추론최적화
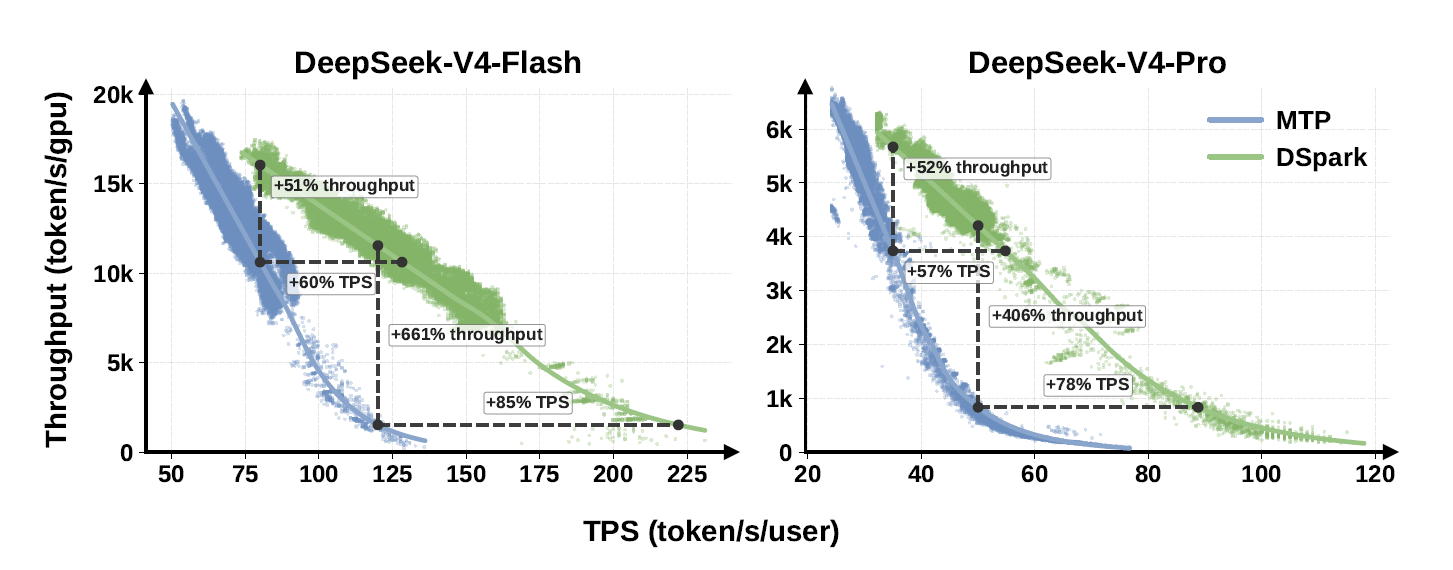
DeepSeek DSpark, 하드웨어 안 바꾸고 AI 응답속도 85% 올린 방법
DeepSeek가 공개한 추론 최적화 프레임워크 DSpark, 하드웨어 교체 없이 응답 속도 최대 85% 개선. 오픈소스 코드까지 공개한 이유를 짚어봅니다.
Written by
손실 없이 KV 캐시를 4배 줄이는 방법, Speculative KV Coding
KV 캐시를 손실 없이 최대 4배 압축하는 Speculative KV Coding 연구 소개. FP8 양자화와 조합하면 원본 대비 총 8배 압축, Qwen3 실험 결과 포함.
Written by

Gemma 4 추론 속도 3배 높인 MTP 드래프터, 작동 원리는
Google이 Gemma 4에 MTP 드래프터를 추가해 품질 손실 없이 최대 3배 추론 속도를 달성했습니다. Speculative Decoding의 작동 원리와 개발자에게 갖는 의미를 설명합니다.
Written by

Ollama 0.19, MLX 탑재로 Mac에서 AI 추론 속도 2배 빨라졌다
Ollama 0.19가 Apple MLX 프레임워크를 탑재해 Mac에서 AI 추론 속도를 최대 2배 향상. NVFP4 지원과 캐시 개선도 포함한 주요 업데이트를 소개합니다.
Written by
Anthropic vs OpenAI 빠른 추론, 같은 듯 전혀 다른 두 가지 방법
Anthropic과 OpenAI가 동시에 발표한 fast mode, 사실 작동 원리가 완전히 다릅니다. 배칭 조정 vs 웨이퍼 크기 칩, 두 가지 방식의 차이와 트레이드오프를 분석합니다.
Written by

