최첨단 LLM을 만드는 데 수억 달러가 필요하다는 게 업계의 상식이었습니다. 그런데 2025년 1월, DeepSeek이라는 중국 스타트업이 단 5백만 달러로 GPT-4급 성능을 달성했다고 발표하면서 모든 걸 뒤집어놓았죠.

LLM 연구자 Sebastian Raschka가 자신의 블로그에 2025년 LLM 분야의 주요 발전과 2026년 전망을 정리한 연례 리뷰를 발표했습니다. 이 글은 단순한 스케일링에서 추론 능력 개발로 패러다임이 전환된 한 해를 되돌아보며, RLVR이라는 새로운 훈련 방식이 어떻게 게임 체인저가 되었는지 분석합니다.
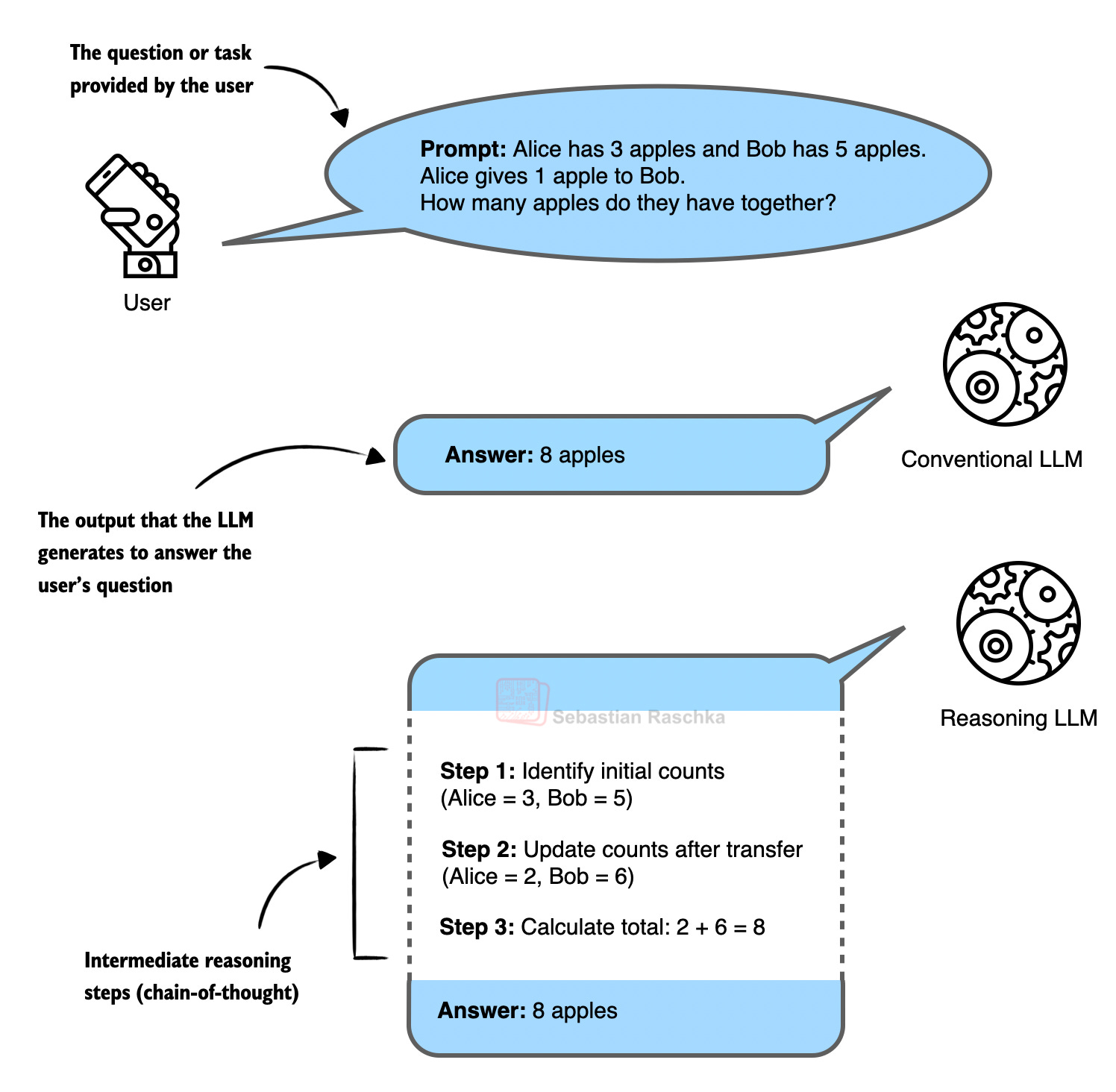
출처: The State Of LLMs 2025: Progress, Problems, and Predictions – Sebastian Raschka
RLVR+GRPO: 추론 모델의 핵심 기술
2025년은 “추론의 해”였습니다. DeepSeek R1이 공개한 RLVR(Reinforcement Learning with Verifiable Rewards)과 GRPO 알고리즘 덕분이죠.
