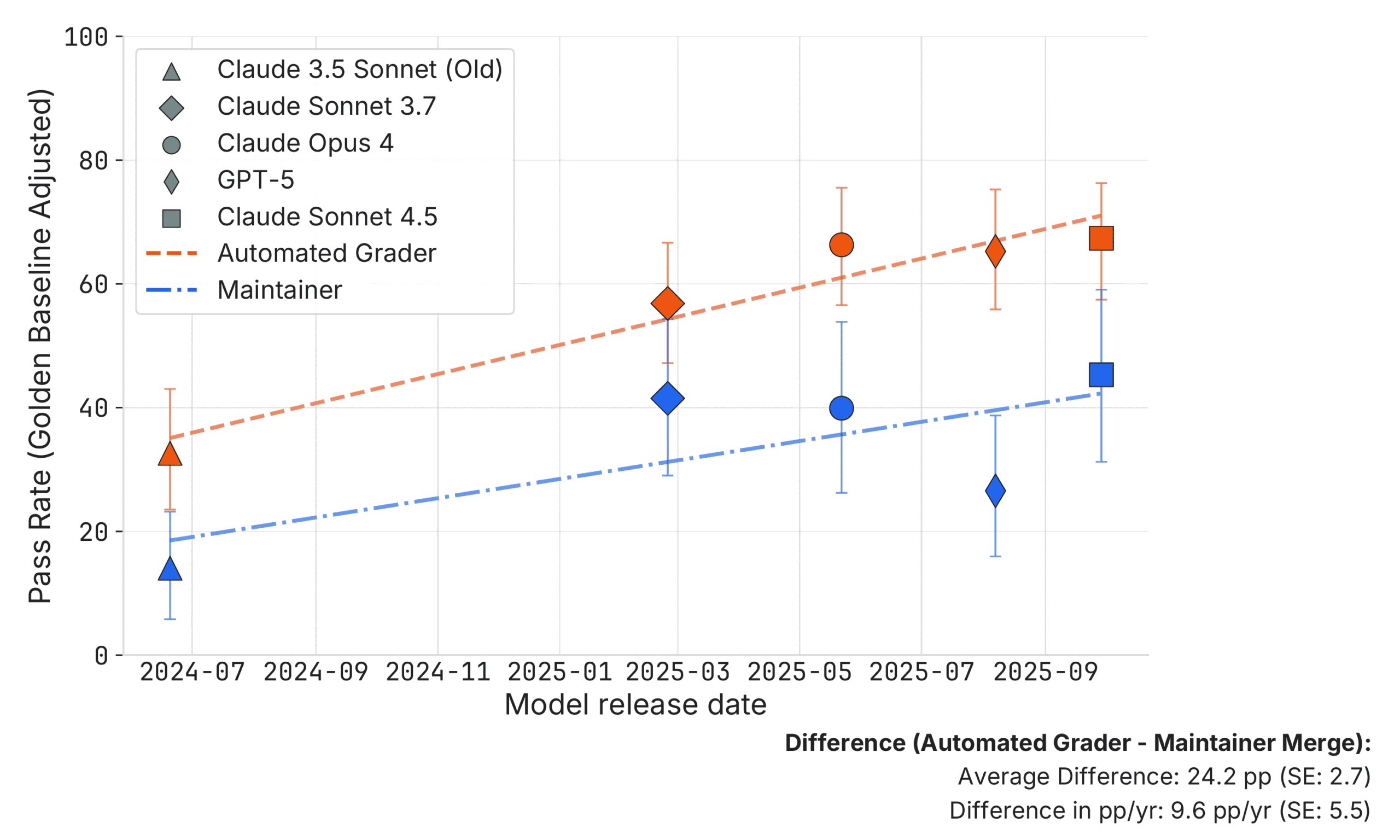
AI가 업계 표준 코딩 테스트를 통과했다는 게 실제로 어떤 의미일까요? AI 안전 연구 기관 METR이 그 질문에 직접 답하는 실험을 진행했습니다. 자동화 채점기를 통과한 AI 코드를, 실제 저장소를 관리하는 현직 개발자들이 직접 심사하게 했더니 절반 가까이가 탈락했습니다.