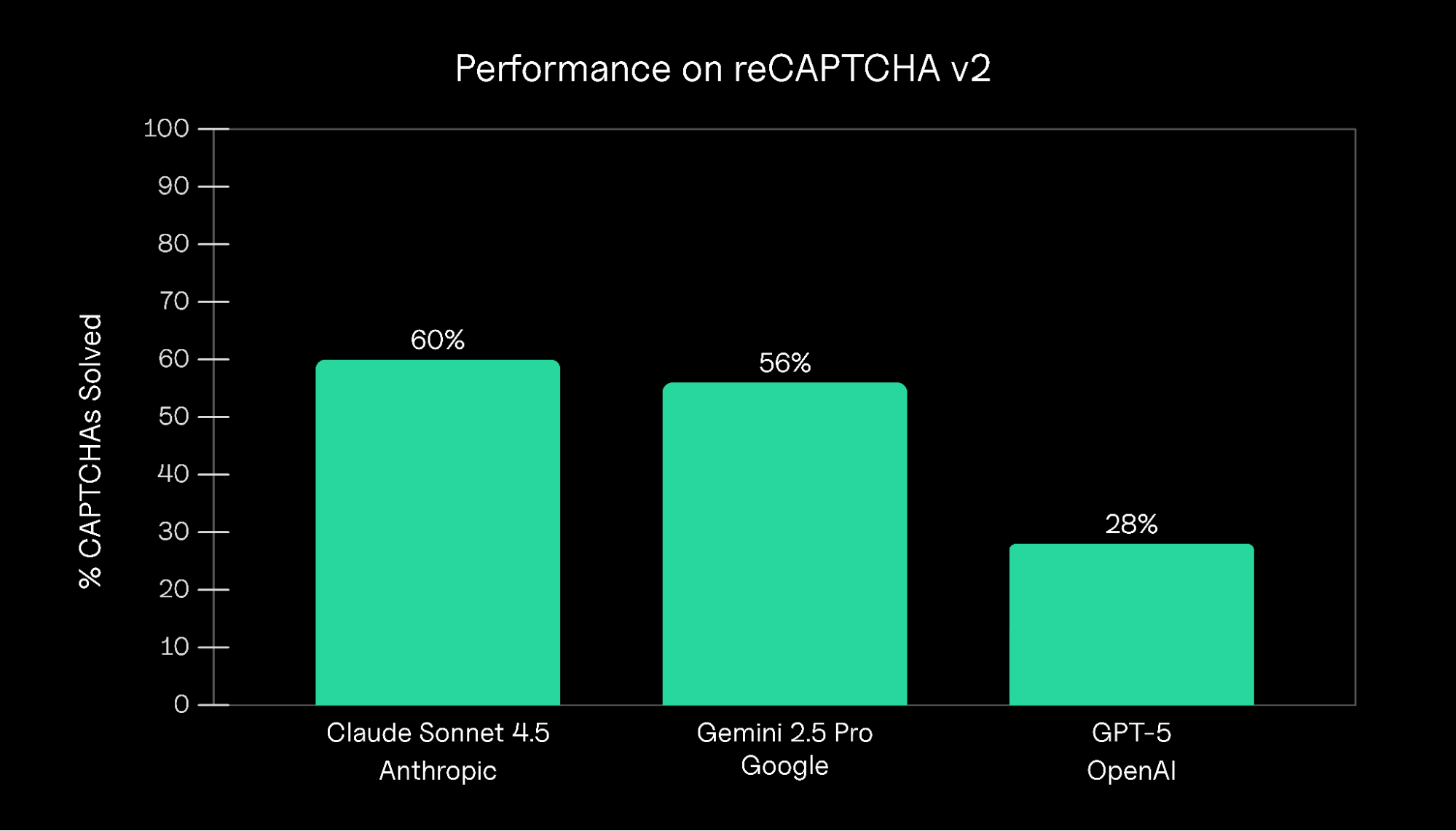
CAPTCHA의 종말?: Claude 60% vs GPT-5 28%, 과도한 추론이 실패를 부른다
최신 AI 모델들의 CAPTCHA 풀이 능력 벤치마크. Claude 60% vs GPT-5 28%, 과도한 추론이 오히려 실패를 초래하는 역설을 분석합니다.
Written by
언어 모델 배포 최적화 완전 가이드: 개발자를 위한 실전 기법과 코드 예제
개발자를 위한 언어 모델 크기 최적화 완전 가이드입니다. 지식 증류, 프루닝, 양자화, LoRA 등 핵심 기법들을 실제 코드 예제와 함께 상세히 설명하고, 메모리 사용량을 20-50% 줄이고 추론 속도를 2-5배 향상시키는 실무 적용 방법을 제시합니다.
Written by
