전통적인 소프트웨어에서 버그가 발생하면 개발자는 코드를 열어봅니다. 기능이 어떻게 작동하는지 이해하고 싶을 때도, 성능을 개선하고 싶을 때도 마찬가지죠. 코드가 곧 진실의 원천이었습니다. 하지만 AI 에이전트에서는 이 방식이 더 이상 통하지 않습니다.

LangChain이 발표한 글에서는 AI 에이전트 시대에 앱의 작동 방식을 이해하는 방법이 근본적으로 바뀌고 있다고 주장합니다. 코드 대신 ‘트레이스(실행 기록)’가 앱을 설명하는 새로운 문서가 되었다는 것이죠. 실제 의사결정이 런타임에 모델 내부에서 일어나기 때문에, 개발자가 코드만 봐서는 앱이 무엇을 할지 알 수 없다는 이야기입니다.
출처: In software, the code documents the app. In AI, the traces do. – LangChain Blog
코드는 이제 ‘비계’일 뿐
전통적인 소프트웨어에서 사용자가 폼을 제출하면 어떻게 되는지 알고 싶다면, handleSubmit() 함수를 열어보면 됩니다. 입력값 검증, 인증 확인, API 호출, 에러 처리 등 모든 의사결정 로직이 코드에 명확히 적혀 있죠. 같은 입력이면 같은 코드 경로를 거쳐 같은 결과가 나옵니다.
하지만 AI 에이전트의 코드는 이렇게 생겼습니다:
agent = Agent(
model="gpt-4",
tools=[search_tool, analysis_tool, visualization_tool],
system_prompt="You are a helpful data analyst..."
)
result = agent.run(user_query)어떤 모델을 쓸지, 어떤 도구를 줄지, 무슨 지시를 내릴지만 정의했을 뿐입니다. 실제 의사결정 로직, 즉 언제 어떤 도구를 호출할지, 문제를 어떻게 추론할지, 언제 멈출지 같은 결정은 모두 런타임에 모델 내부에서 일어납니다. 코드는 그저 LLM 호출을 조율하는 비계에 불과하죠.
개발자는 여전히 도구 호출이 잘 작동하는지, 파싱이 제대로 되는지 같은 오케스트레이션 코드를 디버깅할 수 있습니다. 하지만 에이전트가 좋은 결정을 내리는지, 효과적으로 추론하는지 같은 ‘지능’ 부분은 디버깅할 수 없어요. 그 로직은 코드베이스가 아니라 모델 안에 있으니까요.
트레이스가 새로운 문서가 되다
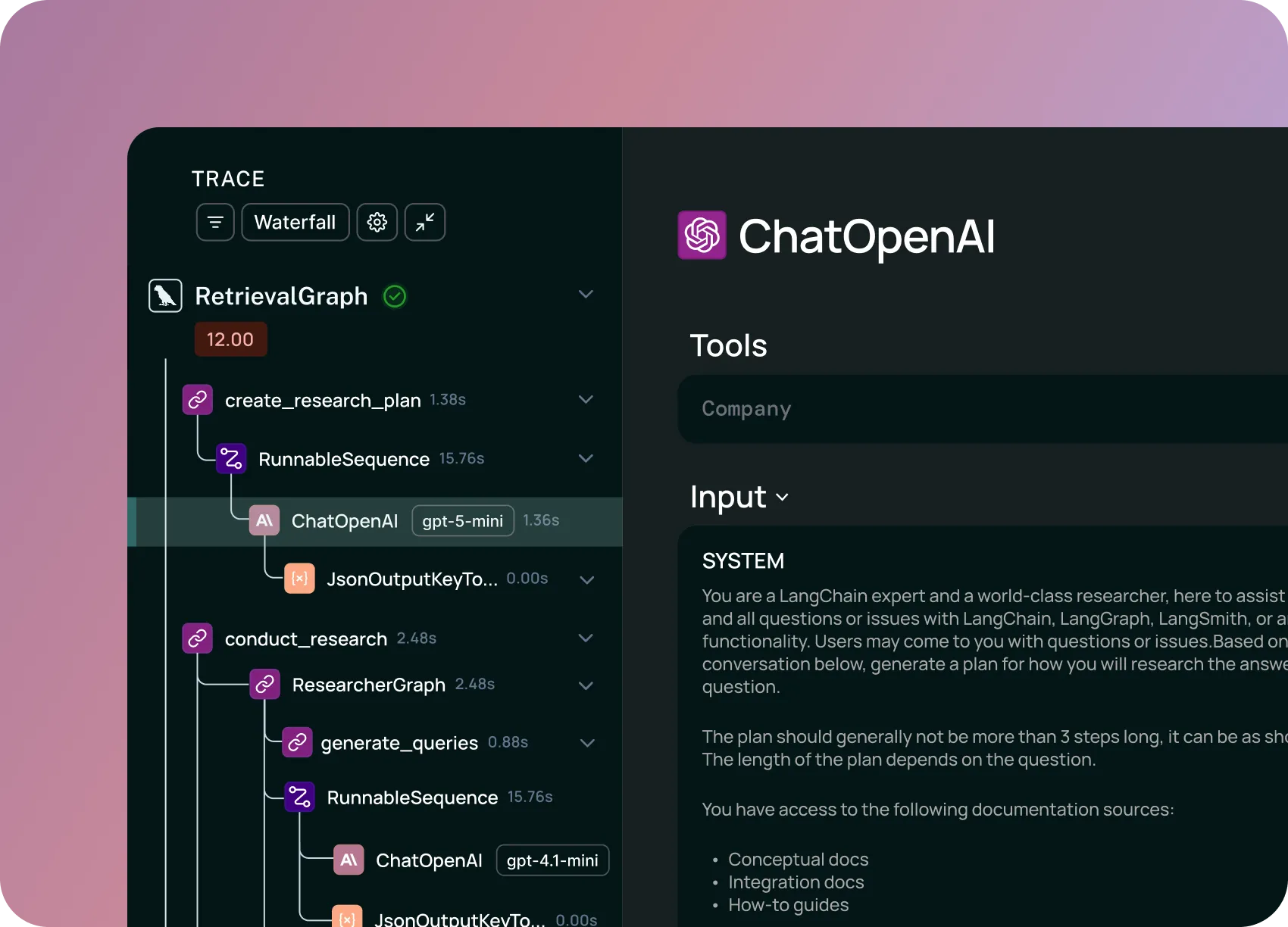
그렇다면 실제 동작 방식은 어디에 있을까요? 바로 트레이스에 있습니다.