기존 방식은 사람이 일일이 정답을 작성하거나 선호도를 표시해야 했어요. 비용도 많이 들고 확장성도 떨어졌죠. 하지만 RLVR은 다릅니다. 수학 문제나 코딩처럼 정답을 기계적으로 검증할 수 있는 영역에서는 사람 손을 거치지 않고도 대규모로 학습시킬 수 있거든요. 코드를 실행해보면 작동하는지 바로 알 수 있고, 수식 계산도 맞는지 즉시 확인 가능하니까요.
결과는 놀라웠습니다. 여러 추론 모델이 이미 2025년에 수학 올림피아드 금메달 수준에 도달했어요. Raschka는 이게 2026년쯤 일어날 거라 예상했는데 1년이나 빨랐다고 하네요. OpenAI, Gemini Deep Think, 그리고 오픈소스인 DeepSeekMath-V2가 모두 이 수준을 달성했습니다.
Raschka는 2026년에 RLVR이 수학과 코딩을 넘어 화학, 생물학 같은 다른 영역으로 확장될 거라 전망합니다. 그리고 추론 과정 자체를 평가하는 방식도 발전할 거라고 예측하고 있어요.
벤치마크 점수의 함정: “벤치맥싱”
2025년을 한 단어로 표현하라면 “벤치맥싱”이라고 Raschka는 말합니다. 벤치마크 점수를 올리는 것 자체가 목적이 돼버린 현상이죠.
Llama 4가 대표적 사례입니다. 벤치마크에서는 압도적인 점수를 받았지만, 실제로 써보니 기대에 못 미쳤어요. 테스트 데이터가 공개돼 있다 보니 의도적이든 아니든 훈련 과정에서 오염되는 거죠. 예전에는 점수가 부풀려져도 모델 간 순위는 유지됐는데, 지금은 그것마저 무너졌습니다.
그렇다고 벤치마크가 무용지물은 아니에요. “최소 기준”으로는 여전히 유효하거든요. 특정 벤치마크에서 일정 점수 이하면 좋은 모델이 아니라는 건 알 수 있죠. 다만 기준점을 넘은 모델들 사이의 우열은 점수만으론 판단하기 어렵다는 겁니다.
Raschka는 실제로 써보고 새로운 벤치마크를 계속 만드는 것 외엔 해결책이 없다고 말해요. LLM은 번역, 요약, 코딩, 수학 등 워낙 다양한 일을 하다 보니 단일 지표로 평가하기가 본질적으로 어렵다는 거죠.
LLM은 대체재가 아니라 증폭기
“LLM이 개발자를 대체할까?”라는 질문에 Raschka는 명확한 입장을 밝힙니다. 대체가 아니라 “슈퍼파워”를 주는 도구라는 거예요.
그는 여전히 중요한 코드는 직접 짭니다. LLM 훈련 스크립트 같은 핵심 로직은 자기가 이해하고 검증해야 하니까요. 대신 명령줄 인터페이스 추가하기 같은 반복적인 작업은 LLM에 맡기죠. 자신의 전문성이 필요한 영역과 자동화해도 되는 영역을 구분하는 게 핵심입니다.
흥미로운 건 번아웃에 대한 지적이에요. LLM이 모든 걸 다 해주고 사람은 감독만 하면, 일이 공허하게 느껴질 수 있다는 거죠. 어려운 문제를 끙끙대다 해결했을 때의 만족감은 LLM이 원샷으로 해결해줄 때와는 질적으로 다르거든요.
체스 비유가 인상적입니다. AI가 인간 체스 챔피언을 이긴 지 수십 년이 지났지만, 인간 체스는 여전히 번창하고 있어요. 오히려 프로 기사들이 AI로 새로운 전략을 탐구하면서 게임이 더 풍성해졌죠. LLM도 마찬가지입니다. 사고를 완전히 아웃소싱하는 게 아니라 파트너로 활용할 때 최고의 결과가 나온다는 거예요.
진짜 경쟁력은 전문 데이터에 있다
일반적인 코딩, 지식 답변, 글쓰기 능력은 계속 좋아지고 있습니다. 하지만 언젠가는 정체기가 올 거예요. Raschka는 진짜 경쟁력은 도메인별 전문 데이터에서 나온다고 봅니다.
금융, 바이오테크, 의료 같은 분야의 기업들은 OpenAI나 Anthropic에 데이터를 팔지 않고 있어요. 왜냐하면 그 데이터가 바로 자신들의 경쟁력이거든요. Raschka는 앞으로 이런 기업들이 직접 LLM 개발자를 고용해서 자체 모델을 만들 거라 예측합니다.
다행히 처음부터 끝까지 다 훈련할 필요는 없어요. DeepSeek V3.2, Kimi K2, GLM 4.7 같은 오픈소스 모델을 가져다가 자기 데이터로 추가 학습시키면 되거든요. LLM 개발이 점점 민주화되고 있다는 뜻이죠.
2026년에는 도구 사용 능력과 추론 시점 스케일링(답변 생성할 때 더 많은 연산을 투입하는 방식)이 중요해질 거라고 합니다. 그리고 2027년쯤엔 지속 학습(처음부터 재훈련하지 않고 새 지식 추가하기)이 핫토픽이 될 거라고 예측하네요.
참고자료:
- DeepSeek R1 논문
- DeepSeek V3 논문
- Understanding Reasoning LLMs – Sebastian Raschka
- The State of Reinforcement Learning for LLM Reasoning – Sebastian Raschka
답글 남기기