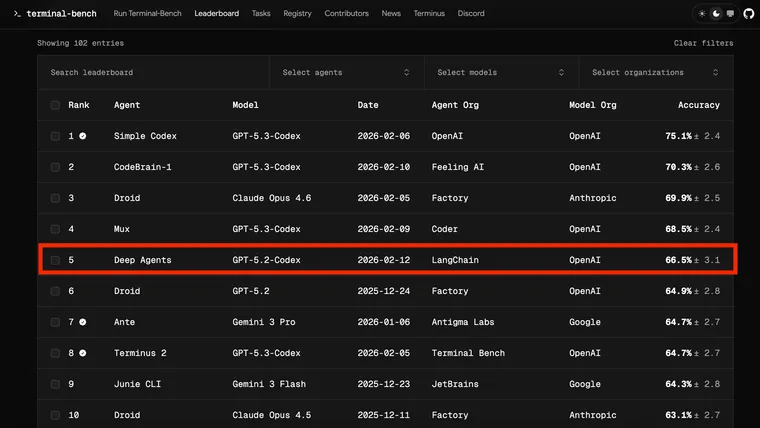
AI 에이전트 성능을 올리려면 더 좋은 모델로 바꿔야 할까요? LangChain은 모델을 그대로 두고 주변 시스템만 손봤더니 벤치마크 순위가 30위권 밖에서 Top 5로 올라갔다고 밝혔습니다.

LangChain이 자사 코딩 에이전트 deepagents-cli를 코딩 에이전트 벤치마크인 Terminal Bench 2.0에서 52.8%에서 66.5%로 13.7점 끌어올린 과정을 공개했습니다. 모델(gpt-5.2-codex)은 고정하고 하네스(harness), 즉 모델을 감싸는 시스템 구조만 바꾼 결과입니다.
출처: Improving Deep Agents with harness engineering – LangChain Blog
하네스 엔지니어링이란
하네스는 모델의 뾰족한 지능을 우리가 원하는 방향으로 다듬는 틀입니다. 시스템 프롬프트, 툴 선택, 실행 흐름 등 모델 바깥을 구성하는 모든 요소가 여기에 해당합니다.
LangChain은 하네스를 바꾸는 기준을 세 가지로 압축했습니다. 시스템 프롬프트, 툴, 미들웨어입니다. 그리고 매 실험마다 LangSmith에 저장된 에이전트 트레이스를 분석해 어디서 실패했는지 파악하고, 그 결과를 다음 하네스 변경에 반영하는 루프를 돌렸습니다. 일종의 머신러닝 부스팅과 비슷하게, 이전 실패에 집중해 개선하는 방식입니다.
성능을 실제로 올린 세 가지 변화
자기 검증 루프 강제화
가장 흔한 실패 패턴은 단순했습니다. 에이전트가 코드를 작성하고, 자기 코드를 다시 읽고, “괜찮아 보이네”라고 판단한 뒤 멈추는 것이었습니다. 테스트를 실행하지 않는 거죠.
LangChain은 시스템 프롬프트에 문제 해결 절차를 명시했습니다. ① 계획·탐색 → ② 구현 → ③ 테스트 실행 및 검증 → ④ 수정. 여기서 그치지 않고 PreCompletionChecklistMiddleware를 추가해, 에이전트가 종료하려 할 때 자동으로 검증 패스를 다시 수행하도록 가로챘습니다. 모델의 자연스러운 경향을 시스템 수준에서 교정한 셈입니다.
환경 맥락 주입
에이전트는 자신이 어떤 환경에서 동작하는지 스스로 파악해야 할 때 오류를 자주 냅니다. LangChain은 에이전트 시작 시점에 LocalContextMiddleware를 실행해 현재 디렉토리 구조, Python 설치 경로 같은 환경 정보를 자동으로 주입했습니다. 또 Task 명세에 파일 경로가 있으면 그것을 정확히 따르도록, 코드가 자동 채점 단계에서도 동작하도록 프롬프트로 안내했습니다.
에이전트가 환경·제약·평가 기준을 많이 알수록 더 자율적으로 작업을 완수한다는 게 LangChain의 결론입니다.
추론 예산의 ‘샌드위치’ 배분

gpt-5.2-codex는 low, medium, high, xhigh 네 가지 추론 모드를 지원합니다. 추론을 많이 쓸수록 토큰과 시간이 늘어나는데, Terminal Bench에는 엄격한 시간 제한이 있습니다. xhigh만 계속 쓰면 53.9%에 그쳤고, 무작정 추론을 아끼면 계획 단계에서 오류가 났습니다.
LangChain이 찾은 균형점은 “reasoning sandwich”입니다. 계획 단계에는 xhigh, 구현 단계에는 high, 최종 검증에는 다시 xhigh를 씁니다. 추론이 가장 필요한 구간에 집중 투자하는 방식입니다.
모델보다 하네스가 먼저일 수 있다
이번 실험이 흥미로운 이유는 “더 좋은 모델”이 항상 정답이 아닐 수 있음을 수치로 보여줬기 때문입니다. Claude Opus 4.6을 동일 Task에 돌렸을 때 59.6%로 경쟁력 있는 점수가 나왔지만, Codex와 같은 수준의 하네스 개선 루프를 돌리지 않았기 때문에 최종 점수에서 뒤처졌다고 LangChain은 설명합니다.
LangChain은 트레이스 데이터셋을 공개했고, deepagents는 Python과 JavaScript 모두 오픈소스로 제공됩니다. 앞으로는 멀티 모델 시스템(Codex·Gemini·Claude 조합)과 에이전트가 스스로 개선하는 메모리 구조 연구도 이어갈 예정이라고 밝혔습니다.
참고자료:
답글 남기기