트레이스는 에이전트가 밟은 단계들의 순서를 기록한 것입니다. 각 단계에서의 추론, 어떤 도구가 왜 호출됐는지, 결과와 소요 시간 등 앱의 실제 로직을 문서화하죠. 이것이 의미하는 바는 명확합니다. 소프트웨어 세계에서 코드로 하던 작업들을 이제 에이전트 세계에서는 트레이스로 해야 한다는 것입니다.
전통적인 소프트웨어에서 두 실행이 다른 결과를 내면, 입력이 다르거나 코드가 다르다고 가정합니다. 하지만 AI 에이전트는 같은 입력과 같은 코드로도 다른 결과를 낼 수 있어요. 다른 도구를 호출하고, 다른 추론 체인을 거치고, 다른 결과에 도달하죠.
무슨 일이 일어났는지 이해하는 유일한 방법은 트레이스를 보는 것입니다. 작업 A는 성공했는데 B는 왜 실패했을까요? 트레이스를 비교해보세요. 프롬프트 변경이 추론을 개선했나요? 변경 전후 트레이스를 비교하면 됩니다. 에이전트가 같은 실수를 반복하는 이유는? 여러 트레이스에서 패턴을 찾아보세요.
모든 개발 프로세스가 바뀐다
로직의 진실 원천이 코드에서 트레이스로 이동하면 다른 모든 것도 따라 바뀝니다.
디버깅은 트레이스 분석이 됩니다. 사용자가 “에이전트가 실패했어요”라고 보고하면, 코드를 열어 버그를 찾는 게 아니라 트레이스를 열어 추론이 어디서 잘못됐는지 봅니다. 에이전트가 작업을 오해했나요? 잘못된 도구를 호출했나요? 루프에 갇혔나요? ‘버그’는 코드의 논리 오류가 아니라 에이전트가 실제로 한 행동의 추론 오류입니다.
예를 들어, 에이전트가 같은 실패한 API 호출을 다섯 번 재시도한 뒤 포기하는 경우를 생각해보세요. 재시도 로직 자체는 코드에 잘 작동하고 있습니다. 문제는 에이전트가 에러 메시지로부터 학습하지 못한다는 것이죠. 이건 트레이스에서만 보입니다. 같은 도구 호출, 같은 파라미터, 같은 실패가 반복되는 모습이요.
테스트는 평가 중심이 됩니다. 로직의 진실이 트레이스에 있으니, 그 트레이스를 테스트해야 합니다. 에이전트가 실행되면서 트레이스를 캡처해 테스트 데이터셋에 추가하는 파이프라인이 필요하죠. 게다가 에이전트는 비결정적이기 때문에, 배포 전 테스트만으로는 부족합니다. 프로덕션에서도 지속적으로 평가해 품질 저하나 드리프트를 감지해야 해요.
모니터링은 가동시간에서 품질로 이동합니다. 에이전트는 에러 없이 ‘작동’하면서도 끔찍하게 수행할 수 있습니다. 잘못된 작업을 성공하거나, 10배 비용으로 비효율적으로 성공하거나, 맞지만 도움 안 되는 답변을 줄 수 있죠. 시스템 상태가 아니라 의사결정의 품질을 모니터링해야 합니다. 작업 성공률, 추론 품질, 도구 사용 효율성 같은 것들이요. 트레이스를 샘플링하고 분석하지 않고는 품질을 모니터링할 수 없습니다.
AI 시스템 개발의 패러다임 전환
이 변화는 단순히 새로운 도구를 쓰는 문제가 아닙니다. AI 에이전트를 개발하고 운영하는 방식 자체가 근본적으로 달라지는 것이죠.
전통적인 소프트웨어 개발자는 코드를 읽고 쓰고 리뷰하는 데 대부분의 시간을 보냅니다. 하지만 AI 에이전트 개발자는 트레이스를 분석하고, 추론 패턴을 파악하고, 모델의 결정을 이해하는 데 시간을 써야 합니다. 협업도 GitHub 코드 리뷰에서 트레이스 공유와 의사결정 지점 논의로 옮겨가고 있어요.
이는 좋은 관찰 가능성(observability) 도구 없이는 AI 에이전트를 제대로 개발할 수 없다는 의미입니다. 트레이스를 검색하고 필터링하고 비교할 수 있어야 하고, 전체 추론 체인을 볼 수 있어야 하며, 시간이 지나면서 품질을 모니터링할 수 있어야 합니다. AI 에이전트가 더 많은 의사결정을 담당할수록, 코드만으로는 시스템을 이해할 수 없는 시대가 오고 있습니다.
답글 남기기