METR 연구팀은 scikit-learn, Sphinx, pytest 세 오픈소스 프로젝트의 현직 관리자 4명에게 AI가 생성한 풀 리퀘스트(PR) 296개를 검토하게 했습니다. 대상 모델은 Claude 3.5 Sonnet부터 Claude 4.5 Sonnet, GPT-5까지 총 5종이었고, 관리자들은 어느 코드가 AI가 쓴 것인지 알지 못한 채 심사했습니다. 핵심 발견은 하나입니다. 자동 채점기 점수가 관리자 승인률보다 평균 24%포인트 높았습니다.
출처: Many SWE-bench-Passing PRs Would Not Be Merged into Main – METR
테스트를 통과해도 코드가 ‘좋은’ 건 아니다
SWE-bench Verified는 AI 코딩 에이전트 평가의 사실상 표준으로 쓰이는 벤치마크입니다. 실제 오픈소스 프로젝트의 버그나 이슈를 AI가 해결할 수 있는지 측정하는데, 성공 기준은 자동화된 단위 테스트 통과 여부입니다. Anthropic과 OpenAI가 신규 모델 발표 시 자주 인용하는 수치이기도 하죠.
문제는 테스트 통과와 ‘실제로 쓸 수 있는 코드’가 다른 개념이라는 점입니다. 테스트는 지정된 기능이 작동하는지만 확인합니다. 코드 스타일이 저장소 규칙에 맞는지, 관련 없는 코드를 건드려 다른 기능을 망가뜨리진 않는지, 문제를 실제로 올바르게 해결했는지는 테스트 결과에 반영되지 않습니다.
METR이 관리자들에게 거절 이유를 물었을 때 나온 답변이 이를 보여줍니다. 단순 코드 품질 문제(스타일, 저장소 규칙 불일치)만이 아니라, 핵심 기능 오류 — 즉 테스트는 통과했지만 실제 문제를 제대로 해결하지 못한 경우 — 도 상당수를 차지했습니다.
모델이 발전해도 격차는 유지된다
연구팀은 모델 세대별 변화도 추적했습니다.
- Claude 3.5 → 3.7 Sonnet: 자동 채점 점수가 크게 올랐지만, 관리자들이 핵심 기능 오류를 지적하는 경우도 함께 늘었습니다.
- Claude 3.7 Sonnet → Claude 4 Opus: 테스트 자체를 실패하는 경우는 줄었지만, 코드 품질 문제로 거절되는 비중이 높아졌습니다.
- Claude 4 Opus → Claude 4.5 Sonnet: 주로 코드 품질이 개선되는 방향으로 발전했습니다.
벤치마크 점수가 올라가는 방식과 실제 코드 품질이 좋아지는 방식이 항상 일치하지 않는다는 걸 보여주는 흐름입니다.
연구팀은 ‘시간 지평선(time horizon)’ 분석도 진행했습니다. 이 지표는 사람이 완료하는 데 걸리는 시간을 기준으로, 그 정도 난이도의 작업을 모델이 50% 확률로 해결할 수 있는지를 나타냅니다. 난이도의 척도인 셈입니다. Claude Sonnet 4.5의 경우 자동 채점 기준으로는 사람 기준 약 50분짜리 난이도까지 절반쯤 처리할 수 있지만, 관리자 기준으로는 8분짜리 난이도 수준에 그쳤습니다. 같은 모델을 어떤 잣대로 재느냐에 따라 능력 추정치가 6배 이상 달라지는 셈입니다.
벤치마크가 틀린 게 아니라, 해석이 문제다
연구팀은 몇 가지 중요한 전제를 스스로 짚습니다. 이 실험에서 AI는 코드를 한 번만 제출할 수 있었지만, 실제 개발 현장에서는 코드 리뷰 피드백을 받고 수정할 기회가 있습니다. 관리자들도 CI 도구나 린터 없이 심사했고, 테스트 작성 요구 사항도 AI에게 유리하게 완화했습니다. 즉, 이 연구는 AI의 최대 능력에 대한 측정이 아니라, 벤치마크 점수를 그대로 현실 성능으로 해석할 때 생기는 괴리를 보여주는 것입니다.
METR는 SWE-bench 외에도 다른 벤치마크들(GDPval-AA, UpBench 등)에서 비슷한 현상이 나타날 것으로 보고 있습니다. 논문에는 모델별 상세 거절 사례와 저장소별 세부 분석, 통계적 강건성 검증 결과도 수록되어 있습니다.
참고자료: Are LLMs not getting better? – Entropic Thoughts
답글 남기기